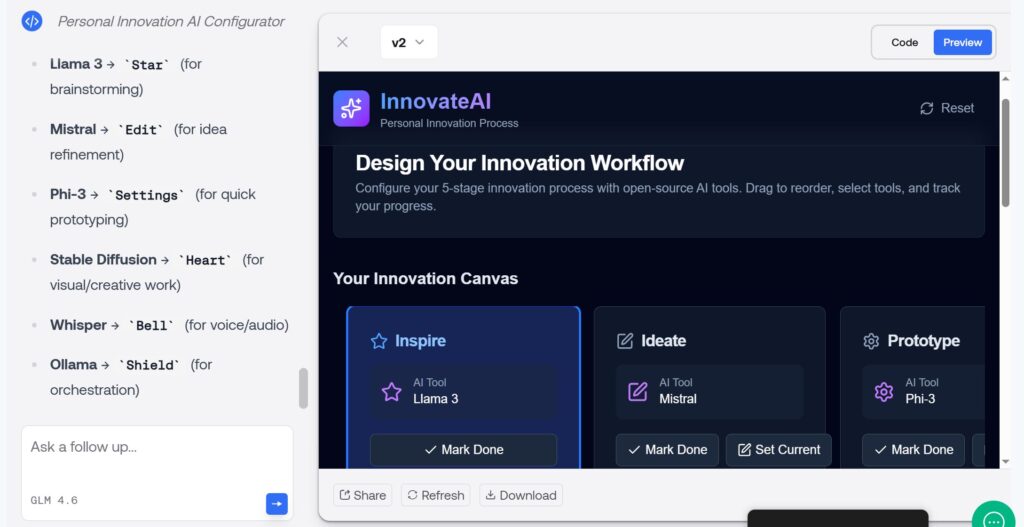
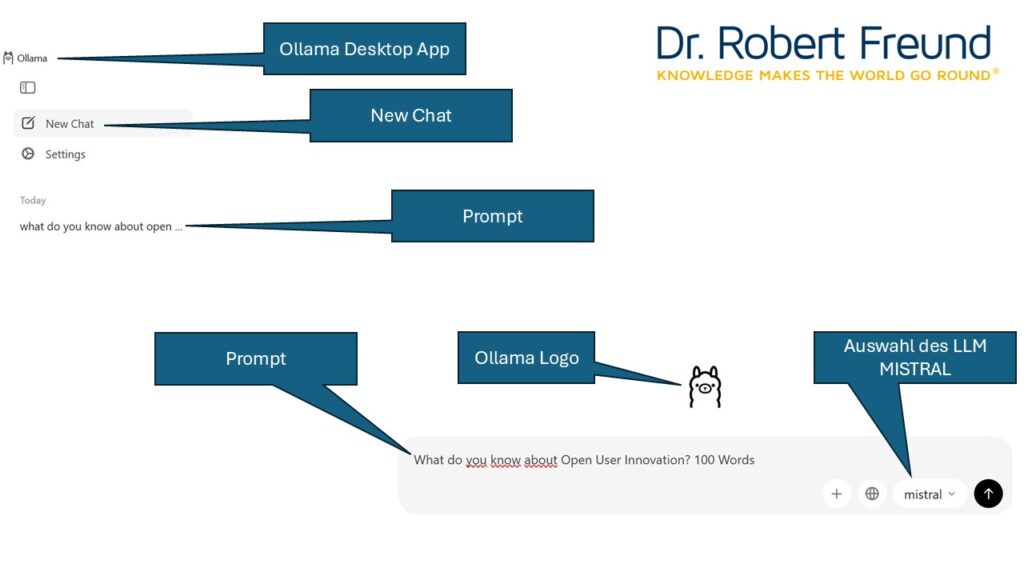
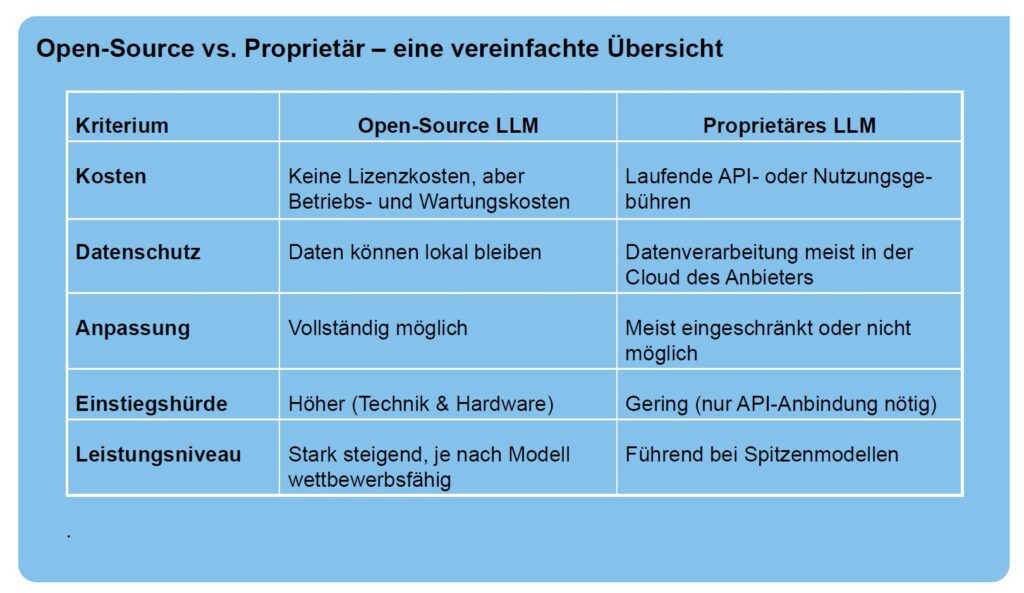
In den letzten Jahren gibt es sehr viele Content-Entwickler aus allen möglichen Bereichen, die sich gegen die Übernahme ihrer Inhalte als Trainingsdaten in den bekannten, kommerziellen KI-Modellen wehren.
Dabei kommt es einem so vor, als ob die großen KI-Unternehmen das wohl schon irgendwie „eingepreist“ haben und langwierige Gerichtsverfahren eingehen. Darüber hinaus muss auch die folgende Frage gestellt werden
Ist es möglich ist, leistungsfähige KI-Sprachmodelle zu trainieren, die ausschließlich auf gemeinfrei und offenen Texten basieren?
Die Antwort: Ja, es ist möglich.
In ihrem Paper hat eine Forscher-Gruppe nicht nur ausführlich dargelegt, welche Quellen sie dafür ausgewählt haben, sondern auch gleichzeitig ein entsprechendes Modell entwickelt und auf Hugging Face veröffentlicht:
„We release Common Pile v0.1, an 8TB corpus that—to our knowledge—constitutes the largest dataset built exclusively from openly licensed text. Alongside our dataset, we release Comma v0.1-1T and -2T, two performant 7-billion-parameter LLMs trained on text from the Common Pile, as well as the filtered and rebalanced data mixture we used for training. Our results demonstrate that not only is the Common Pile the strongest dataset for pretraining under an open-license constraint, but also that it produces models comparable to those trained on an equivalent amount of unlicensed data. This positive result holds promise for future of open-license pretraining, especially if the research community invests in collecting larger quantities of openly licensed text data in the future. Ultimately, we believe that the Common Pile v0.1 represents the first step on the path towards a more ethical language model ecosystem, where performance need not come at the cost of creator rights and legal transparency.“ (Kandpahl et al. (2025): The Common Pile v0.1: An 8TB Dataset of Public Domain and Openly Licensed Text).
Natürlich dominieren die proprietären KI-Modelle den Markt, und es fällt den Marktteilnehmer wegen dem in der Zwischenzeit eingetretenen Lock-in schwer, sich an andere KI-Modelle zu gewöhnen (Pfadabhängigkeit). Dennoch überlegen viele Einzelpersonen, Unternehmen, Not for Profit Organisationen oder auch Öffentliche Verwaltungen, ob sie sich nicht von der eingetretenen Abhängigkeit lösen sollten, ja müssen.
Siehe dazu auch Künstliche Intelligenz: Es ist so bequem, unmündig zu sein.