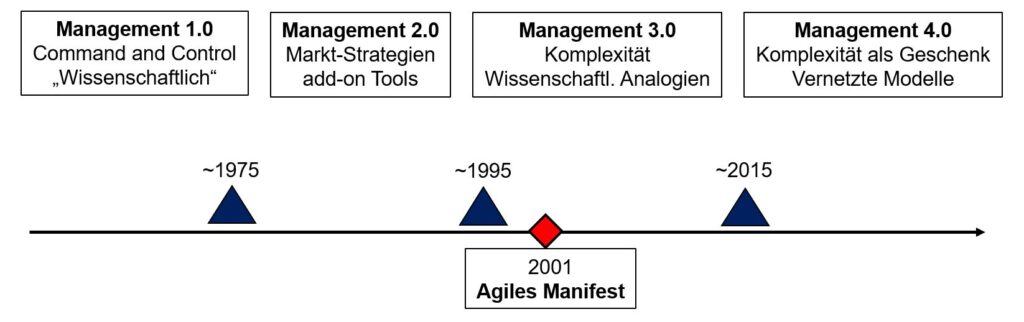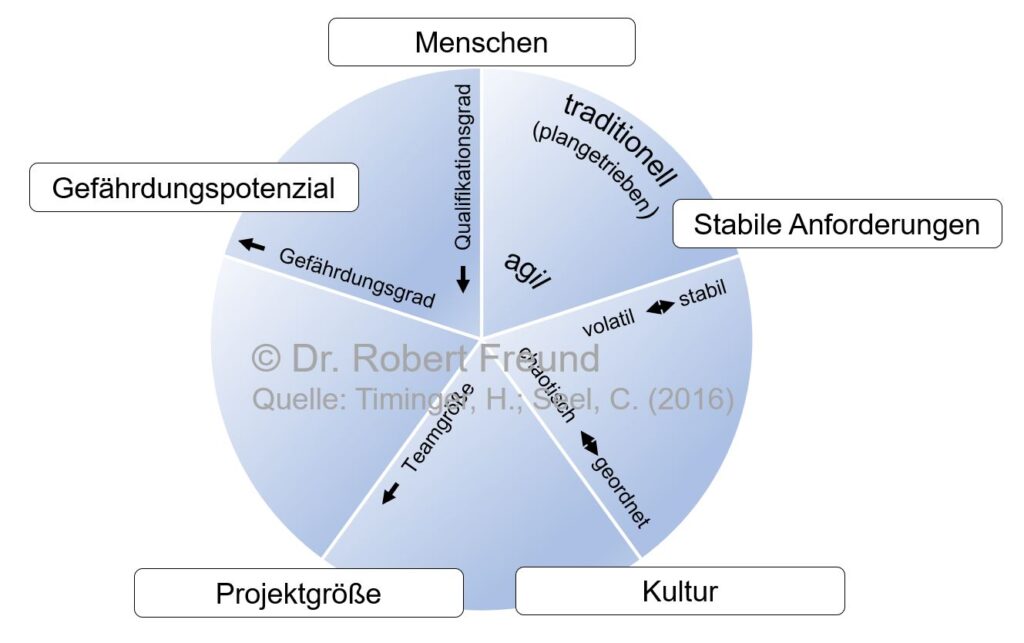
Im Projektmanagement gibt es in der Zwischenzeit die Erkenntnis, dass es zwischen den beiden Polen “Plangetriebenes Projektmanagement” und Agiles Projektmanagement” sehr viele Möglichkeiten für geeignete Vorgehensmodelle gibt.
Diese für seine Projekte zu analysieren (manchmal auch mehrmals während des Projektverlaufs) ist in Zukunft eine wichtige Aufgabe in Organisationen. Dafür stehen in der Zwischenzeit mehrere Optionen zur Verfügung. Siehe dazu DAS Projektmanagement-Kontinuum in der Übersicht, die für das eigene Projekt anhand verschiedener Kriterien ausgewählt werden können.
Zunächst einmal kann das mit der allseits bekannten Stacey-Matrix erfolgen, die eine einfache Möglichkeit bietet, schnell einen Überblick zu erhalten.
Cinefin wiederum nutzt eher die Wissensperspektive und zu analysieren, welches Vorgehensmodell geeignet erscheint.
Boehm und Turner schlagen vor, ein Projekt nach insgesamt 5 Dimensionen zu charakterisieren (siehe Abbildung): Menschen, Stabile Anforderungen, Kultur, Projektgröße und Gefährdungspotenzial.
Timinger wiederum hat in seinen Veröffentlichungen eine umfangreiche Liste an Kriterien zusammengestellt, die eine noch differenziertere Beurteilung ermöglicht. Siehe dazu Projektmanagement: Einfaches Tool zur Analyse des angemessenen Vorgehensmodells – Planbasiert, Hybrid, Agil.
Überlegen Sie, welche Instrumente für Ihre Organisation genutzt werden sollten. Möglicherweise entwickeln Sie aus den genannten Optionen ein eigenes Analysetool, für Projekte, Programme und Portfolios.