Durch die neuen Möglichkeiten, Künstliche Intelligenz (KI, englisch AI) im privaten Umfeld, in Unternehmen und Öffentlichen Verwaltungen einsetzen zu können, entsteht natürlich ein riesiger Weiterbildungsbedarf.
In erster Linie versuchen die etablierten Anbieter proprietärer KI-Systeme durch „kostenlose“ Online-Lehrgänge mit firmeneigenem Zertifikat Personen und Organisationen an sich zu binden. Ich habe dabei das Wort „kostenlos“ absichtlich in Anführungszeichen gesetzt. Der Grund ist, dass diese Lehrgänge sich natürlich auf die KI-Modelle beziehen, die diese Unternehmen anbieten. Durch die Gewöhnung an die KI-Modelle entsteht eine Pfadabhängigkeit, die die Unternehmen dann später für die Kommerzialisierung nutzen. Die Nutzer solcher Angebote zahlen also mit ihrer KI-Abhängigkeit.
In der Zwischenzeit gibt es auf dem Weiterbildungsmarkt auch wieder sehr viele Angebote, die sich mit Künstlicher Intelligenz befassen. Dabei wird in den Ausschreibungen nicht immer angegeben, um welche KI-Modelle es sich handelt. Auch verwenden diese Angebote oftmals die gewohnten KI-Modelle, die die führenden Tech-Unternehmen anbieten. Es handelts sich hierbei um seine subtilere Art, seine Produkte in den Markt zu bringen, und die Nutzer auch über diesen Weg in die KI-Abhängigkeit zu führen.
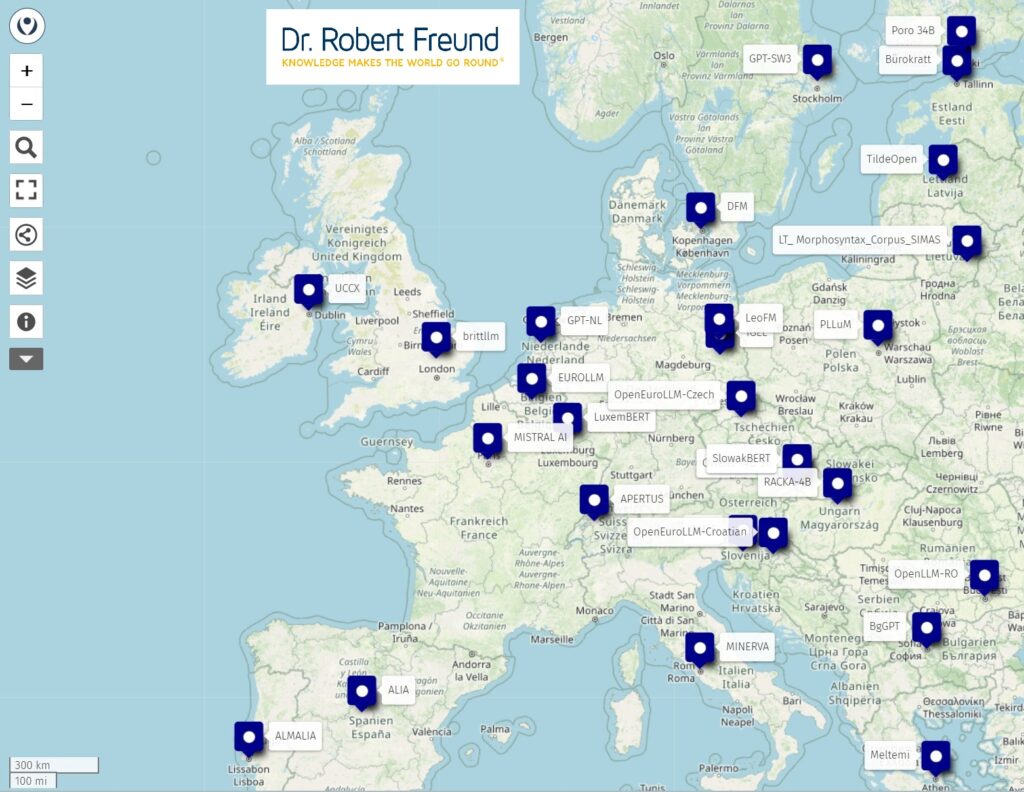
Weiterbildungen im Bereich Open Source KI-Modelle findet man nicht so oft. Es besteht hier allerdings ein großer Bedarf, da viele Personen, Unternehmen und Öffentliche Verwaltungen gar nicht wissen, was mit Open Source KI möglich ist. Siehe dazu Skill shortage: Es fehlen Kompetenzen zu Open Source Software und Open Source Hardware.
Es freut mich daher, dass der KI-Campus hier eine Alternative bietet. Die vom Bund geförderte, gemeinwohlorientierte Initiative bietet kostenlose Online-Kurse (auch mit Zertifikat) für jeden und jede Organisation an. Dabei wird auch die strategische Bedeutung von Open Source KI (Closed Source AI – Open Source AI), Datensouveränität (Digitale Souveränität) durch Open Source KI thematisiert.
„Der KI-Campus ist die Lernplattform des Stifterverbandes für Künstliche Intelligenz. Mit kostenlosen Onlinekursen, Videos, Podcasts und Tools stärken wir als gemeinwohlorientierte Initiative KI-Kompetenzen in der Gesellschaft. Kooperation und Offenheit sind dabei Leitprinzipien für unsere Arbeit.“
Wenn es Ihnen also um Digitale Souveränität, Datenschutz und Transparenz bei der Nutzung von Künstlicher Intelligenz geht, sollten Sie sich überlegen, ob Sie sich nicht einmal mit Open Source AI befassen – am besten mit einem der vom KI-Campus dazu angebotenen kostenlosen Online-Kursen.