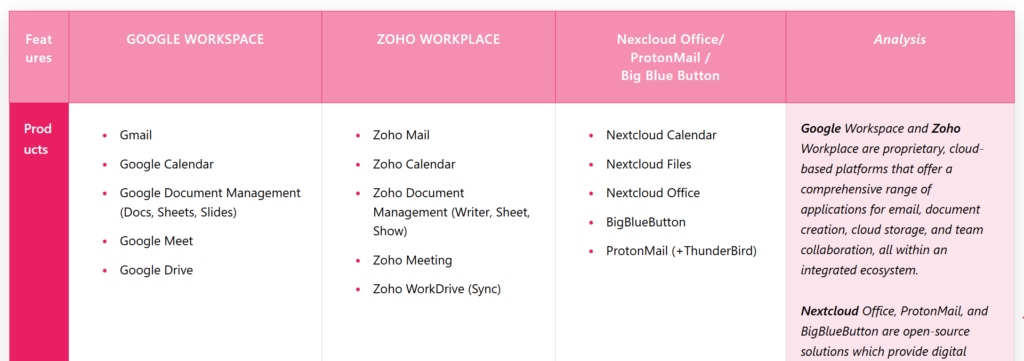
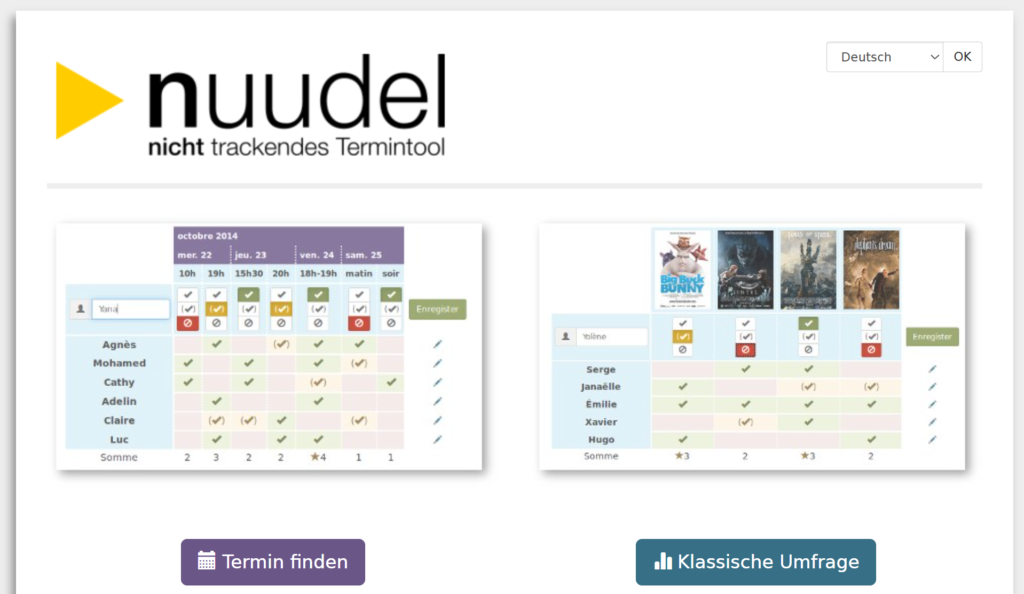
Bei Künstlicher Intelligenz denken aktuell die meisten an die KI-Modelle der großen Tech-Konzerne. ChatGPT, Gemini, Grok etc sind in aller Munde und werden immer stärker auch in Agilen Organisationen eingesetzt. Wie in einem anderen Blogbeitrag erläutert, sind in Agilen Organisationen Werte und Prinzipien mit ihren Hebelwirkungen die Basis für Praktiken, Methoden und Werkzeuge. Dabei beziehen sich viele, wenn es um Werte und Prinzipien geht, auf das Agile Manifest, und auf verschiedene Vorgehensmodelle wie Scrum und Kanban. Schauen wir uns einmal kurz an, was hier jeweils zum Thema genannt wird:
Agiles Manifest: Individuen und Interaktionen mehr als Prozesse und Werkzeuge
In der aktuellen Diskussion über die Möglichkeiten von Künstlicher Intelligenz werden die Individuen eher von den technischen Möglichkeiten (Prozesse und Werkzeuge) getrieben, wobei die Interaktion weniger zwischen den Individuen, sondern zwischen Individuum und KI-Modell stattfindet. Siehe dazu auch Mensch und Künstliche Intelligenz: Engineering bottlenecks und die fehlende Mitte.
SCRUM: Die Werte Selbstverpflichtung, Fokus, Offenheit, Respekt und Mut sollen durch das Scrum Team gelebt werden
Im Scrum-Guide 2020 wird erläutert, was die Basis des Scrum Frameworks ist. Dazu sind die Werte genannt, die u.a. auch die Offenheit thematisieren, Ich frage mich allerdings, wie das möglich sein soll, wenn das Scrum Team proprietäre KI-Modelle wie ChatGPT, Gemini, Grok etc. nutzt, die sich ja gerade durch ihr geschlossenes System auszeichnen? Siehe dazu auch Das Kontinuum zwischen Closed Source AI und Open Source AI.
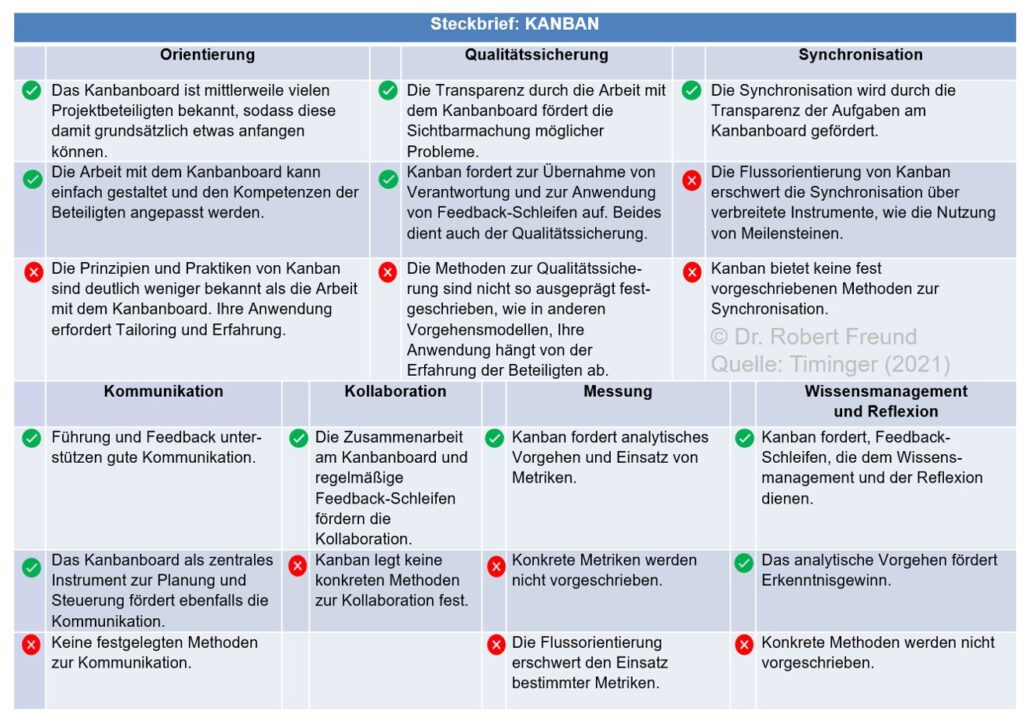
KANBAN basiert auf folgenden Werten: Transparenz, Balance, Kooperation, Kundenfokus, Arbeitsfluss, Führung, Verständnis, Vereinbarung und Respekt.
Bei den proprietären KI-Modellen ist die hier angesprochene Transparenz kaum vorhanden. Nutzer wissen im Detail nicht, mit welchen Daten das Modell trainiert wurde, oder wie mit eingegebenen Daten umgegangen wird, etc.
In einem anderen Blogbeitrag hatte ich dazu schon einmal darauf hingewiesen, dass man sich mit proprietärer Künstlicher Intelligenz (KI) auch die Denkwelt der Eigentümer einkauft.
Um agile Arbeitsweisen mit Künstlicher Intelligenz zu unterstützen, sollte das KI-Modell den genannten Werten entsprechen. Bei entsprechender Konsequenz, bieten sich also KI-Modelle an, die transparent und offen sind. Genau an dieser Stelle wird deutlich, dass das gerade die KI-Modelle sind, die der Definition einer Open Source AI entsprechen – und davon gibt es in der Zwischenzeit viele. Es wundert mich daher nicht, dass die Open Source Community und die United Nations die gleichen Werte teilen.
Es liegt an uns, ob wir uns von den Tech-Giganten weiter in eine immer stärker werdende Abhängigkeit treiben lassen, oder andere Wege gehen – ganz im Sinne einer Digitalen Souveränität. Siehe dazu auch Open Source AI: Besser für einzelne Personen, Organisationen und demokratische Gesellschaften.