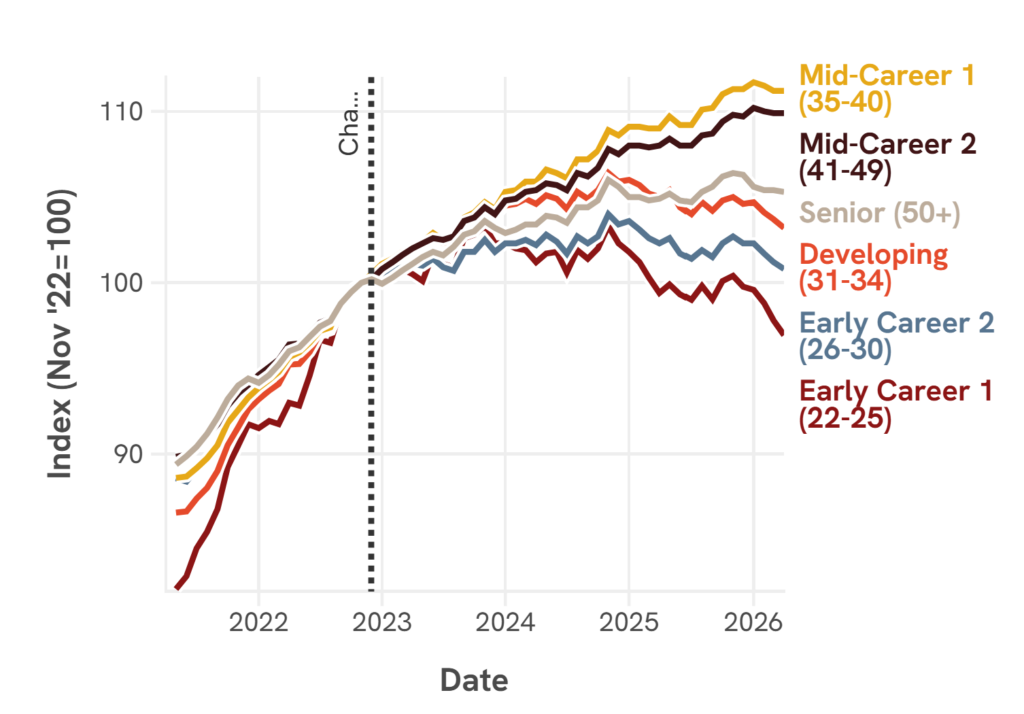
Beschäftigungstrend nach der Einführung von ChatGPT (Quelle: https://digitaleconomy.stanford.edu/project/indicators/)
Die Entwicklungen bei Künstlicher Intelligenz sind sehr dynamisch, sodass manche Studien schon der Realität hinterherhinken, wenn sie veröffentlicht werden. Weiterhin gibt es auch Studien, die sich mit der selben Thematik befassen, aber zu unterschiedlichen Schlussfolgerungen führen. – wem kann man da vertrauen?
Es ist daher gut, das die Stanford University nun eine Plattform veröffentlicht hat, auf der viele graphische Auswertungen zu unterschiedlichen Fragestellungen zu finden sind.
„Yet we lack timely, trusted ways to measure how these changes are affecting work, productivity, and value creation in the economy. (…) We believe that a better understanding of the technology’s effects will lead to better decisions“ (Quelle)
In der Abbildung wird z.B. deutlich, wie sich der Beschäftigungstrend nach der Einführung von ChatGPT auf die verschiedenen Altersstrukturen ausgewirkt hat. Die Beschäftigungstrend geht beispielsweise für die Personen zwischen 22-25 Jahren im Vergleich zum November 2022 zurück.
Mistral AI ist ein französisches Unternehmen, das eine Modellfamilie veröffentlicht, die europäischen Anforderungen an KI-Modelle entspricht, und Open Source verfügbar ist. (Open Models) Die Leistungsfähigkeit von den Mistral- Modellen nähert sich den Cloud AI Modellen (Closed Models) wie ChatGPT, Gemini etc. an (Open Source AI holt auf). Mit Le Chat gibt es auch eine europäische Alternative zu ChatGPT.
Mistral-Modelle können bei Mistral selbst, also auf in deren Cloud, getestet werden. Darüber hinaus ist es auch möglich, die Modelle über Hugging Face herunterzuladen und auf dem eigenen Server zu nutzen, z.B. mit LocalAI.
Der Trend zu immer kleineren, speziellen und leistungsstarken Modellen (SLM: Small Language Models) macht es immer attraktiver, solche Modelle auf dem eigenen Laptop, also auf „Heim-Hardware„, zu nutzen. Das ist u.a. auch mit Mistral möglich. Wie genau, wird in dem folgenden Artikel gut beschrieben:
Wie die proprietären KI-Modelle wie ChatGPT, Gemini, Anthropic, Grok, Claude etc. funktionieren, ist oft nicht transparent, wodurch sich letztendlich auch kein wirkliches Vertrauen in diese Systeme aufbauen kann – it all starts with trust.
Es ist daher nur konsequent, wenn immer mehr Einzelpersonen, Unternehmen und Öffentliche Verwaltungen auf offene und transparente KI-Modelle setzen. In dem Zusammenhang gibt es auch ein Forschungsfeld, das sich mit den damit einhergehenden Fragestellungen befasst.
„Explainable AI (XAI) – Forschungs- und Anwendungsfeld der Künstlichen Intelligenz, das Methoden entwickelt, um Entscheidungen, Vorhersagen oder generierte Inhalte von KI-Systemen transparent, nachvollziehbar und überprüfbar zu machen. Ziel ist es, Vertrauen zu schaffen und Fehlentscheidungen zu vermeiden.“ (Mittelstand Digital Fokus Mensch (2026): Digitale Souveränität als Basis für sichere KI-Anwendungen).
Es stellt sich dabei natürlich gleich die Frage, was das z.B. für Kleine und Mittlere Unternehmen (KMU) in der Praxis bedeuten kann. „Gerade in geschäftskritischen Anwendungen ist Vertrauen in die Funktionsweise von KI-Systemen unerlässlich“ (ebd.). Solche Anwendungen sind ganz besonders Innovationsprozesse. Da sich gerade der deutsche Mittelstand innovativ ausrichtet, ja ausrichten muss, kommt Explainable AI (XAI) ein große Bedeutung zu.
Das Fraunhofer Institut hat dazu eine eXplainable Artificial Intelligence (XAI)-Toolbox entwickelt: „Das heißt, die Toolbox kann z. B. zur Datenanalyse, zum Debugging und zur Erklärung der Vorhersage eines beliebigen Black-Box-Modells eingesetzt werden“ (ebd.).
Die Nutzung den bekannten KI-Modelle (GenAI) wie ChatGPT, Gemini, Grok, Anthropic, Claude etc ist weit verbreitet. Es ist auch möglich, diese Modelle mit eigenen Daten zu trainieren, doch ist der Großteil dann immer noch zu wenig unternehmensspezifisch. Siehe dazu auch Digitale Souveränität: Europa, USA und China im Vergleich.
Mistral AI ist hier in den letzten Jahren einen eigenen Weg gegangen, indem es als europäische Modell Familie DSGVO-konform ist, und auch als Open Source AI zur Verfügung steht.
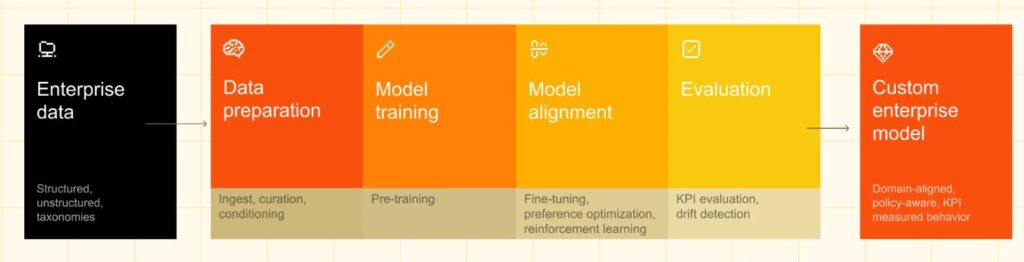
Mit dem nun veröffentlichten Mistral Forge können Unternehmen auf Basis der eigenen Daten und Expertise ihr eigenes KI-Modell entwickeln.
From your data to your model
Vorgehensweise bei Mistral Forge: https://mistral.ai/products/forge
Die einzelnen Schritte werden auf der genannten Webseite ausführlich dargestellt. Es wir spannend zu sehen, welche Organisationen diesen Weg gehen werden. Aktuell sind das immerhin so bekannte Namen wie ASML, Ericsson, ESA und DSO National Laboratories aus Singapur. Siehe dazu auch
Auf die neue Mistral 3 KI-Modell-Familie hatte ich schon im Dezember 2025 in einem Blogbeitrag hingewiesen. Das französische Start-Up wurde 2023 gegründet: „(…) the company’s mission of democratizing artificial intelligence through open-source, efficient, and innovative AI models, products, and solutions“ (Quelle: Website).
Dieses Demokratisieren von Künstlicher Intelligenz durch Open Source, als europäischer und DSGVO-konformer Ansatz, ist genau der Weg, den ich schon in verschiedenen Beiträgen vertreten habe. Es ist daher interessant, auch den in 2024 veröffentlichten Bot Le Chat im Vergleich beispielsweise zu ChatGPT zu testen.
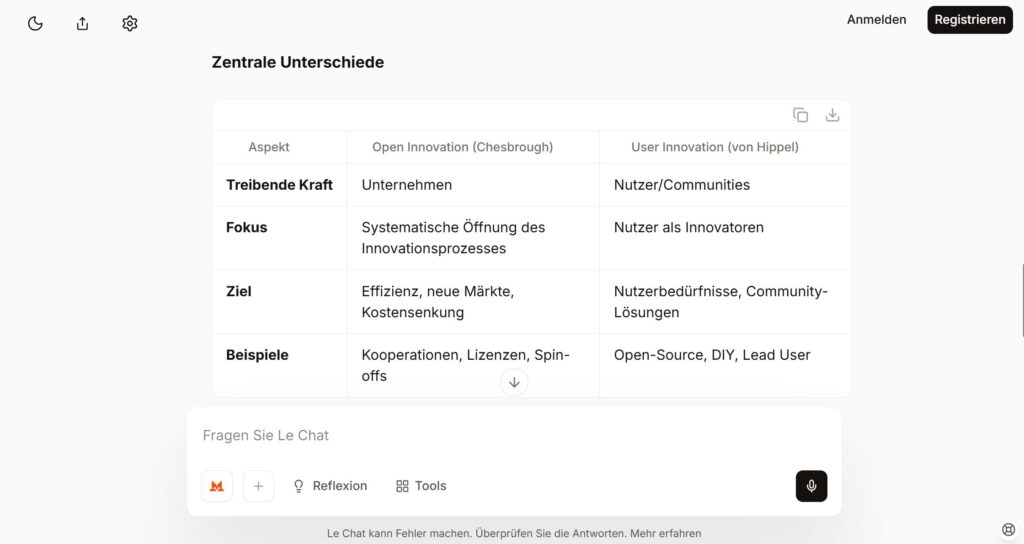
Die Abbildung weiter oben zeigt die Landingpage für Le Chat mit einem einfachen Feld für die Eingabe eines Prompts. Man kann die Leistungsfähigkeit des Bots testen, ohne sich anmelden zu müssen. Ich habe mich also zunächst nicht angemeldet und einfach einmal eine Frage eingegeben, die mich aktuell beschäftigt: Es geht um die Unterschiede zwischen den Auffassungen von Henry Chesbrough und Eric von Hippel zu Open Innovation.
Ausschnitt aus der Antwort zum eingegebenen Prompt
Die Abbildung zeigt einen Ausschnitt aus der umfangreichen Antwort auf meine Frage, inkl. der generierten Gegenüberstellung der beiden Ansichten auf Open Innovation. Die Antwort kam sehr schnell und war qualitativ gut – auch im Vergleich zu ChatGPT.
Mistral Le Chat ist ein europäisches Produkt, das auch der DSGVO unterliegt und darüber hinaus neben französisch- und englischsprachigen, auch mit deutschsprachigen Daten trainiert wurde. Es ist spannend, sich mit den Mistral-KI-Modellen und mit Le Chat intensiver zu befassen.
Wir haben den kostenpflichtigen ChatGPT-Account in der Zwischenzeit gekündigt, und werden mehr auf Modell-Familien wie Mistral 3 und MistralLe Chat setzen. Wir sind gespannt, wie sich die Open Source Alternativen in Zukunft weiterentwickeln – ganz im Sinne einer Digitalen Souveränität. Siehe dazu auch
AI (Artificial intelligence) AI management and support technology in the Business plan marketing success customer. AI management concept.
Jede Person möchte seine Persönlichkeit, seine Kompetenz kommunizieren. Das passiert im analogen Raum genauso wie in digitalen Räumen. Mit Hilfe von digitalen Medien transportiert jeder moderne Mensch Fragmente seiner Persönlichkeit in unterschiedlichen digitalen Räumen. Dabei kann es durchaus passieren, dass die im Digitalen Raum 1 dargestellte Person, sich von der im Digitalen Raum 2 unterscheidet.
Andererseits ist diese Perspektive auch reflexiv zu sehen, denn die Interaktionen und Kommunikationen mit anderen wirken durchaus auch auf die eigene, digitale und analoge Person zurück. Dazu passt ganz gut der folgende Text:
„Das dadurch repräsentierte Selbst muss jedoch nicht zwangsläufig dem realen, analogen Selbst entsprechen, sondern kann auf eine bewusst optimierte Repräsentation hinauslaufen oder eine fiktive andere Gestalt annehmen. Zudem können sich Subjekte in diversen digitalen Netzwerken unterschiedlich repräsentieren. Auch Laura Robinson argumentiert, dass das Subjekt anhand der digitalen Elemente ein „self-ing“ betreibe und sich sodann als „Cyberself“ (2007, S. 98) hervorbringe. Das Cyberself sei ein ephemeres Selbst, so Robinson, welches nur für kurze Zeit beständig, rasch änderbar und ohne langfristige Bedeutung sei, da es sich stets in Abhängigkeit zu Handlungen bilde (vgl. ebd.)“ (Rathmann 2022).
Es stellt sich für mich die Frage, wie sich beispielsweise die immer stärkere Nutzung von KI-Modellen auf das analoge Selbst und das Cyberself auswirkt. Wenn die Richtung der kommunikativen Wechselwirkungen auch reflexiv ist, sind KI-Modelle durchaus persönlichkeitsverändernd.
Das kann einerseits positiv zur eigenen Entwicklung beitragen, oder eben auch nicht. Bei den, von den amerikanischen Tech-Konzernen entwickelten Modellen, habe ich so meine Bedenken, da diese Modelle ein Mindset repräsentieren, dass für Menschen, und ganze Gesellschaften gravierende negative Folgen haben kann.
Die Intransparenz der bekannten Closed Sourced Modelle wie ChatGPT von OpanAI oder Gemini von Google etc. oder auch das von Elon Musk beeinflusste Modell Grok von X repräsentieren eine Denkhaltung, die auf ein von Technologie dominiertes Gesellschaftssystem ausgerichtet sind. Es stellt sich die Frage, ob wir das so wollen.
Aktuell bekannte KI-Anwendungen rühmen sich seit Jahren, sehr große Mengen an Trainingsdaten (Large Language Models) zu verarbeiten. Der Tenor war und ist oft noch: Je größer die Trainingsdatenbank, um so besser.
In der Zwischenzeit weiß man allerdings, dass das so nicht stimmt und Large Language Models (LLMs) durchaus auch Nachteile haben. Beispielsweise ist die Genauigkeit der Daten ein Problem – immerhin sind die Daten oft ausschließlich aus dem Internet. Daten von Unternehmen und private Daten sind fast gar nicht verfügbar. Weiterhin ist das Halluzinieren ein Problem. Dabei sind die Antworten scheinbar plausibel, stimmen aber nicht.
Muddu Sudhaker hat diese Punkte in seinem Artikel noch einmal aufgeführt. Dabei kommt er zu dem Schluss, dass es in Zukunft immer mehr darauf ankommen wird, kleinere, speziellere Trainingsdatenbanken zu nutzen – eben Small Language Models (SLMs).
Muddu Sudhakar (2024): Small Language Models (SLMs): The Next Frontier for the Enterprise, Forbes, LINK
Große Vorteile der SLMs sieht der Autor natürlich einmal in der Genauigkeit der Daten und damit in den besseren Ergebnissen. Weiterhin sind SLMs natürlich auch kostensparender. Einerseits sind die Entwicklungskosten geringer, andererseits benötigt man keine aufwendige Hardware, um SLMs zu betreiben. Teilweise können solche Modelle auf dem eigenen PC, oder auf dem Smartphone betrieben werden.
Solche Argumente sind natürlich gerade für Kleine und Mittlere Unternehmen (KMU) interessant, die mit den geeigneten SLMs und ihren eigen, unternehmensinternen Daten ein interessantes und kostengünstiges KI-System aufbauen können.
Voraussetzung dafür ist für mich, dass alle Daten auf den eigenen Servern bleiben, was aktuell nur mit Open Source AI möglich ist. OpenAI mit ChatGPT ist KEIN Open Source AI.
Aktuell wird alles mit Künstlicher Intelligenz (AI: Artificial Intelligence) in Verbindung gebracht. Die Neukombination von bestehenden Ansätzen kann dabei zu interessanten Innovationen führen.
Die Website ALL Our Ideas verbindet beispielsweise Online-Umfragen mit Crowdsourcing und Künstlicher Intelligenz.
„All Our Ideas is an innovative tool that you can use for large-scale online engagements to produce a rank-ordered list of public input. This „Wiki Survey“ tool combines the best of survey research with crowdsourcing and artificial intelligence to enable rapid feedback“ (ebd.).
Ein kurzes Tutorial ist gleich auf der Website zu finden. Darin wird erläutert, wie Sie die Möglichkeiten selbst nutzen können. Starten Sie einfach mit einer eigenen Online-Umfrage.
Die Idee und das Konzept finde ich gut, da auch der Code frei verfügbar ist: Open Source Code. Damit kann alles auf dem eigenen Server installiert werden. Bei der Integration von KI-Modellen schlage ich natürlich vor, Open Source KI (Open Source AI) zu nutzen.
Die Digitale Abhängigkeit von amerikanischen oder chinesischen Tech-Konzernen, macht viele Privatpersonen, Unternehmen und Verwaltungen nervös und nachdenklich. Dabei stellen sich Fragen wie:
Wo befinden sich eigentlich unsere Daten?
Wissen Sie, wo sich ihre Daten befinden, wenn Sie neben ihren internen ERP-Anwendungen auch Internet-Schnittstellen, oder auch Künstliche Intelligenz, wie z.B. ChatGPT etc. nutzen?
Um wieder eine gewissen Digitale Souveränität zu erlangen, setzen wir seit mehreren Jahren auf Open Source Anwendungen. Die Abbildung zeigt beispielhaft einen Screenshot aus unserer NEXTCLOUD. Es wird deutlich, dass alle unsere Daten in Deutschland liegen – und das auch bei Anwendungen zur Künstlichen Intelligenz, denn wir verwenden LocalAI.
Souveränitätsscore für KI-Systeme – Ausschnitt (Quelle: https://digital-sovereignty.net/score/score-ai)
In der Zwischenzeit sind sehr viele KI-Modelle (AI Model) verfügbar, sodass es manchmal zu etwas unscharfen Beschreibungen kommt. Eine erste Unterscheidung ist, Closed Source AI, Open Weights AI und Open Source AI nicht zu verwechseln. In dem Beitrag AI Kontinuum wird das erläutert.
„OpenAI“ wurde beispielsweise als Muttergesellschaft von ChatGPT 2015 als gemeinnützige Organisation gegründet, seit 2019 ist „OpenAI“ gewinnorientiert und wird von Microsoft dominiert. Durch geschicktes Marketing wird oftmals suggeriert, dass von kommerziellen Anbietern bereitgestellte Modelle „Open Source AI“ sind.
Wenn Sie sich also für AI Modelle interessieren, können Sie dieses Modell gegenüber den in der Definition genannten Kriterien prüfen.
Weiterhin können Sie den Souveränitätsscore für KI Systeme von Prof. Wehner nutzen (Abbildung). Schauen Sie sich auf der Website auch noch weiter um – es lohnt sich.
Diese Website benutzt Cookies. Wenn du die Website weiter nutzt, gehen wir von deinem Einverständnis aus.