Immer mehr Menschen nutzen Künstliche Intelligenz, um gesundheitliche, psychologische oder berufliche Themen zu analysieren. Der Ratgeber ist in diesen Fällen also nicht der Arzt, der Psychologe, oder ein Kollege am Arbeitsplatz, sondern ChatGPT oder andere bekannte KI-Modelle.
Es ist in dem Zusammenhang wichtig, welche Werte von dem KI-Modell „vertreten“ werden. Warum? In dem Beitrag Digitale Souveränität: Europa, USA und China im Vergleich wird deutlich, wie unterschiedlich die Werte von KI-Modellen der US-amerikanischen Tech-Konzerne, chinesischen Modellen, und europäischen Modellen sein können.
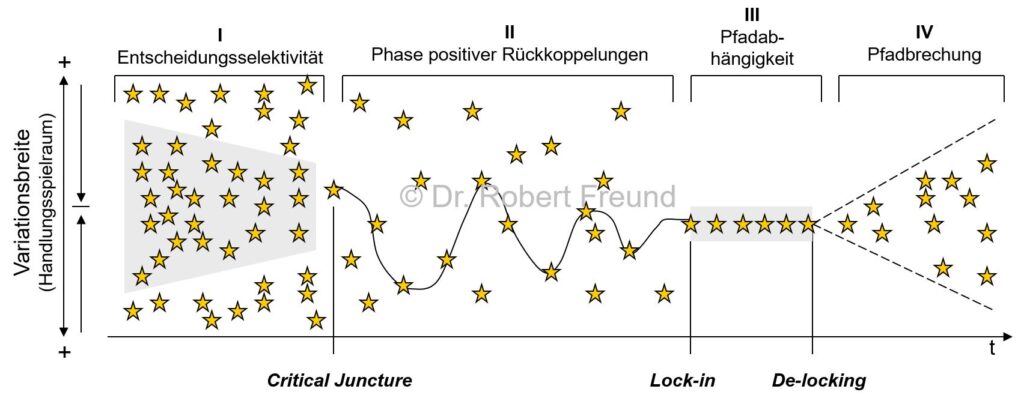
Da wiederum Werte Ordner sozialer Komplexität sind, ermöglichen sie ein Handeln unter Unsicherheit und bestimmen die menschliche Selbstorganisation.
Systemische Sicht auf Werte: „Werte können als Ordnungsparameter (Ordner) selbstorganisierter komplexer biotischer, individueller, gruppenförmiger oder aggregierterer sozialhistorischer Systeme aufgefasst werden. Diese Ordner bestimmen oder beeinflussen zumindest stark die individuell-psychische und sozial-kooperativ kommunikative menschliche Selbstorganisation und ermöglichen eben damit jenes Handeln unter prinzipieller kognitiver Unsicherheit“ (Haken 1996).
Bei der Kommunikation Mensch – KI dringt die KI immer tiefer in das Profil des Menschen ein, was dazu führen kann, dass sich KI-Modelle beim Nutzer einschmeicheln. Siehe dazu auch Künstliche Intelligenz: Verstärkt Personalisierung Schmeicheleien? Ergebnisse einer Studie..
Da die Werte der proprietären KI-Modelle oft nicht transparent sind, kann es daher zu unerwünschten Manipulationen kommen. Siehe dazu auch Open Source AI: Warum sollte Künstliche Intelligenz demokratisiert werden?