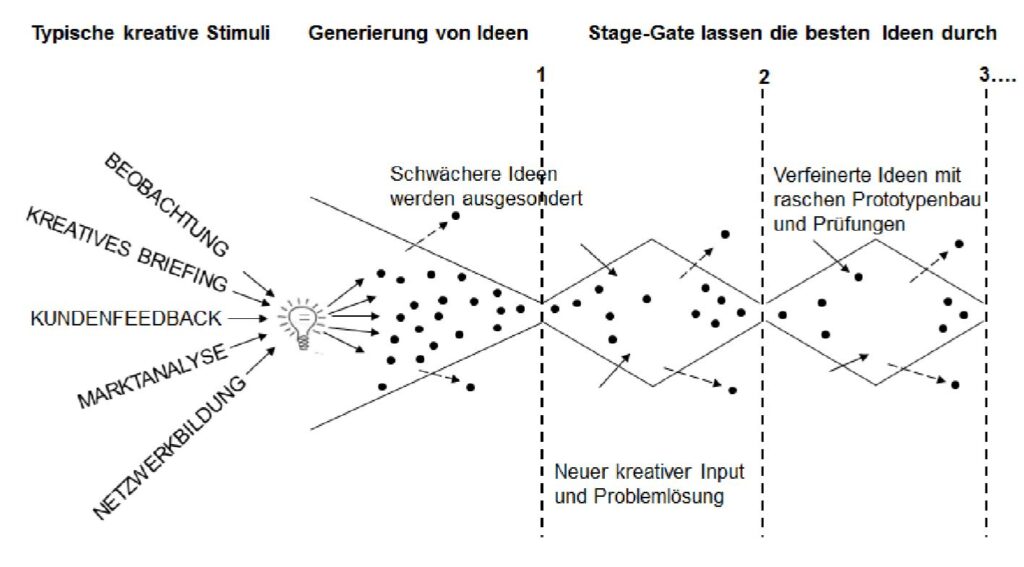
Es ist schon erstaunlich, wie wir mit unseren Daten umgehen. Viele bestätigen die verschiedenen Richtlinien der Anbieter einfach, da sie (die Nutzer) die ganzen Bestimmungen gar nicht lesen, geschweige denn verstehen können. Das wiederum führt dazu, dass die jeweiligen Anbieter Nutzer-Daten teilweise, oder recht umfangreich, speichern und nutzen. Einerseits geschieht das, um die Nutzung zu vereinfachen – das Nennen die Provider dann Personalization-, wobei Kontext-Informationen des Users gewonnen werden. Darüber hinaus werden alle User-Daten noch für „andere Zwecke“ verwendet, die ein User gar nicht mehr überblicken kann.
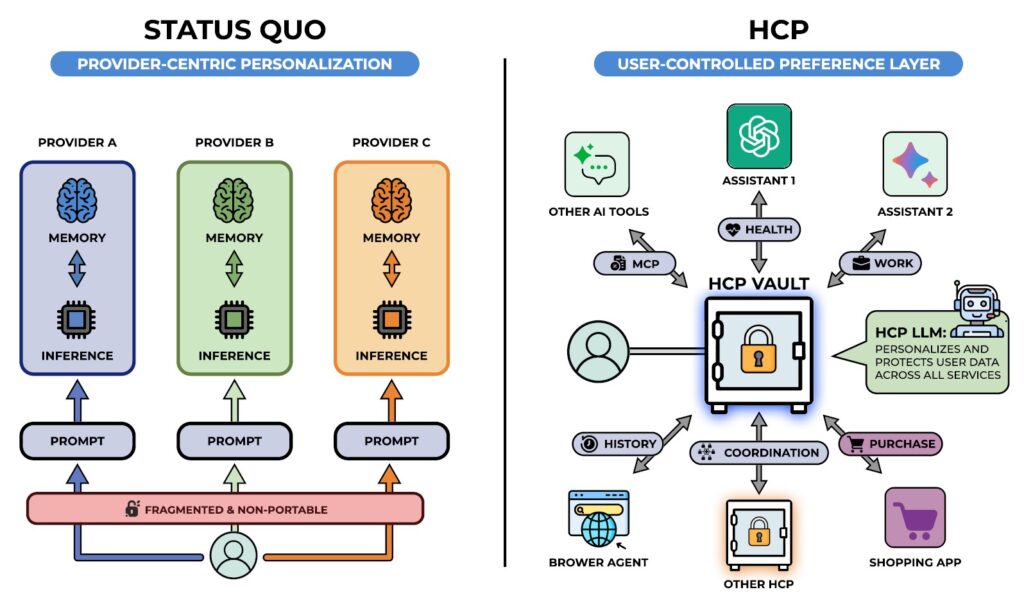
In der Abbildung ist auf der linken Seite zu erkennen, was bei unterschiedlichen Anbietern (Providern) mit User-Prompts passiert. Jeder Provider baut seine Personalisierung gegenüber dem User auf (Provider-Centric Personalization), wobei die Daten und Kontext-Informationen beim Provider gespeichert werden. Diese Informationen über die Personalisierung sind nicht einfach auf andere Provider übertragbar, was dem jeweiligen Provider nicht interessiert. In diesem System hat der User kaum alternative Möglichkeiten.
Auf der rechten Seite der Abbildung ist ein ganz anderer Personalisierungs-Ansatz zu erkennen, der den User in den Mittelpunkt stellt (User-Controlled Preference Layer). Die Daten eines Users und der jeweilige Kontext werden in einem HCP Vault (einer Art Daten-Tresor) gespeichert, und können verschiedenen Systemen zur Verfügung gestellt werden. Bei diesem Ansatz müssen natürlich alle anderen Anwendungen über definierte Schnittstellen verbunden werden können – hier kommt das HCP (Human Context Protocol) ins Spiel..
„On the right panel, a shared preference layer is introduced in which user context is stored in a centralized HCP vault and selectively accessed by multiple assistants, tools, and applications through an HCP-mediated interface. User preference data (generated by varied user activity) is moderated by HCP to consumer agents. Each agent obtains only the relevant subset of the user’s complete preference data“ (Shah et al., 2025).
Diese Entwicklung unterstützt den Trend, dass User über ihre eigenen Daten und die damit verbundenen Kontext-Informationen selbst bestimmen können, was gerade in Zeiten von Künstlicher Intelligenz immer wichtiger wird. Siehe dazu auch Was wäre, wenn jeder über seine generierten Daten selbst entscheiden könnte?
Auf der MCP 2026 (16.-19.09.2026, Balatonfüred, Ungarn) gehe ich darauf ein: Open-Source AI for Open User Innovation: Designing a Personal Fabrication Framework.