Die Nutzung den bekannten KI-Modelle (GenAI) wie ChatGPT, Gemini, Grok, Anthropic, Claude etc ist weit verbreitet. Es ist auch möglich, diese Modelle mit eigenen Daten zu trainieren, doch ist der Großteil dann immer noch zu wenig unternehmensspezifisch. Siehe dazu auch Digitale Souveränität: Europa, USA und China im Vergleich.
Mistral AI ist hier in den letzten Jahren einen eigenen Weg gegangen, indem es als europäische Modell Familie DSGVO-konform ist, und auch als Open Source AI zur Verfügung steht.
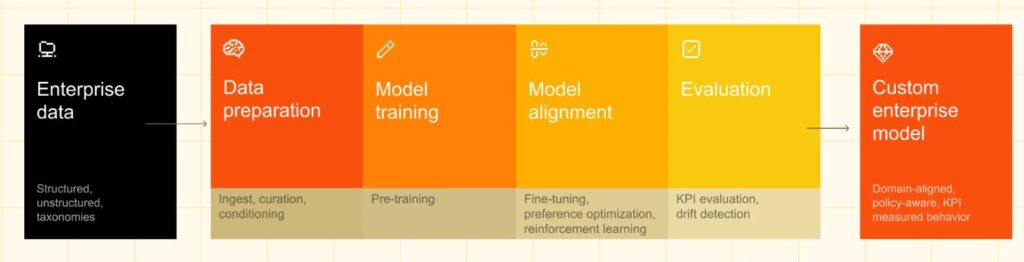
Mit dem nun veröffentlichten Mistral Forge können Unternehmen auf Basis der eigenen Daten und Expertise ihr eigenes KI-Modell entwickeln.
From your data to your model
Vorgehensweise bei Mistral Forge: https://mistral.ai/products/forge
Die einzelnen Schritte werden auf der genannten Webseite ausführlich dargestellt. Es wir spannend zu sehen, welche Organisationen diesen Weg gehen werden. Aktuell sind das immerhin so bekannte Namen wie ASML, Ericsson, ESA und DSO National Laboratories aus Singapur. Siehe dazu auch
AI (Artificial intelligence) AI management and support technology in the Business plan marketing success customer. AI management concept.
Jede Person möchte seine Persönlichkeit, seine Kompetenz kommunizieren. Das passiert im analogen Raum genauso wie in digitalen Räumen. Mit Hilfe von digitalen Medien transportiert jeder moderne Mensch Fragmente seiner Persönlichkeit in unterschiedlichen digitalen Räumen. Dabei kann es durchaus passieren, dass die im Digitalen Raum 1 dargestellte Person, sich von der im Digitalen Raum 2 unterscheidet.
Andererseits ist diese Perspektive auch reflexiv zu sehen, denn die Interaktionen und Kommunikationen mit anderen wirken durchaus auch auf die eigene, digitale und analoge Person zurück. Dazu passt ganz gut der folgende Text:
„Das dadurch repräsentierte Selbst muss jedoch nicht zwangsläufig dem realen, analogen Selbst entsprechen, sondern kann auf eine bewusst optimierte Repräsentation hinauslaufen oder eine fiktive andere Gestalt annehmen. Zudem können sich Subjekte in diversen digitalen Netzwerken unterschiedlich repräsentieren. Auch Laura Robinson argumentiert, dass das Subjekt anhand der digitalen Elemente ein „self-ing“ betreibe und sich sodann als „Cyberself“ (2007, S. 98) hervorbringe. Das Cyberself sei ein ephemeres Selbst, so Robinson, welches nur für kurze Zeit beständig, rasch änderbar und ohne langfristige Bedeutung sei, da es sich stets in Abhängigkeit zu Handlungen bilde (vgl. ebd.)“ (Rathmann 2022).
Es stellt sich für mich die Frage, wie sich beispielsweise die immer stärkere Nutzung von KI-Modellen auf das analoge Selbst und das Cyberself auswirkt. Wenn die Richtung der kommunikativen Wechselwirkungen auch reflexiv ist, sind KI-Modelle durchaus persönlichkeitsverändernd.
Das kann einerseits positiv zur eigenen Entwicklung beitragen, oder eben auch nicht. Bei den, von den amerikanischen Tech-Konzernen entwickelten Modellen, habe ich so meine Bedenken, da diese Modelle ein Mindset repräsentieren, dass für Menschen, und ganze Gesellschaften gravierende negative Folgen haben kann.
Die Intransparenz der bekannten Closed Sourced Modelle wie ChatGPT von OpanAI oder Gemini von Google etc. oder auch das von Elon Musk beeinflusste Modell Grok von X repräsentieren eine Denkhaltung, die auf ein von Technologie dominiertes Gesellschaftssystem ausgerichtet sind. Es stellt sich die Frage, ob wir das so wollen.
Wenn Sie die bekannten Trainingsmodelle (LLM: Large Language Modells) bei ChatGPT (OpenAI), Gemini (Google) usw. nutzen, werden Sie sich irgendwann als Privatperson, oder auch als Organisation Fragen, was mit ihren eingegebenen Texten (Prompts) oder auch Dateien, Datenbanken usw. bei der Verarbeitung Ihrer Anfragen und Aufgaben passiert.
Antwort: Das weiß keiner so genau, da die KI-Modelle nicht offen und transparent sind.
Um die eigene Souveränität über unsere Daten zu erlangen, haben wir seit einiger Zeit angefangen, uns Stück für Stück von kommerziellen Anwendungen zu lösen. Angefangen haben wir mit NEXTCLOUD, das auf unserem eigenen Server läuft. NEXTCLOUD Hub 9 bietet die Möglichkeiten, die wir alle von Microsoft kennen.
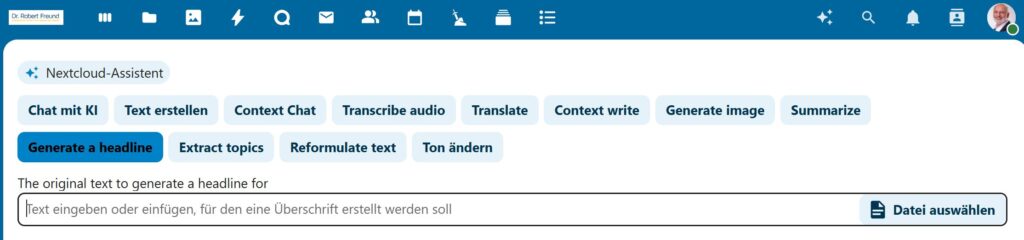
Dazu kommt in der Zwischenzeit auch ein NEXTCLOUD-Assistent, mit dem wir auch KI-Modelle nutzen können, die auf unserem Serverlaufen. Dieses Konzept einer LOCALAI – also einer lokal angewendeten KI – ist deshalb sehr interessant, da wir nicht nur große LLM hinterlegen, sondern auch fast beliebig viele spezialisierte kleinere Trainingsmodelle (SML: Small Language Models) nutzen können. Siehe dazu Free Open Source Software (FOSS): Eigene LocalAI-Instanz mit ersten drei Modellen eingerichtet.
Wie in der Abbildung zu sehen, können wir mit dem NEXTCLOUD Assistenten auch Funktionen nutzen, und auch eigene Dateien hochladen. Dabei werden die Dateien auch mit Hilfe von dem jeweils lokal verknüpften lokalen KI-Modell bearbeitet. Alle Daten bleiben dabei auf unserem Server – ein unschätzbarer Vorteil.
Die Kombination von LOCALAI mit eigenen Daten auf dem eigenen Server macht dieses Konzept gerade für Kleine und Mittlere Unternehmen (KMU) interessant.
Immer mehr Privatpersonen und Organisationen realisieren, dass die populären Trainingsdaten (LLM: Large Language Models) für ChatGPT von OpanAI, oder auch Gemini von Google usw., so ihre Tücken haben können, wenn es beispielsweise im andere oder um die eigenen Urheberrechte geht. In diesem Punkt unterscheiden wir uns in Europa durchaus von den US-amerikanischen und chinesischen Ansätzen. Siehe dazu Digitale Souveränität: Europa, USA und China im Vergleich. Darüber hinaus liegen die Daten der bekannten (closed source) LLMs zu einem überwiegenden Teil in englischer oder chinesischer Sprache vor.
„Multilingual, open source models for Europe – instruction-tuned and trained in all 24 EU languages…. Training on >50% non English Data. (…) This led to the creation of a custom multilingual tokenizer“ (ebd.).
Neben der freien Verfügbarkeit (Open Source AI) (via Hugging Face) ist somit ein großer Pluspunkt, dass eine große Menge an Daten, nicht englischsprachig sind. Das unterscheidet dieses Large Language Model (LLM) sehr deutlich von den vielen englisch oder chinesisch dominierten (Closed Source) Large Language Models.
Insgesamt halte ich das alles für eine tolle Entwicklung, die ich in der Geschwindigkeit nicht erwartet hatte!
Diese Website benutzt Cookies. Wenn du die Website weiter nutzt, gehen wir von deinem Einverständnis aus.