In dem Blogbeitrag Wisdom of Crowds – Schwarm Intelligenz – Kollektive Intelligenz bin ich schon einmal intensiver auf die Unterscheidung der jeweiligen Ansätze eingegangen. Darin zitiere ich Feldhusen (2021), der sich wiederum auf Lévy vom MIT Center of Collective Intelligence bezieht. Es lohnt sich, dessen Auffassung noch etwas genauer zu betrachten:
„Die Netzwerkgesellschaft wird nicht von einer Expertenintelligenz getragen, die für andere denkt, sondern von einer kollektiven Intelligenz, die die Mittel erhalten hat, sich auszudrücken. Der Anthropologe des Cyberspace, Pierre Lévy, hat sie untersucht: »Was ist kollektive Intelligenz? Es ist eine Intelligenz, die überall verteilt ist, sich ununterbrochen ihren Wert schafft, in Echtzeit koordiniert wird und Kompetenzen effektiv mobilisieren kann. Dazu kommt ein wesentlicher Aspekt: Grundlage und Ziel der kollektiven Intelligenz ist gegenseitige Anerkennung und Bereicherung …« (Lévy, 1997, S. 29). Um allen Missverständnissen zuvor zu kommen, richtet er sich ausdrücklich gegen einen Kollektivismus nach dem Bild des Ameisenstaates. Vielmehr geht es ihm um eine Mikrovernetzung des Subjektiven. »Es geht um den aktiven Ausdruck von Singularitäten, um die systematische Förderung von Kreativität und Kompetenz, um die Verwandlung von Unterschiedlichkeit in Gemeinschaftsfähigkeit« (ebd., S. 66)“ (zitiert in Grassmuck 2004).
L ÉVY, PIERRE (1997): Die Kollektive Intelligenz. Eine Anthropologie des Cyberspace, Bollmann Verlag, Mannheim.
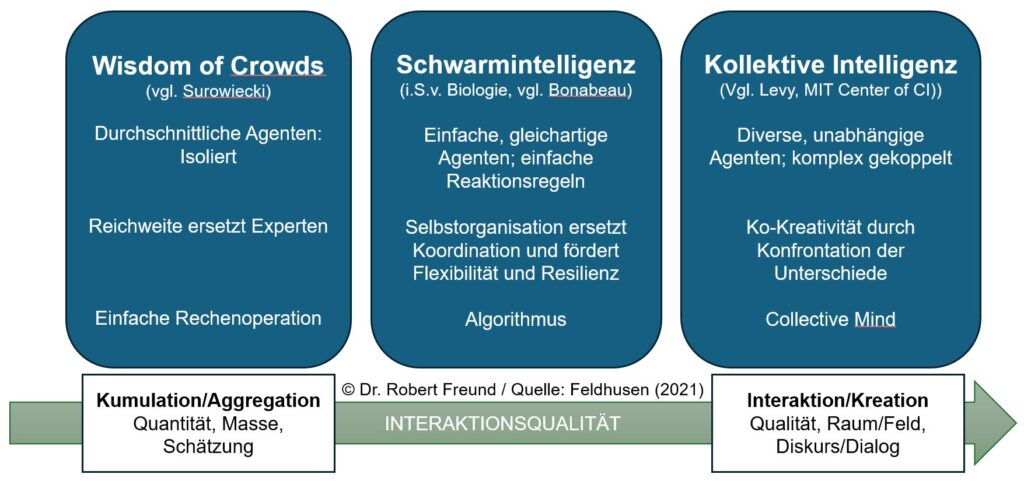
In der Grafik ist zu erkennen, dass es bei Kollektiver Intelligenz auch um diverse, unabhängige Agenten geht, die komplex gekoppelt sind. Aus der heutigen Perspektive können damit auch KI-Agenten im Netzwerk diverser Akteure gemeint sein. Auch in so einem Netzwerk würde es also nicht DIE Expertenintelligenz geben. Intelligenz (menschliche, künstliche, hybride Formen) würde sich also im Netzwerk verteilt, immer wieder neu bilden.
Um das zu erreichen, müssen allerdings Voraussetzungen erfüllt sein, die von den Tech-Konzernen mit ihren KI-Agenten manchmal „vergessen“ werden. Grundlage und Ziel der Kollektiven Intelligenz sind nach Lévy „gegenseitige Anerkennung und Bereicherung“. Bei diesen Punkten habe ich bei den proprietären KI-Modellen so meine Zweifel.