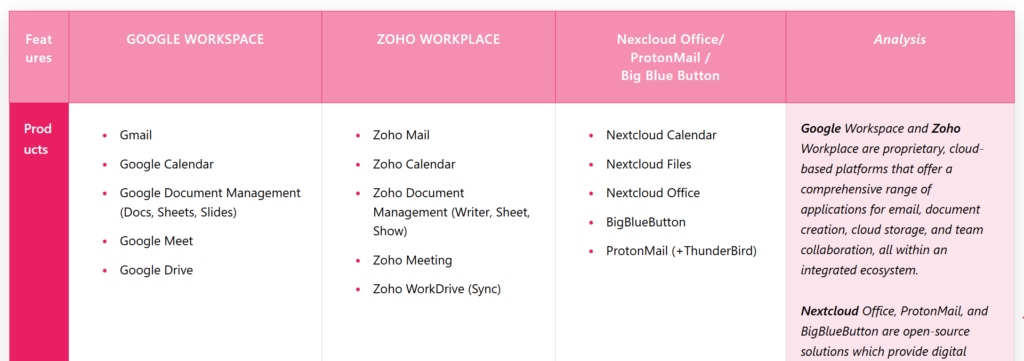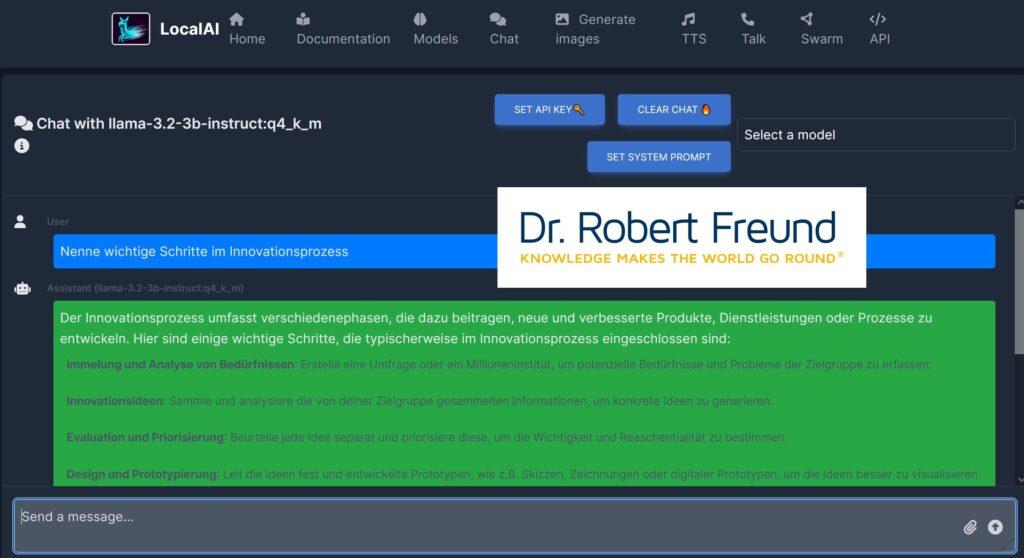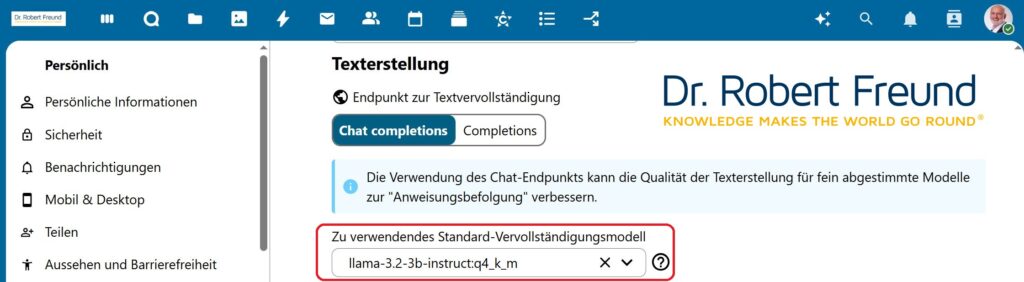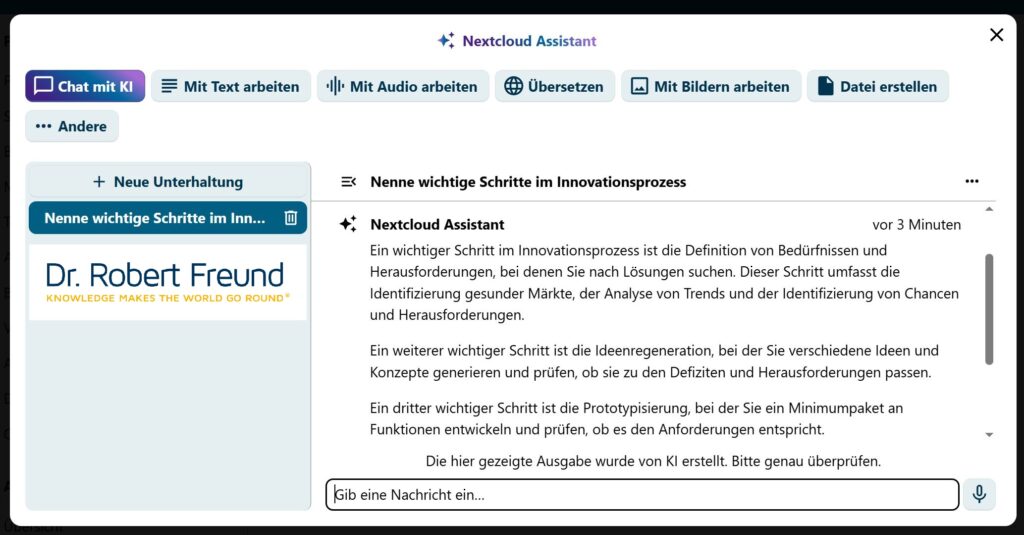
Über die Möglichkeiten, Open Source KI-Modelle auf dem eigenen Server zu betreiben habe ich in verschiedenen Blogbeiträgen schon geschrieben. Siehe dazu beispielsweise Digitale Souveränität: Wie kann ein KI-Modell aus LocalAI in den Nextcloud Assistenten eingebunden werden?
So ein System mit Nextcloud und LocalAI ermöglicht schon, autonom mit den eigenen Daten und Open Source KI-Modellen zu arbeiten. Dabei wird allerdings auch deutlich, dass es Abläufe gibt, die automatisiert werden können. Das kann durch Workflows oder KI-Agenten erfolgen. KI-Agenten sind im Gegensatz zu Workflows relativ eigenständig bei den Abläufen zur Problemlösung. Um das zu gewährleisten, und aufbauend auf Nextcloud und LocalAI, kann noch Local-AGI integriert werden.
Local-AGI ist eine auf LocalAI aufbauende Plattform, die speziell für autonome KI-Agenten entwickelt wurde. Es ermöglicht die Erstellung und Verwaltung von KI-Agenten, die Werkzeuge nutzen, Aufgaben autonom ausführen und sogar im Internet suchen können – alles lokal und ohne Cloud-Abhängigkeit. LocalAGI integriert LocalAI als Inferenz-Engine und bietet zusätzliche Funktionen wie eine Wissensdatenbank, Echtzeit-Überwachung und eine Benutzeroberfläche für die Agentenverwaltung (Quelle: GitHub).
LocalAI ist die Basis für lokale KI, während Local-AGI die Agenten-Funktionalität auf Basis von LocalAI bereitstellt. Beide Projekte sind modular und können gemeinsam genutzt werden, um komplexe, autonome KI-Systeme lokal zu betreiben.
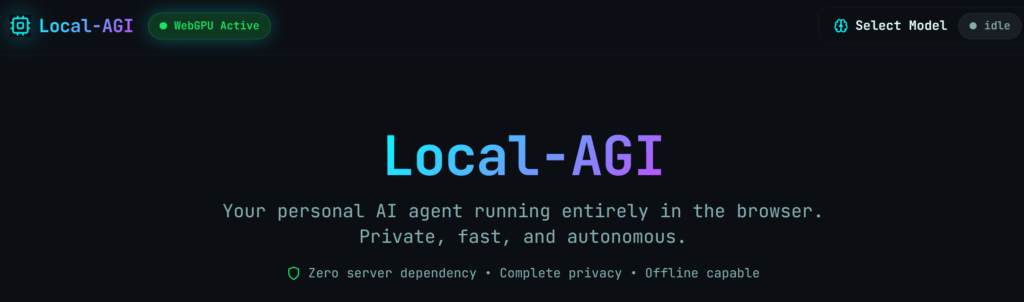
In der Abbildung oben ist die Startseite von Local-AGI zu sehen, auf der hinterlegte KI-Modelle im Browser direkt getestet werden können. Unter „Select Models“ sind einige wenige Modelle zu finden, die direkt heruntergeladen werden können. Ich habe das kleinste Modell LFM.5-350M ausgewählt, wobei das Modell im Browser gespeichert wurde, und folgende Eingabeseite erscheint:
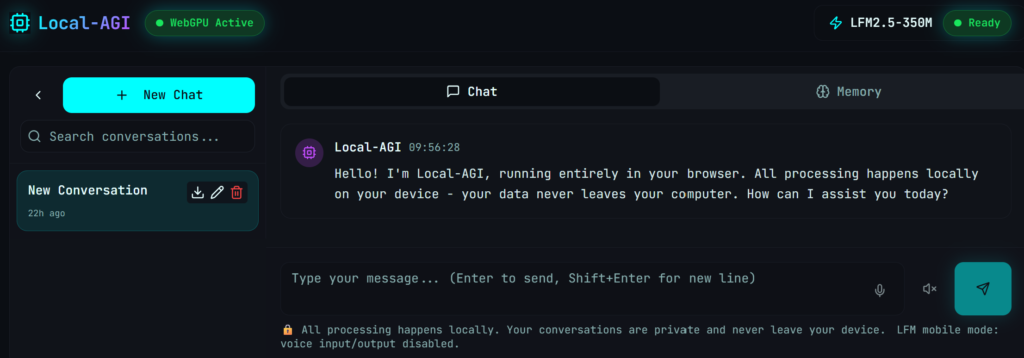
Hervorheben möchte ich noch einmal den Text, der gleich am Anfang des Chats erscheint: „Hello! I’m Local-AGI, running entirely in your browser. All processing happens locally on your device – your data never leaves your computer. How can I assist you today?“ Dieser Hinweis ist im Sinne einer eigenen Digitalen Souveränität wichtig.
Durch die Integration von Local-AGI mit LocalAI stehen weitere Modelle zur Verfügung. Im Unternehmen kommt es nicht darauf an, einzelne Anwendungen zu vergleichen, sondern darum, Digitale Souveränität und Resilienz in einem System mit Open Source Software und Open Source AI zu erreichen.