In den letzten Jahren wurden Open Source AI Modelle noch etwas belächelt, da sie zugegebenermaßen nicht an die Leistungsfähigkeit der proprietären AI-Modelle heranreichten. Wie die Beispiele DeepSeek R1, KIMI K3 oder auch Mistral AI zeigen, hat sich das geändert.
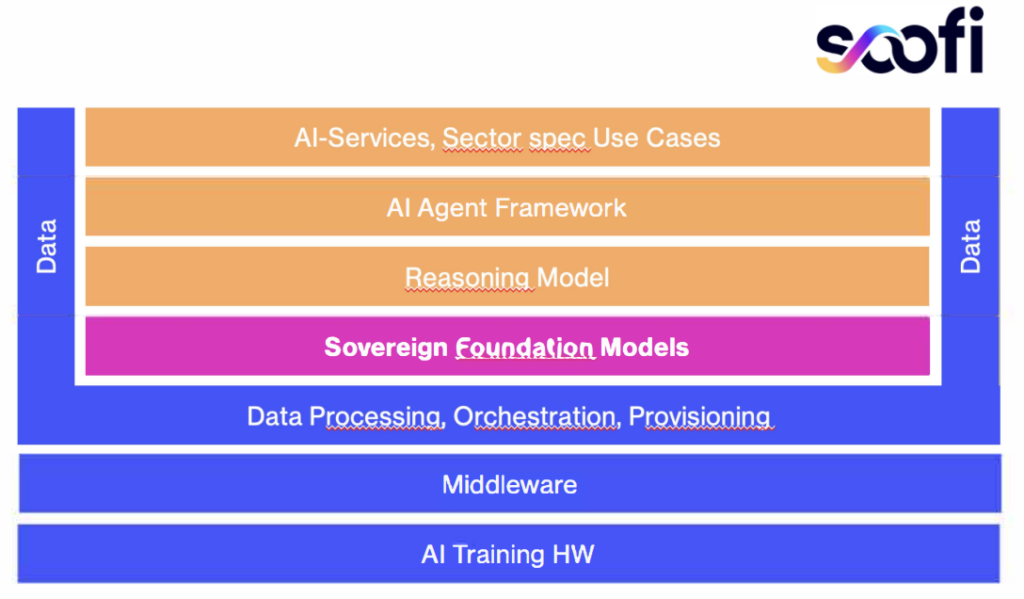
Hinzu kommt noch, dass neben der Leistungsfähigkeit noch andere Aspekte wichtig geworden sind: Digitale Souveränität und Resilienz. Betrachtet man alle Dimensionen, so wird klar, dass Open Source AI eine wichtige Rolle bei der modernen Transformation von Unternehmen und Gesellschaften spielen kann – besonders in Europa.
Am Beispiel Mistral AI, einem französischen Start-Up (2023 gegründet) wird deutlich, in welchem Spannungsfeld sich Open Source AI befindet. Mistral AI ist sehr erfolgreich und wird in Europa von immer mehr Privatpersonen, Unternehmen und Öffentlichen Verwaltungen genutzt. Das führt unweigerlich zu der Frage, wie Mistral AI die große Nachfrage bedienen kann. Das geht nur mit einer Skalierung, die Zeit und Geld kostet.
Um also den Markt schnell bedienen zu können braucht es Kapital und technologische Infrastruktur. Es wundert daher nicht, dass sich wohl Samsung an Mistral AI beteiligen möchte, und auch Microsoft KI-Infrastruktur bereitstellen will. Beides ist erst einmal positiv, doch hat das Beispiel OpenAI gezeigt, dass Microsoft Unternehmen, die zunächst Open Source AI angeboten haben, zu kommerziellen Unternehmen umwandeln kann. OpenAI entspricht nicht den Anforderungen, die in der Open Source AI Definition formuliert wurden.
Wir arbeiten schon länger mit Mistral AI Modellen und setzen darauf, dass das Unternehmen trotz der notwendigen Schritte zur Skalierung seine Unabhängigkeit und europäischen Ansatz beibehält. Wir werden den Weg von Mistral AI weiter beobachten.