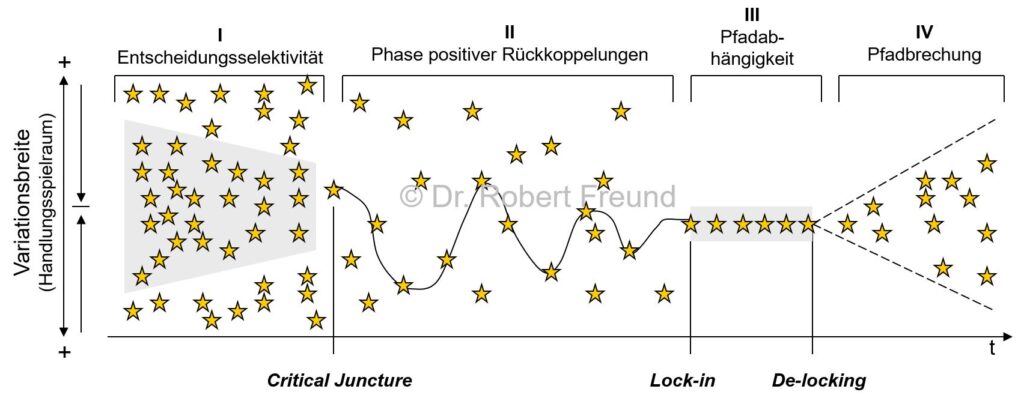
Wenn es um Komplexität und Künstliche Intelligenz geht, kommt man schnell zu der paradoxen Situation, dass Künstliche Intelligenz Komplexität einerseits reduzieren/bewältigen kann, andererseits aber auch selbst dazu beiträgt, Komplexität zu erhöhen.
Wie ich schon in vielen Beiträgen geschrieben habe, kommt es in komplexen Systemen – auch in KI-Systemen – zu Emergenz, d.h. zu einem neuen, überraschenden Verhalten, das nicht auf die ursprünglichen Komponenten im System zurückgeführt werden kann. Siehe dazu auch Komplexe Systeme: Ist die Antwort einfach mehr Daten?
Betrachten wir das Zusammenspiel von den aktuell überall diskutierten KI-Agenten, so können die Überlegungen auch dafür angewandt werden:
„Emergentes Verhalten – Komplexes, unerwartetes Verhalten, das aus der Interaktion vieler Agenten entsteht, ohne explizit programmiert zu sein“ (Mittelstand Digital, 2025).
Es erstaunt mich daher immer wieder, dass die bekannten Tech-Konzerne ihre proprietären KI-Systeme anpreisen unter der Überschrift, dass alles in irgendeiner Form kontrollierbar sei – das ist es eben nicht.
In der letzten Zeit ist es sogar so weit gekommen, dass die Veröffentlichung von neuen KI-Modellen von der amerikanischen Administration verboten oder eingeschränkt wurde, da nicht wirklich klar war, welche Auswirkungen die Veröffentlichung und Nutzung haben könnte: „Die US-Regierung hat die Nutzung der KI-Modelle Fable 5 und Mythos 5 von Anthropic aus Gründen der nationalen Sicherheit stark eingeschränkt“ (Tagesschau vom 13.06.2026).
Im Extremfall kann es daher sein, dass Gewinne aus den möglichen Komplexitäts-Reduzierungen (Effizienzsteigerungen) durch Künstliche Intelligenz bei den Konzernen bleiben, und die unübersehbaren Konsequenzen der auch vorhandenen Komplexitäts-Erhöhung sozialisiert werden – also von den Gesellschaften getragen und bezahlt werden müssen.
Es ist daher gut, das die Europäische Union nach Möglichkeiten sucht, neue Technologien zu fördern, gleichzeitig aber auch deren gesellschaftlichen Auswirkungen im Blick zu behalten. Siehe dazu auch Bris, A. (2025): SuperEurope: The Unexpected Hero of the 21st Century.