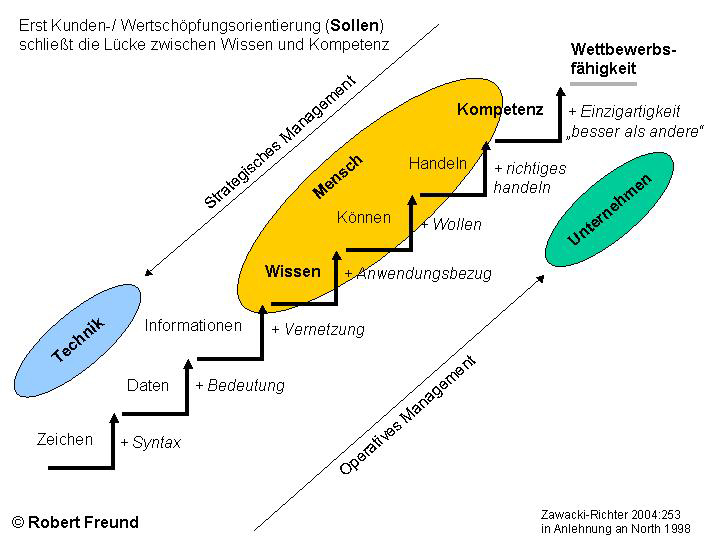
In der Vergangenheit wurden die Unterschiede zwischen Daten, Informationen und Wissen z.B. bei der erweiterten Wissenstreppe, bzw. bei dem noch besseren Verständnis der Wissenstreppe thematisiert.
Ein neuer Wissensbegriff führt heute jedoch zu neuen Wissensformen, zu denen auch das „Google-Wissen“ zählt, das wir (alle?) in irgendeiner Form nutzen. Doch was macht dieses „Google-Wissen“ aus? Dazu habe ich bei Arnold (2017) folgendes gefunden:
„Das sich verbreiternde Google-Wissen ist ein in hohem Maße dem Selbstlernen zugängliches Wissen. Es ermöglicht eine bislang unerreichte Aktualität im Detail (Stichwort „Evidenz“), ohne dass sich jedoch automatisch Expertise ergibt: Aus vielen Details resultiert keineswegs automatisch ein kohärentes Wissen, insbesondere, wenn es sich einem bloßen Surfen verdankt. Obgleich das Internet auch Zugänge zu Lernplattformen und anderen Selbstlernmöglichkeiten zunehmend offeriert, die durchaus auch eine Vertiefung von Expertise initiieren, anregen und gestalten können, darf doch andererseits nicht übersehen werden, dass aus solchen insularen Vertiefungen alleine wohl kaum ein professionell breit akzeptierter Status erwachsen kann“ (Arnold 2017; eigene Hervorhebungen).
Die angesprochene Evidenz meint hier, dass das „Google-Wissen“ für eine Sache geeignet erscheint – viabel ist, was der Autor noch weiter beschreibt/charakterisiert. Interessant dabei ist auch die am Ende erwähnte Kritik an den eher inselartigen Vertiefungen des Wissens.




 Die
Die