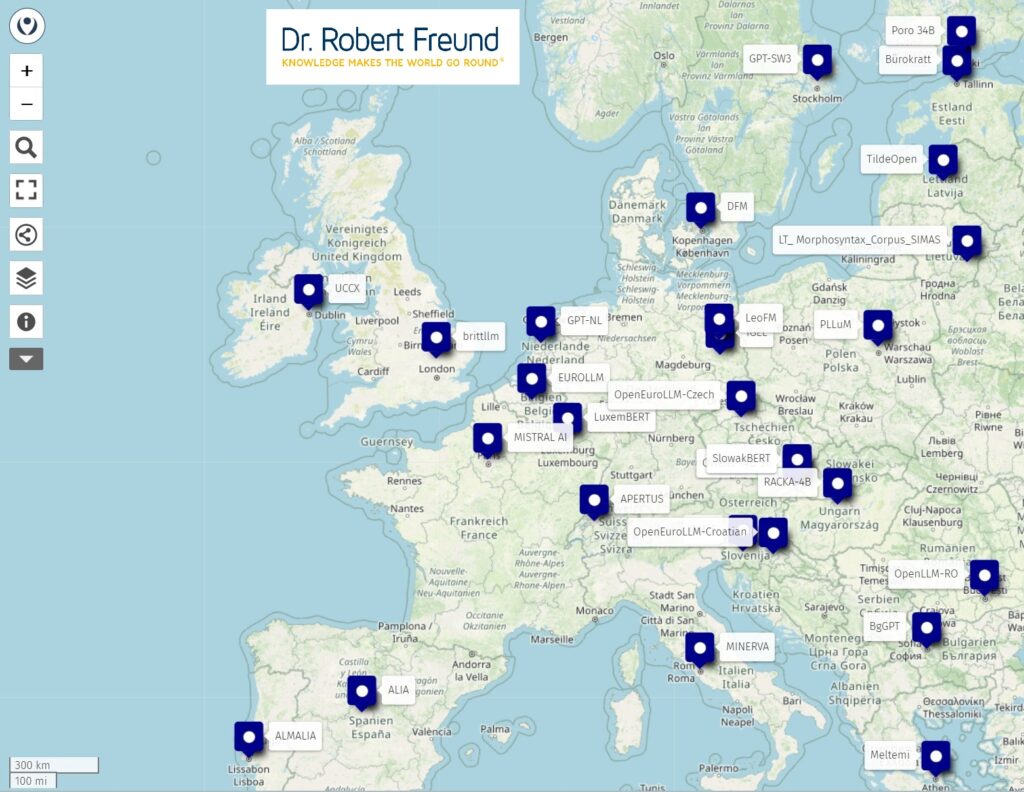
In dem Beitrag Open Street Map: Europäische Open Source KI Modelle in den jeweiligen Landessprachen hatte ich verschiedene, in den jeweiligen europäische Landessprachen entwickelten KI-Modelle in einer Map positioniert, inkl. der jeweiligen Links.
Ein Sonderfall stellt SOOFI (Sovereign Open Source Foundation Models) dar. Hier geht es zwar auch um den Open Source Ansatz, doch speziell für die Industrie. Weiterhin liegt der Schwerpunkt auf den Sprachen Englisch und Deutsch.
Da wir in Deutschland stark industriell-technologisch ausgerichtete Branchen haben, stößt diese Entwicklung auf reges Interesse. Von dem SOOFI-Team wurde von Anfang an kommuniziert, dass es einen Vprab-Test des Modells in der Industrie geben wird, und die Community Verbesserungen vorschlagen kann – genau das ist passiert. Das Erkennen von Schwachstellen durch die Community ist also keine Schwäche des Modells, sondern eine Stärke des Open Source Ansatzes.
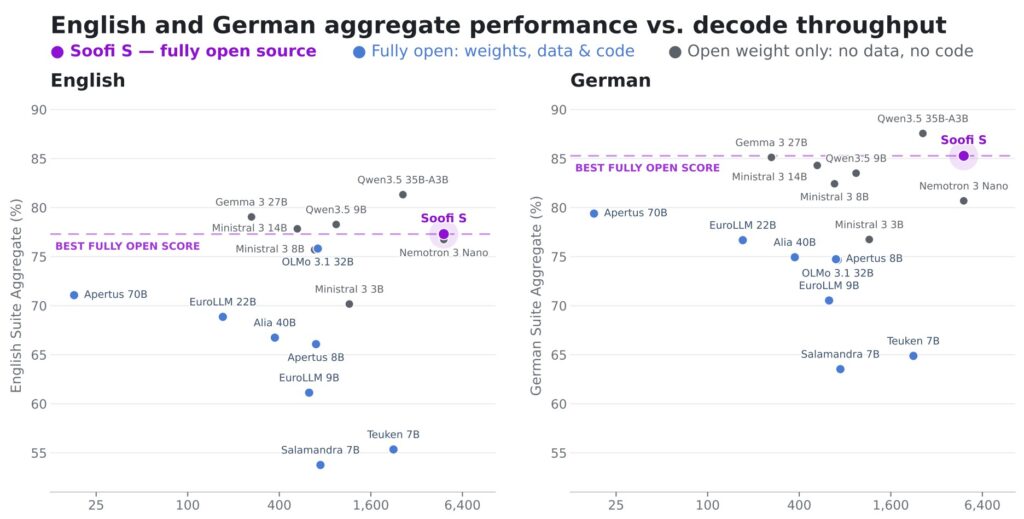
Eine Veröffentlichung des SOOFI-Teams aus dem Juli 2026 zeigt die aktuelle Performance des Modells im Vergleich mit anderen Open Source Modellen (Abbildung). Für mich interessant ist, dass sich diese Modelle zu 90% in der von mir erstellen MAP wiederfinden.
Das SOOFI-Modell ist (1) offen, (2) fokussiert auf die deutsche Sprache im industriellen Kontext, und (3) wirtschaftlich. Alle drei Faktoren machen SOOFI für deutsche Unternehmen aus der Industrie so wertvoll.
„Soofi S 30B-A3B addresses all three at once: It is a Mixture-of-Experts (MoE) hybrid Mamba Transformer trained to excel in both German and English and will be released radically open: not weights alone, but the full set of artifacts required to audit every stage of training and, where source licenses permit, rebuild the data mixture, in the spirit of recent fully open efforts“
Source: Droste et al. (2026) A Sovereign, Open-Source Foundation Model for German and English. Available from https://arxiv.org/abs/2607.09424 [Accessed 03.08.2026].
Auf der internationalen Konferenz MCP 2026 (16.-19.09.2026, Balatonfüred, Ungarn) gehe ich auf diese Zusammenhänge in zwei meiner Paper ein.