In allen Projekten werden mehr oder weniger oft digitale Tools, bzw. komplette Kollaborationsplattformen eingesetzt. Hinzu kommen jetzt immer stärker die Möglichkeiten der Künstlicher Intelligenz im Projektmanagement (GenAI, KI-Agenten usw.).
Projektverantwortliche stehen dabei vor der Frage, ob sie den KI-Angeboten der großen Tech-Konzerne vertrauen wollen – viele machen das. Immerhin ist es bequem, geht schnell und es gibt auch gute Ergebnisse. Warum sollte man das hinterfragen? Möglicherweise gibt es Gründe.
Es ist schon erstaunlich zu sehen, wie aktuell Mitarbeiter ChatGPT, Gemini usw. mit personenbezogenen Daten (Personalwesen) oder auch unternehmensspezifische Daten (Expertise aus Datenbanken) füttern, um schnelle Ergebnisse zu erzielen – alles ohne zu fragen: Was passiert mit den Daten eigentlich? Siehe dazu auch Künstliche Intelligenz: Würden Sie aus diesem Glas trinken?
Je innovativer ein Unternehmen ist, desto einzigartiger sind seine Daten. Was mit diesen Daten dann passiert, ist relativ unklar. Es wundert daher nicht, dass nur ein kleiner Teil der Unternehmensdaten in den bekannten LLM (Large Language Models) zu finden ist. Siehe dazu Künstliche Intelligenz: 99% der Unternehmensdaten sind (noch) nicht in den Trainingsdaten der LLMs zu finden.
Es stellt sich zwangsläufig die Frage, wie man diesen Umgang mit den eigenen Daten und das dazugehörende Handeln bewertet. An dieser Stelle kommt der Begriff Ethik ins Spiel, denn Ethik befasst sich mit der „Bewertung menschlichen Handelns“ (Quelle: Wikipedia). Dazu passt in Verbindung zu KI in Projekten folgende Textpassage:
„In vielen Projektorganisationen wird derzeit intensiv darüber diskutiert, welche Kompetenzen Führungskräfte in einer zunehmend digitalisierten und KI-gestützten Welt benötigen. Technisches Wissen bleibt wichtig – doch ebenso entscheidend wird die Fähigkeit, in komplexen, oft widersprüchlichen Entscheidungssituationen eine ethisch fundierte Haltung einzunehmen. Ethische Kompetenz zeigt sich nicht nur in der Einhaltung von Regeln, sondern vor allem in der Art, wie Projektleitende mit Unsicherheit, Zielkonflikten und Verantwortung umgehen“ (Bühler, A. 2025, in Projektmanagement Aktuell 4/2025).
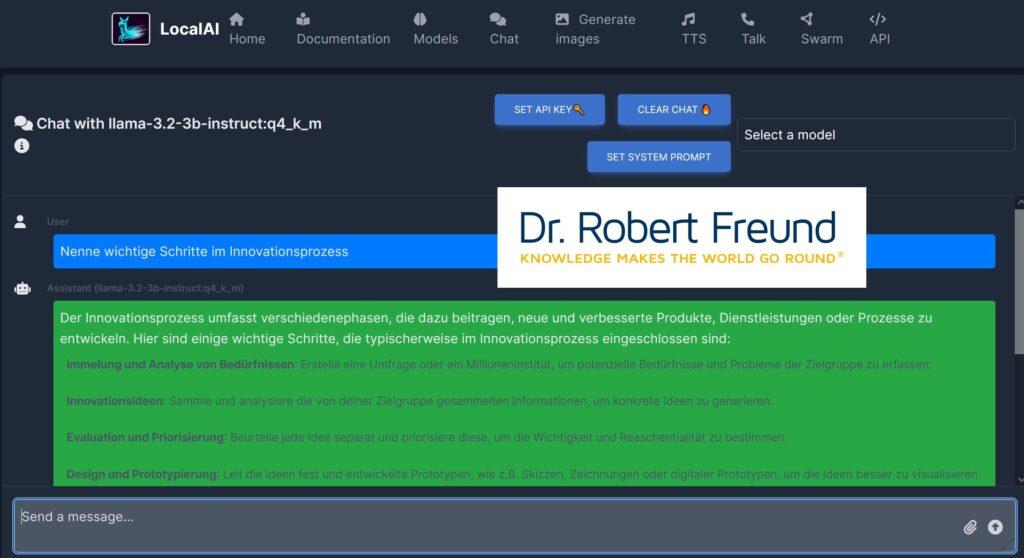
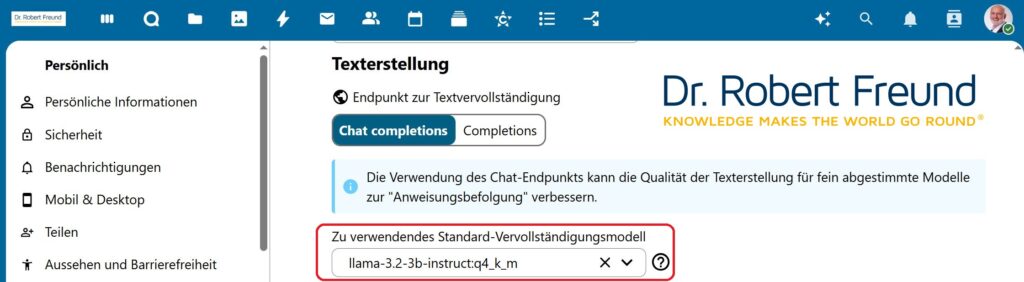
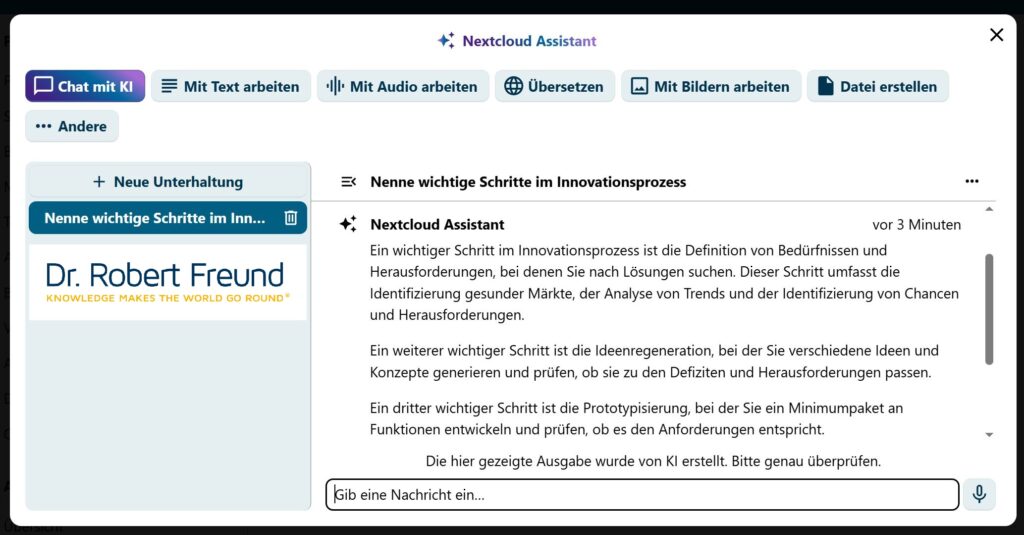
Unsere Idee ist daher, eine immer stärkere eigene Digitale Souveränität – auch bei KI-Modellen. Nextcloud, LocalAI, Ollama und Langflow auf unseren Servern ermöglichen es uns, geeigneter KI-Modelle zu nutzen, wobei alle generierten Daten auf unseren Servern bleiben. Die verschiedenen KI-Modelle können farbig im Sinne einer Ethical AI bewertet werden::