Die Frage in meiner Blogüberschrift erscheint auf den ersten Blick etwas seltsam. Immerhin kommunizieren wir als Menschen doch permanent, oder? Schauen wir uns Kommunikation noch etwas genauer an, so ist die Frage gar nicht so leicht zu beantworten.
Bei Kommunikation geht es um den“ Austausch oder die Übertragung von Informationen“(Wikipedia). Dabei gibt es viele Facetten. die vom einfachen Sender-Empfänger-Modell, über die verschiedenen Ebenen von menschlicher und digitaler Kommunikation, bis hin zur Einordnung von Kommunikation in komplexen sozialen Systemen reichen.
Bei der Systembetrachtung gibt es Ansichten (z.B. von Luhmann), die der allgemeinen Auffassung von Kommunikation widersprechen. Die Systemtheorie von Niklas Luhmann geht zunächst einmal von der Kommunikation (nicht von Handlungen) aus und davon, dass „die Strukturen der Kommunikation in weitgehend allen sozialen Systemen vergleichbare Formen aufweisen“ (ebd.). Kommunikation ist also, so Luhmann, kein Ergebnis menschlichen Handelns, sondern ein Produkt sozialer Systeme (vgl. Dewe 2010).
Das gipfelt in der Aussage: „Der Mensch kann nicht kommunizieren, nur die Kommunikation kann kommunizieren“ (Krieger / Nassehi 1993:56).
Soziale Systeme tauschen also Informationen selbstreferentiell aus – sie kommunizieren, ohne dass der Mensch dafür erforderlich ist.
Der Mensch ist nach Luhmann konsequenterweise kein Bestandteil der sozialen Systeme, sondern Bestandteil der Umwelt. Die System-Umwelt-Kopplung macht die Kommunikation möglich. Wie am Anfang schon angedeutet, sind die Zusammenhänge nicht so einfach zu verstehen. Siehe dazu auch Künstliche Intelligenz: System – Umwelt – Mensch.
Vor fast 20 Jahren haben wir den Blog mit WordPress (Open Source) gestartet – ohne Webebanner oder versteckter Werbung. Das ist auch heute noch so.
Von Anfang an haben wir Wert auf Qualität der Beiträge gelegt, indem wir beispielsweise Originaltexte mit Quellen angegeben, und dadurch von unserer Meinung abgegrenzt haben.
In der Zwischenzeit werden wir alle von KI generierten Inhalten überschwemmt. Da ist es aus unserer Sicht gut, mehr auf Qualität, als auf Quantität zu setzen. Ganz im Sinne von unserer Marke:
Die verwendete Sprache, und hier speziell die verwendeten Begriffe, lassen oft Rückschlusse auf die dazugehörende Denkweise (Mindset) zu. Beispielsweise ist die Metapher „Unternehmen als Maschine“ oder „Menschen sind Zahnräder“ sinnbildlich für eine sehr mechanistische Denkweise, die heute in vielen Bereichen nicht mehr angemessen erscheint.
Der Begriff „Verbraucher“ hat eine ähnliche Wirkung. In vielen Meldungen, Statistiken usw. wird immer noch der Begriff verwendet, gerade so, als ob alle Produkte und Dienstleistungen verzehrt werden, also einer Abnutzung unterliegen.
„Verbrauch ist in der Wirtschaftstheorie der Verzehr von Gütern und Dienstleistungen zur direkten oder indirekten Bedürfnisbefriedigung. Ein Synonym für Verbrauch ist Konsum“ (Quelle: Wikipedia) Bei einem Acker ist das so, da hier die Fläche begrenzt, und nicht so einfach erweiterbar ist. Es leuchtet daher ein, dass versucht wird, das „maximale aus dem Boden herauszuholen“.
Bei digitalen Produkten ist das etwas anders. Auf das eben beschriebene Beispiel angewendet bedeutet das: „Der digitale Acker ist ein Zauberhut, aus dem sich ein Kaninchen nach dem anderen ziehen lässt, ohne dass er jemals leer würde. Die »Verbraucher« von Informationsgütern »verbrauchen« ja eben gerade nichts“ (Grassmuck 2004, Bundeszentrale für politische Bildung (bpb), 2., korrigierte Auflage).
In einer immer stärker digitalisierten Welt, werden digitale Produkte und Dienstleistungen durch deren Nutzung nicht „verbraucht“, sondern ganz im Gegenteil: Durch die Nutzung von Daten und Informationen entstehen wieder viele neue Daten, die dann oftmals von Unternehmen wertschöpfend genutzt werden. Daten sind für diese Unternehmen das neue Öl.
Im Zusammenhang mit digitalen Produkten (Daten, Informationen, Wissen) sollten wir daher nicht mehr von „Verbraucher“ sprechen, da der Begriff einfach nicht mehr passt.
Die nächste internationale Konferenz MCP 2026 zu Customization and Personalization findet vom 16.-19.09.2026 in Balatonfüred, Ungarn statt. Die MCP Community of Europe trifft sich zum Austausch der verschiedenen Perspektiven auf das Thema. Seit 2004 ist das die 12. Konferenz, die durchgehend alle 2 Jahre durchgeführt wird.
12th International Conference on Customization and Personalization
7th Doctoral Students Workshop
4th Professionals Panels & MEA KULMA Innovation Festival
Conference Abstract Submission Deadline: March 31, 2026.
Sprechen Sie mich gerne an, wenn Sie Fragen zur Konferenz haben. Wir werden auch dabei sein.
Auf den verschiedenen Konferenzen, an denen ich teilgenommen habe, ging es über viele Jahre um Mass Customization and Personalization. Auslöser der Entwicklung war die Veröffentlichung B. Joseph Pine II (1992): Mass Customization. The New Frontier in Business Competition, in der die damals neue hybride Wettbewerbsstrategie vorgestellt wurde.
In der Zwischenzeit gibt es beim Fraunhofer Institut in Stuttgart das Leistungszentrum Mass Personalization. Dort ist man der Auffassung, dass es sich bei Mass Personalization um einen Megatrend handelt
„Mass Personalization ist ein eigenständiges radikal nutzerzentriertes und dennoch nachhaltiges und ressourceneffizientes Konzept, das als Toolbox oder plattformtechnologische Anwendung in der Produktion von morgen fungieren kann“ (Krieg/Groß/Bauernhansl (2024) (Hrsg.): Einstieg in die Mass Personalization. Perspektiven für Entscheider).
Mass Customization ist hier zeitpunktbezogen, und Mass Personalization eher Zeitdauer bezogen zu interpretieren. Beides, Mass Customization und Mass Personalization, sind allerdings immer noch aus der Perspektive des Unternehmens gedacht.
Wenn sich ein Unternehmen auf jeden einzelnen Nutzer so intensiv einstellen will, benötigt es viele Problem- und möglicherweise auch erste Lösungsinformationen vom Nutzer. Bei komplexen Problemen sind diese Informationen nur sehr schwer zu beschreiben (Kontext, Implizites Wissen, Expertise), und schwer vom Nutzer zum Unternehmen übertragbar (Sticky Information, Träges Wissen).
Der Nutzer weiß oft am besten, was er für sein Problem benötigt. Es fehlt oft noch der Schritt zur ersten Umsetzung von eigenen Lösungen. Dieser war in der Vergangenheit sehr aufwendig (Zeit, Geld), sodass die Umsetzung oft von Unternehmen übernommen wurde.
In der Zwischenzeit gibt es durch die Möglichkeiten der Künstlichen Intelligenz, des 3D-Drucks (Additive Manufacturing), oder auch der Robotik und der Open Source Community viele Möglichkeiten, das Produkt selbst zu entwickeln und im Idealfall selbst oder in einer Community herzustellen. Siehe Eric von Hippel (2016): Free Innovation (Open Access).
Titel (Ausschnitt) https://direct.mit.edu/books/book/5344/Free-Innovation
Eric von Hippel hat dazu schon sehr viele Studien veröffentlich, aus denen hervorgeht, dass der Anteil dieser Open User Innovation in den letzten Jahrzehnten stark angewachsen ist. Diese Innovationen findet man nicht in den offiziellen Statistiken zu Innovationen, denn Innovationen werden dort von Unternehmen entwickelt und auf den Markt gebracht. Was versteht nun von Hippel unter Open User Innovation?
„An innovation is ´open´ in our terminology when all information related to the innovation is a public good—nonrivalrous and nonexcludable”(Baldwin and von Hippel 2011:1400).
”… involves contributors who share the work of generating a design and also reveal the outputs from their individual and collective design efforts openly for anyone to use“ (Baldwin and von Hippel 2011:1403).
Wir wissen alle, dass die Unternehmen nur die Innovationen auf den Markt bringen, die eine entsprechende Rendite versprechen – alles andere bleibt liegen… Doch genau darin liegt die Chance von Open User Innovation: Jeder einzelne kann nicht nur kreativ, sondern auch innovativ sein (Ideen umsetzen) und seine Innovationen anderen (auch kostenlos) zur Verfügung stellen.
Sie meinen das gibt es nicht? Dann schauen Sie sich einmal die vielen Plattformen zu Open Source Software, oder die Plattform Patient Innovation an – Sie werden staunen.
Wenn Sie sich zu diesen Themen informieren wollen: Die MCP Community of Europe trifft sich auf der Konferenz zu Mass Customization and Personalization – MCP 2026 – vom 16.-19.09.2026 in Balatonfüred, Ungarn. Wir sind dabei.
Wir haben uns alle mehr oder weniger daran gewöhnt, die verschiedenen Apps von Google zu nutzen. Ob es der Browser Chrome ist, Google Drive, etc. oder auch Google Maps . Wie ich schon in mehreren Beiträgen geschrieben habe, kommt es bei den scheinbar kostenlosen Apps (wir zahlen mit unseren Daten) von Google, Microsoft und Co. nach einer Phase der Gewöhnung zu einem Lock-in. Diese Pfadabhängigkeit wird dann genutzt, um die bisherigen Gewohnheiten einzuschränken oder kostenpflichtig zu stellen.
Google Maps sieht die Zeit gekommen, bisher verfügbare Informationen auf den gewohnten Karten zu reduzieren, wenn man sich nicht mit dem Google Konto angemeldet hat. Der Hintergrund wird in dem Artikel Google Maps ohne Anmeldung nur noch eingeschränkt nutzbar (Pakolski 2026, auf Golem.de) ausführlicher dargestellt.
„Google schränkt den vollen Funktionsumfang von Google Maps weiter ein, wenn Anwender sich nicht mit einem Google-Konto anmelden. Wird Google Maps etwa im Browser ohne Anmeldung genutzt, fehlen alle Rezensionen und Bilder zu Restaurants, Geschäften oder Touristenattraktionen“ (ebd.).
Was kann man machen? Sich ärgern, und sich in Zukunft immer mit dem Google Konto anmelden? Das ist der bequeme Weg, den man mit seinen Daten „bezahlt“. Alles andere bedeutet einen Aufwand (Switching Costs), ja. Genau das ist das Kalkül von Google (und anderen).
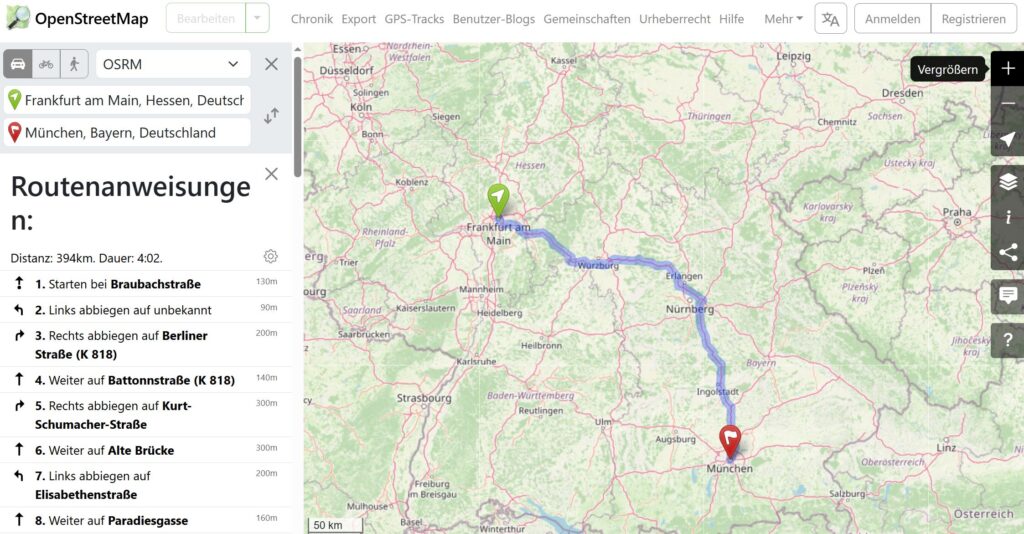
Es gibt allerdings auch die Möglichkeit, sich von solchen Anwendungen nach und nach zu emanzipieren, und digital souveräner zu werden. Bei dem Beispiel Google Maps gibt es die Open Source Alternative OpenStreetMap (OSM). Folgende Informationen sind bei OSM-About zu finden:
OpenStreetMap stellt Kartendaten für tausende von Webseiten, Apps und andere Geräte zur Verfügung.
OpenStreetMap legt Wert auf lokales Wissen. Autoren benutzen Luftbilder, GPS-Geräte und Feldkarten zur Verifizierung, sodass OSM korrekt und aktuell ist.
Ja, OpenStreetMap ist gewöhnungsbedürftig, doch sollte jeder abwägen, ob er aus Bequemlichkeit kurzfristig eine digitale Abhängigkeit, oder eher mittelfristig eine Digitale Souveränität möchte.
Wenn wir heute über Medien sprechen oder schreiben, geht es meistens um Digitale Medien. Der althergebrachte Gedanke, dass Digitale Medien eher neutral sind, und nur Botschaften übermitteln, ist heute nicht mehr zeitgemäß. Denn ganz nach McLuhan (1968) ist das Medium die Botschaft. Was heißt das?
„Für eine medienwissenschaftliche Betrachtung Digitaler Medien ist der von dem kanadischen Medienwissenschaftler Marshall McLuhan formulierte Medienbegriff relevant, wie er in dem häufig zitierten Satz „the medium is the message“ (McLuhan 1968:15) zum Ausdruck kommt. Die Botschaft eines Mediums ist nach McLuhan die „Veränderung des Maßstabs, Tempos, Schemas, die es der Situation der Menschen bringt“ (ebd.: 22). Das heißt, dass Medien unabhängig vom transportierten Inhalt neue Maßstäbe setzen (ebd.: 21). Digitale Medien setzen im Bereich der Informations-, Kommunikations-, Arbeits- und Lernmöglichkeiten neue Maßstäbe. Der McLuhan’sche Medienbegriff steht im Kontrast zu einem Medienverständnis, wonach Medien neutral sind und lediglich als Übermittler von Botschaften dienen“.
Quelle: Carstensen, T. Schachtner, C.; Schelhowe, H.; Beer, R. (2014): Subjektkonstruktion im Kontext Digitaler Medien. In: Carstensen, T. (Hrsg.) (2014): Digitale Subjekte. Praktiken der Subjektivierung im Medienumbruch der Gegenwart.
Gerade in Zeiten Künstlicher Intelligenz geht es daher nicht alleine um den Content, sondern auch darum, dass KI-Modelle neue Maßstäbe setzen. Gerade dieser Effekt von KI ist bei Verlagen, in der Musikbranche, bei Psychologen, Ärzten, usw. deutlich zu erkennen. Dabei ist auch der Hinweis von McLuhan wichtig, dass dadurch auch die Neutralität dieser Digitalen Medien verlorengeht.
KI-Modellen, mit den darin enthaltenen Ansichten zum Menschenbild,, zur Gesellschaftsformen usw., werden zu starken Beeinflusser von Individuen, die erst durch „das Gegenüber“ und durch Kontexte zu einem „Ich“ wird.
„Wer bin ich ohne die anderen? Niemand. Es gibt mich nur so, in einem Zusammenhang mit Menschen, Orten und Landschaften“ (Marica Bodroži 2012:81).
Conceptual technology illustration of artificial intelligence. Abstract futuristic background
Für komplexe Problemlösungen ist es wichtig, implizites Wissen zu erschließen. Wenig überraschend stellt Polanyi daher die Meister-Lehrling-Beziehung, in der sich Lernen als Enkulturationsprozess vollzieht, als essentielles Lern-Lern-Arrangement heraus:
„Alle Kunstfertigkeiten werden durch intelligentes Imitieren der Art und Weise gelernt, in der sie von anderen Personen praktiziert werden, in die der Lernende sein Vertrauen setzt“ (PK, S. 206). (Neuweg 2004).
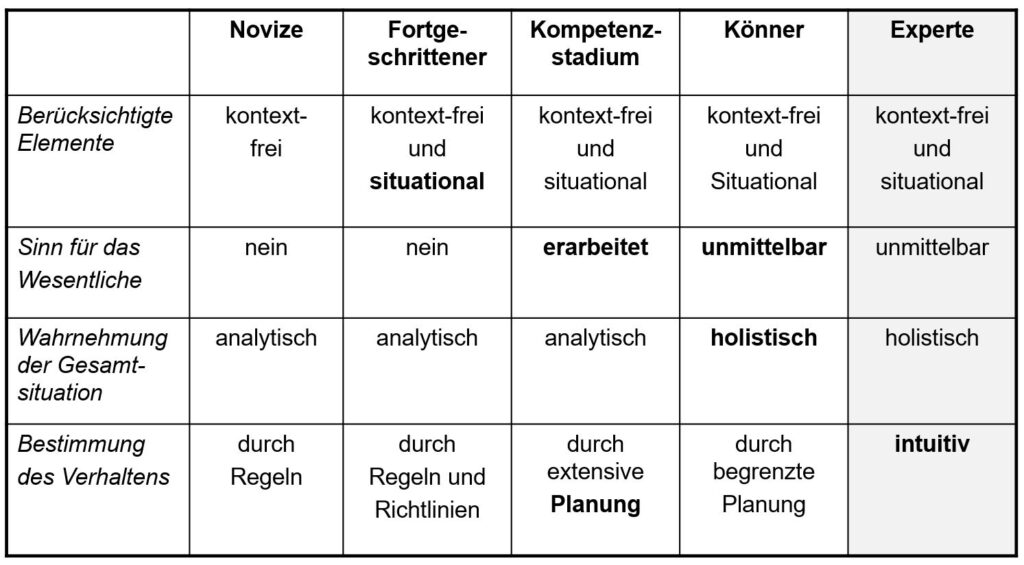
Das setzt auch die Anerkenntnis der Autorität des Experten voraus. Nach Dryfus/Dryfus ergeben sich vom Novizen bis zum Experten folgende Stufen der Kompetenzentwicklung:
Das Modell des Fertigkeitserwerbs nach Dreyfus/Dreyfus (Neuweg 2004)
Wenn wir uns nun die Beziehung zwischen Künstlicher Intelligenz und dem (nutzenden) Menschen ansehen, so kann diese Beziehung oftmals wie eine Meister-Lehrling-Beziehung beschrieben werden.
Dabei ist die „allwissende“ Künstliche Intelligenz (z.B. in Form von ChatGPT etc.) der antwortende Meister, der die Fragen (Prompts) des Lehrlings (Mensch) beantwortet. Gleichzeitig wird vom Lehrling (Mensch) die Autorität des Meisters (ChatGPT) anerkannt. Dieser Aspekt kann dann allerdings auch für Manipulationen durch die Künstliche Intelligenz genutzt werden.
Ein weiterer von Polanyi angesprochene Punkt ist das erforderliche Vertrauen auf der Seite des Lernenden in den Meister. Kann ein Mensch als Nutzer von Künstlicher Intelligenz Vertrauen in die KI-Systeme haben? Siehe dazu Künstliche Intelligenz – It All Starts with Trust.
Gerade wenn es um komplexe Probleme geht hat das Lernen von einer Person, gegenüber dem Lernen von einer Künstlichen Intelligenz, Vorteile. Die Begrenztheit von KI-Agenten wird beispielhaft auf der Plattform Rent a Human deutlich, wo: KI-Agenten Arbeit für Menschen anbieten, denn
Über Wissen, und den Umgang mit Wissen, habe ich schon sehr viele Beiträge geschrieben (Kategorie: Wissensmanagement). In diesem Beitrag soll es noch einmal um den Bezug zwischen Wissen und Handeln gehen.
Dabei kann Wissen nach Nico Stehr (2000:81) als Handlungsvermögen, als„ Fähigkeit zum sozialen Handeln“ definiert werden (Stehr 2000).
Durch neue Technologien, wie z.B., der Künstlichen Intelligenz, und die vielfältigen Vernetzungsmöglichkeiten in der heutigen Welt, entsteht eine große Fülle an Wissen und Nicht-Wissen, das wiederum zu sehr vielen Handlungsoptionen unter Unsicherheit führt.
Es wundert daher nicht, dass heute eine Kompetenz erforderlich ist, die hilft, unter Unsicherheit zu entscheiden. Es geht also nicht „nur“ um das Wissen, sondern auch um die richtige Entscheidung. Es deutet sich hier schon an,
„(…) dass das Lernen von Wissen weitgehend ersetzt werden müsste durch das Lernen des Entscheidens, das heißt: des Ausnutzens von Nichtwissen“ (Luhmann 2002: 198, zitiert in Kurtz, T. 2010).
Die MCP Community of Europe trifft sich in diesem Jahr vom 16.-19.09.2026 auf der MCP 2026 in Balatonfüred, Ungarn. Neueste Entwicklungen zu Mass Customization and Personalization, auch in Zeiten von Künstlicher Intelligenz, werden auf der Konferenz vorgestellt und diskutiert. Die Konferenz findet seit 2004 durchgehend alle 2 Jahre statt – die MCP 2026 ist somit die 12. Konferenz ihrer Art.
Begleitend findet vor der Konferenz der 7. Doktoranden-Workshop (DSW 2026), und nach dem Konferenz-Teil das 4. Pro Panel Idea Sharing (Pro Forum MEA KULMA 2026) statt. Es ist ein spannendes Angebot für Wissenschaftler und Praktiker, um sich mit Experten auf dem Gebiet Customization und Personalization auszutauschen.
In der MCP Week gibt es natürlich auch viele Möglichkeiten des Networkings. Auf der Konferenz-Website MCP 2026 finden Sie ausführliche Informationen zu den vergangenen Konferenzen und zur Location.
Abstracts können Sie bis zum 31.03.2026 einreichen.
Bei Fragen können Sie mich gerne ansprechen. Wir (Jutta und ich) werden selbstverständlich im September mit dabei sein.
Diese Website benutzt Cookies. Wenn du die Website weiter nutzt, gehen wir von deinem Einverständnis aus.