Langflow ist Open Source basiert und bietet die Möglichkeit, einfache Flows oder auch komplexere KI-Agenten per Drag & Drop zu erstellen.
„Langflow is a powerful tool to build and deploy AI agents and MCP servers. It comes with batteries included and supports all major LLMs, vector databases and a growing library of AI tools“ (Langflow-Website).
Wir haben Langflow auf einem Server installiert, und einige Tests dazu durchgeführt – inkl. der Nutzung von Ollama. Unser Ziel ist es mit einfachen Tools, die Open Source basiert sind und kleine, frei verfügbare Trainingsmodelle (Small Language Models) zu nutzen. Siehe dazu unsere Blogbeiträge zu Langflow.
In diese Richtung geht nun auch die Möglichkeit, Langflow auf dem eigenen Desktop zu nutzen. Dazu kann man sich auf dieser Website die App herunterladen und installieren.
Der Vorteil liegt auf der Hand: Es ist kein Server erforderlich, auf dem Langflow installiert werden muss. Der Nachteil ist allerdings auch klar: Je nach Hardware-Ausstattung des eigenen Desktops sind die Möglichkeiten zur Nutzung größerer Modelle (Large Language Models) noch begrenzt. Wir werden es auf jeden Fall einmal ausprobieren.
Im Netz sind auch Personen unterwegs, deren Identität nicht bekannt ist. Für manche ist es der Schutz ihrer persönlichen Privatsphäre, für andere bietet Anonymität im Netz die Möglichkeit, Beiträge zu verfassen, die andere diffamieren.
Forscher von der ETH Zürich, MATS Research und Anthropic sind einmal der Frage nachgegangen, ob es mit den Möglichkeiten der Künstlichen Intelligenz in großem Maßstab möglich ist, zu de-anonymisieren. In dem Paper von Lermen et al. (2026) wurde die Vorgehensweise und die Ergebnisse ausführlich dargestellt.
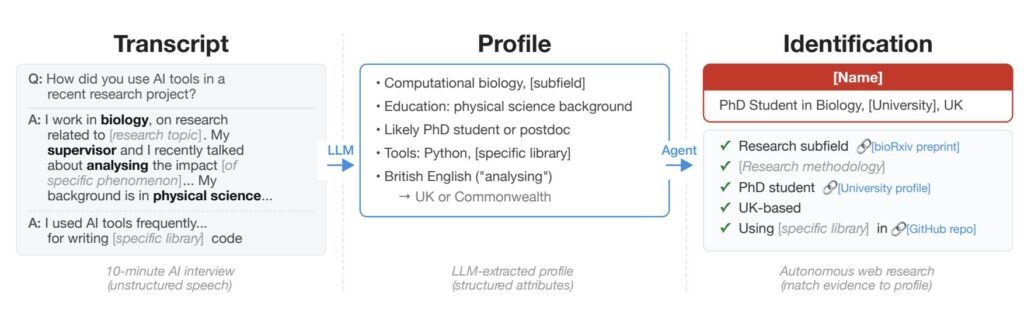
Die Abbildung zeigt, wie aus einem einzelnen Interview mit Hilfe eines Large Language Models (LLM) ein Profil erstellt wurde, und abschließend ein KI-Agent die Person identifizieren konnte.
„End-to-end deanonymization from a single interview transcript from (details altered to protect the subject’s identity). An LLM agent extracts structured identity signals from a conversation, autonomously searches the web to identify a candidate individual, and verifies the candidate matches all extracted claims“ (Lermen et al. (2026): Large-scale online deanonymization with LLMs | PDF).
Die technischen Möglichkeiten haben nun zwei Effekte: (1) Anonyme Nutzer im Netz, die sich strafbar machen, können identifiziert werden. (2) Für Nutzer, die ihre Anonymität aus den verschiedenen Gründen wahren möchten, reicht ein Pseudonym im Netz in Zukunft wohl nicht mehr aus.
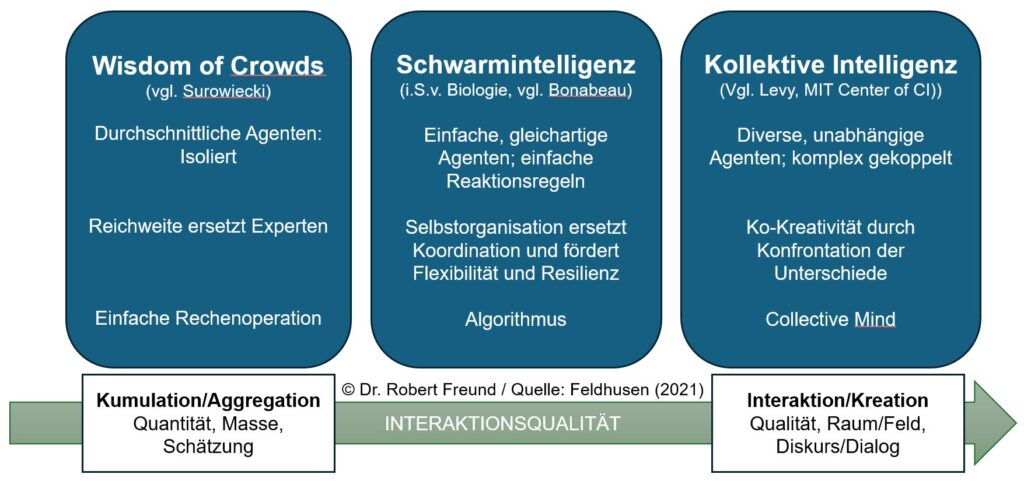
In dem Blogbeitrag Wisdom of Crowds – Schwarm Intelligenz – Kollektive Intelligenz bin ich schon einmal intensiver auf die Unterscheidung der jeweiligen Ansätze eingegangen. Darin zitiere ich Feldhusen (2021), der sich wiederum auf Lévy vom MIT Center of Collective Intelligence bezieht. Es lohnt sich, dessen Auffassung noch etwas genauer zu betrachten:
„Die Netzwerkgesellschaft wird nicht von einer Expertenintelligenz getragen, die für andere denkt, sondern von einer kollektiven Intelligenz, die die Mittel erhalten hat, sich auszudrücken. Der Anthropologe des Cyberspace, Pierre Lévy, hat sie untersucht: »Was ist kollektive Intelligenz? Es ist eine Intelligenz, die überall verteilt ist, sich ununterbrochen ihren Wert schafft, in Echtzeit koordiniert wird und Kompetenzen effektiv mobilisieren kann. Dazu kommt ein wesentlicher Aspekt: Grundlage und Ziel der kollektiven Intelligenz ist gegenseitige Anerkennung und Bereicherung …« (Lévy, 1997, S. 29). Um allen Missverständnissen zuvor zu kommen, richtet er sich ausdrücklich gegen einen Kollektivismus nach dem Bild des Ameisenstaates. Vielmehr geht es ihm um eine Mikrovernetzung des Subjektiven. »Es geht um den aktiven Ausdruck von Singularitäten, um die systematische Förderung von Kreativität und Kompetenz, um die Verwandlung von Unterschiedlichkeit in Gemeinschaftsfähigkeit« (ebd., S. 66)“ (zitiert in Grassmuck 2004).
L ÉVY, PIERRE (1997): Die Kollektive Intelligenz. Eine Anthropologie des Cyberspace, Bollmann Verlag, Mannheim.
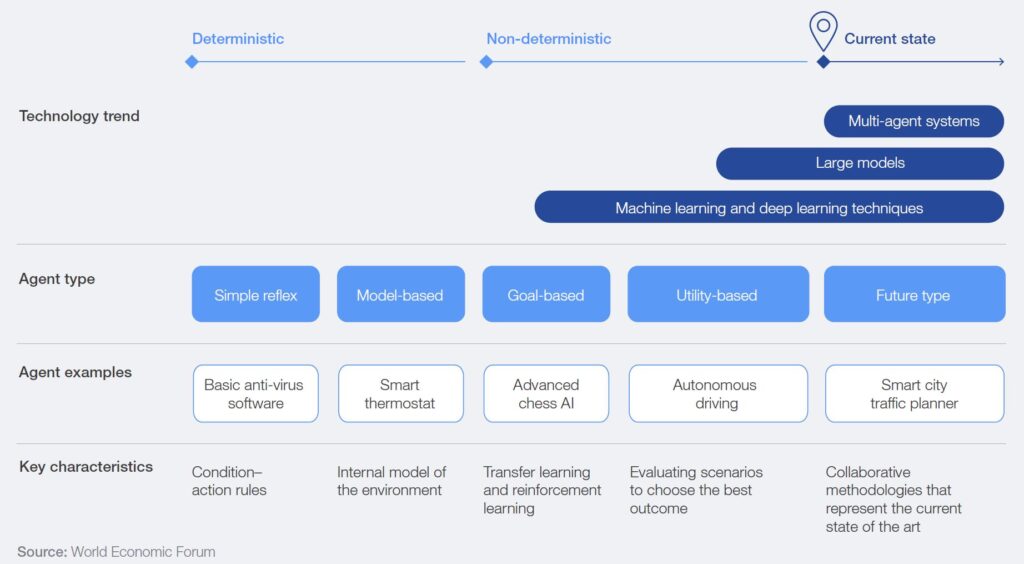
In der Grafik ist zu erkennen, dass es bei Kollektiver Intelligenz auch um diverse, unabhängige Agenten geht, die komplex gekoppelt sind. Aus der heutigen Perspektive können damit auch KI-Agenten im Netzwerk diverser Akteure gemeint sein. Auch in so einem Netzwerk würde es also nicht DIE Expertenintelligenz geben. Intelligenz (menschliche, künstliche, hybride Formen) würde sich also im Netzwerk verteilt, immer wieder neu bilden.
Um das zu erreichen, müssen allerdings Voraussetzungen erfüllt sein, die von den Tech-Konzernen mit ihren KI-Agenten manchmal „vergessen“ werden. Grundlage und Ziel der Kollektiven Intelligenz sind nach Lévy „gegenseitige Anerkennung und Bereicherung“. Bei diesen Punkten habe ich bei den proprietären KI-Modellen so meine Zweifel.
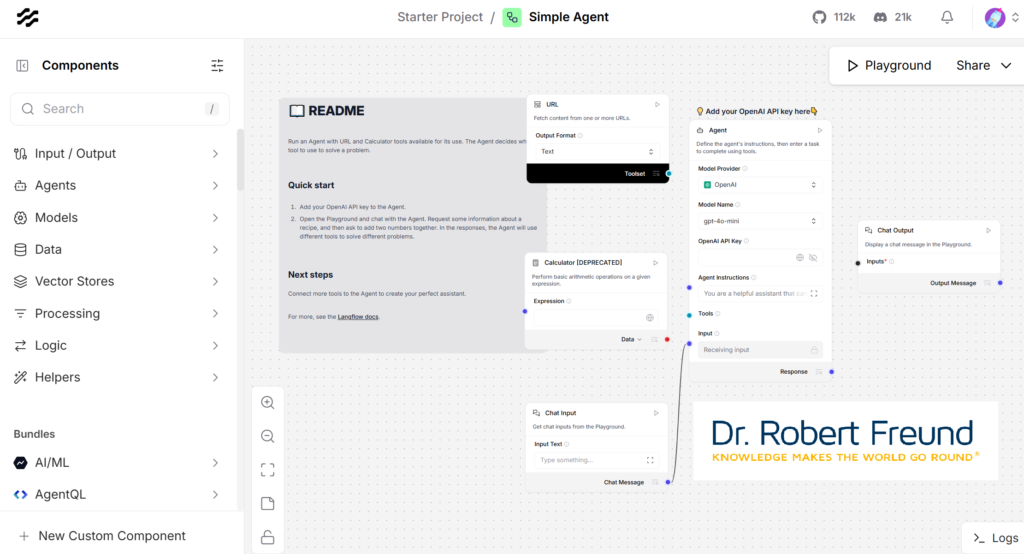
Eigener Screenshot von einem einfachen Agenten, erstellt in Langflow – alle Daten bleiben dabei auf unseren Servern, ganz im Sinne einer Digitale Souveränität
Wenn es um KI-Agenten geht, wird oft darüber diskutiert, wie das entsprechende Design aussehen sollte, damit der oder die KI-Agenten die wirtschaftlichen Ziele erreichen können. In dem Zusammenhang gibt es immer wieder Hinweise darauf, dass solche gut gemeinten KI-Agenten oftmals unbeabsichtigte Folgen nach sich ziehen können. Die folgende Quelle aus 2025 stellt das unmissverständlich dar:
„When it comes to AI agents, even well-intentioned design can lead to unintended consequences. The challenge isn’t just about making agents work correctly – it’s is about making them work safely and ethically within a complex ecosystem of human and artificial actors“ (Bornet, P. et al. 2025).
Wie vom Autor hervorgehoben, ist es eine der wichtigsten Herausforderungen, dass KI-Agenten sicher und ethisch in einem komplexen Ökosystem von Menschen und „künstlichen Akteuren“ arbeiten.
In der Softwareentwicklung war es schon früh klar, dass Projekte mit unklaren Anforderungen anders abgewickelt werden müssen, als gut planbare Projekte. Aus diesen Überlegungen heraus hat sich das Agile Manifest ergeben, und haben sich verschiedene Vorgehensmodelle entwickelt, wie z.B. KANBAN in der IT, Scrum oder auch Design Thinking.
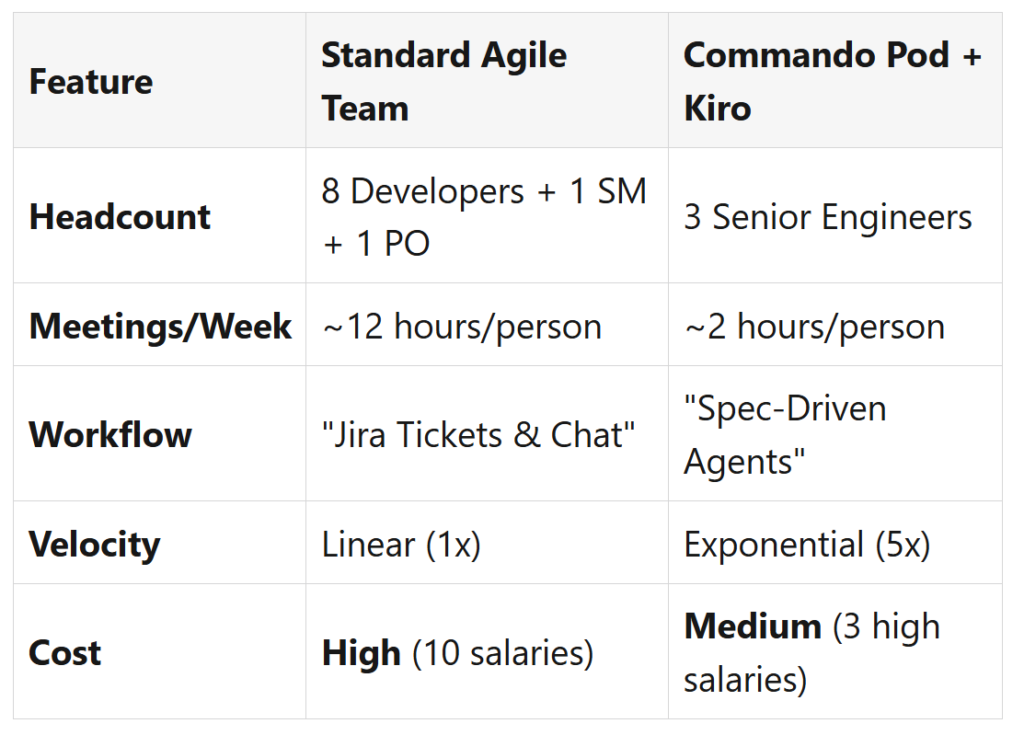
Es wundert weiterhin nicht, dass Künstliche Intelligenz rasch in der Softwareentwicklung – z.B. auch im Scrum Framework – angewendet wurde, und auch noch wird. An dieser Stelle wird klar, dass bestehende Prozesse mit KI effizienter durchgeführt werden sollen. In dem Beitrag von Montagne (2025) wird in Bezug auf eine McKinsey-Studie erwähnt, dass durch diese Vorgehensweise durchaus Produktivitätsvorteile in Höhe von 10-15% erzielt werden können.
„Old Model (Standard Agile + AI): ~10-15% productivity gain“ (ebd.).
Demgegenüber weist Montagne allerdings auch darauf hin, dass durch eine andere Vorgehensweise – also ohne das Scrum Framework – plus KI ganz andere Produktivitätsvorteile erzielt werden können.
Die Abbildung weiter oben zeigt in der Gegenüberstellung die immensen Vorteile einer Vorgehensweise, die sich von Scrum unterscheidet und Agentic AI mit Kiro nutzt.
Es stellt sich natürlich gleich die Frage, ob dieses Learning aus der Softwareentwicklung auch auf andere Bereiche übertragbar ist. Antwort: Ja, das ist es.
Eigener Screenshot vom Langflow-Arbeitsbereich, inkl. der Navigation auf der linken Seite
Langflow haben wir als Open Source Anwendung auf unseren Servern installiert. Mit Langflow ist es möglich, Flows und Agenten zu erstellen – und zwar einfach mit Drag&Drop. Na ja, auch wenn es eine gute Dokumentation und viele Videos zu Langflow gibt, steckt der „Teufel wie immer im Detail“.
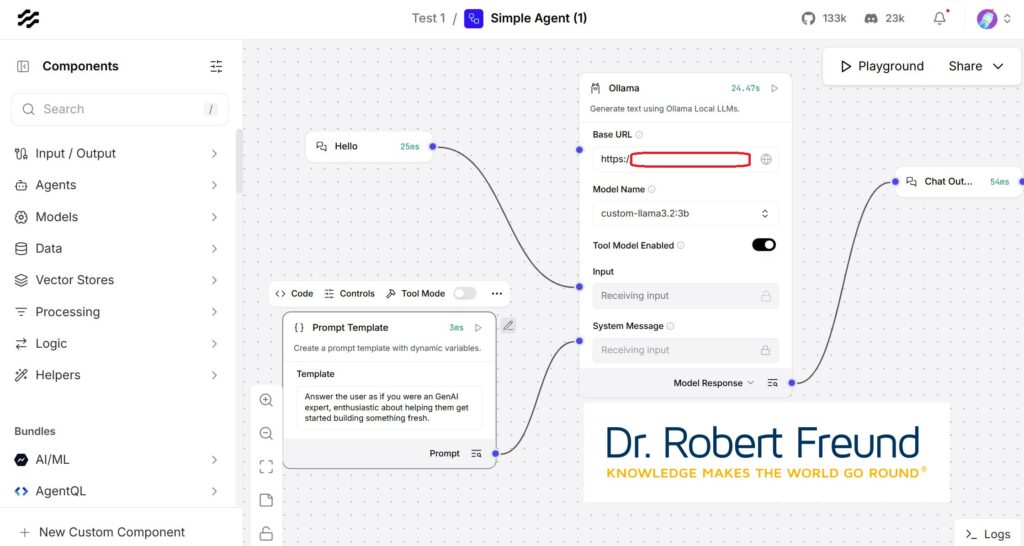
Wenn man mit Langflow startet ist es erst einmal gut, die Beispiele aus den Dokumentationen nachzuvollziehen. Ich habe also zunächst damit begonnen, einen Flow zu erstellen. Der Flow unterscheidet sich von Agenten, auf die ich in den nächsten Wochen ausführlicher eingehen werde.
Wie in der Abbildung zu sehen ist, gibt es einen Inputbereich, das Large Language Model (LLM) oder auch ein kleineres Modell, ein Small Language Model (SLM). Standardmäßig sind die Beispiele von Langflow darauf ausgerichtet, dass man OpenAI mit einem entsprechenden API-Key verwendet. Den haben wir zu Vergleichszwecken zwar, doch ist es unser Ziel, alles mit Open Source abzubilden – und OpenAI mit ChatGPT (und andere) sind eben kein Open Source AI.
Um das zu erreichen, haben wir Ollama auf unseren Servern installiert. In der Abbildung oben ist das entsprechende Feld im Arbeitsbereich zu sehe,n. Meine lokale Adresse für die in Ollama hinterlegten Modelle ist rot umrandet unkenntlich gemacht. Unter „Model Name“ können wir verschiedene Modelle auswählen. In dem Beispiel ist es custom-llama.3.2:3B. Sobald Input, Modell und Output verbunden sind, kann im Playground (Botton oben rechts) geprüft werden, ob alles funktioniert. Das Ergebnis sieht so aus:
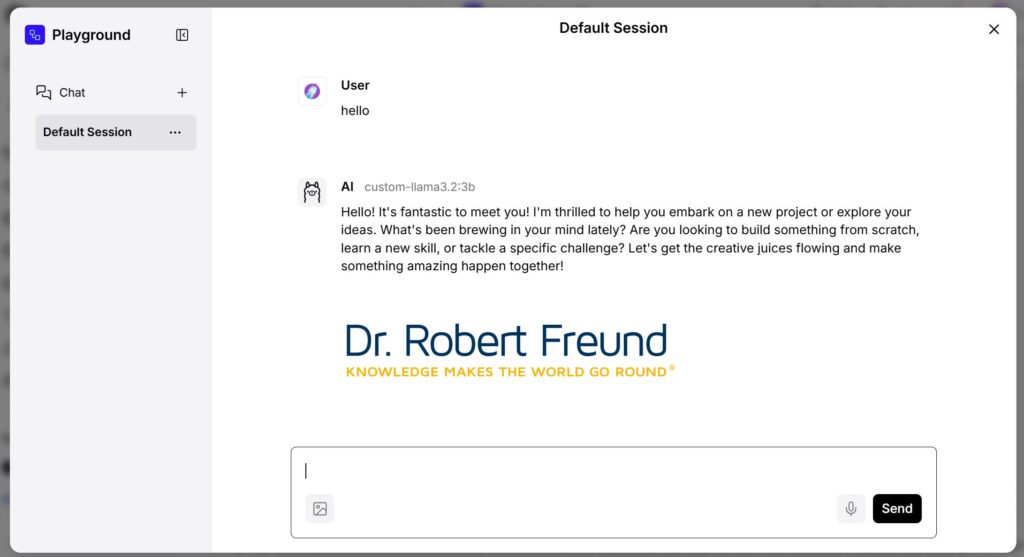
Screenshot vom Playground: Ergebnis eines einfachen Flows in Langflow
Es kam mir jetzt nicht darauf an, komplizierte oder komplexe Fragen zu klären, sondern überhaupt zu testen, ob der einfache Flow funktioniert. Siehe da: Es hat geklappt!
Alle Anwendungen (Ollama und Langflow) sind Open Source und auf unseren Servern installiert. Alle Daten bleiben auf unseren Servern. Wieder ein Schritt auf dem Weg zur Digitalen Souveränität.
Dennoch ist deutlich zu erkennen, dass es immer mehr Anbieter in allen möglichen Segmenten von Künstlicher Intelligenz – auch bei den Language Models – gibt. Wenn man sich alleine die Vielzahl der Modelle bei Hugging Face ansieht: Heute, am17.09.2025, stehen dort 2,092,823 Modelle zur Auswahl, und es werden jede Minute mehr. Das erinnert mich an die Diskussionen auf den verschiedenen (Welt-) Konferenzen zu Mass Customization and Personalization. Warum?
Large Language Models (LLM):One Size Fits All Wenn es um die bei der Anwendung von Künstlicher Intelligenz (GenAI) verwendeten Trainingsmodellen geht, stellt sich oft die Frage, ob ein großes Modell (LLM: Large Language Model) für alles geeignet ist – ganz im Sinne von “One size fits all”. Diese Einschätzung wird natürlich von den Tech-Unternehmen vertreten, die aktuell mit ihren Closed Source Models das große Geschäft machen, und auch für die Zukunft wittern. Die Argumentation ist, dass es nur eine Frage der Zeit ist, bis das jeweilige Large Language Model die noch fehlenden Features bereitstellt – bis hin zur großen Vision AGI: Artificial General Intelligence. Storytelling eben…
Small Language Models (SLM): Variantenvielfalt In der Zwischenzeit wird immer klarer, dass kleine Modelle (SLM) viel ressourcenschonender, in speziellen Bereichen genauer, und auch wirtschaftlicher sein können. Siehe dazu Künstliche Intelligenz: Vorteile von Small Language Models (SLMs) und Muddu Sudhakar (2024): Small Language Models (SLMs): The Next Frontier for the Enterprise, Forbes, LINK.
Komplexitätsfalle Es wird deutlich, dass es nicht darum geht, noch mehr Möglichkeiten zu schaffen, sondern ein KI-System für eine Organisation passgenau zu etablieren und weiterzuentwickeln. Dabei sind erste Schritte schon zu erkennen: Beispielsweise werden AI-Router vorgeschlagen, die verschiedene Modelle kombinieren – ganz im Sinne eines sehr einfachen Konfigurators. Siehe dazu Künstliche Intelligenz: Mit einem AI Router verschiedene Modelle kombinieren.
Mit Hilfe eines KI-Konfigurators könnte man sich der Komplexitätsfalle entziehen. Ein Konfigurator in einem definierten Lösungsraum (Fixed Solution Space) ist eben das zentrale Element von Mass Customization and Personalization.
Die Lösung könnte also sein, massenhaft individualisierte KI-Modelle und KI-Agents dezentralisiert für die Allgemeinheit zu schaffen. Am besten natürlich alles auf Open Source Basis – Open Source AI – und für alle in Repositories frei verfügbar. Auch dazu gibt es schon erste Ansätze, die sehr interessant sind. Siehe dazu beispielsweise (Mass) Personalized AI Agents für dezentralisierte KI-Modelle.
Genau diese Überlegungen erinnern – wie oben schon angedeutet – an die Hybride Wettbewerbsstrategie Mass Customization and Personalization. Die Entgrenzung des definierten Lösungsraum (Fixed Solution Space) hat dann weiter zu Open Innovation (Chesbrough und Eric von Hippel) geführt.
Die Überschrift ist reißerisch und soll natürlich Aufmerksamkeit generieren. Dabei stellt man sich natürlich gleich die Frage: Wie kommt das? Geschickt ist, dass Gartner selbst die Antwort gibt:
„Over 40% of agentic AI projects will be canceled by the end of 2027, due to escalating costs, unclear business value or inadequate risk controls, according to Gartner, Inc.“ (Gartner vom 25.06.2025).
Es ist nun wirklich nicht ungewöhnlich, dass in der ersten Euphorie zu Agentic AI alles nun wieder auf ein sinnvolles und wirtschaftliches Maß zurückgeführt wird. Dennoch haben Unternehmen, die entsprechende Projekte durchgeführt haben, wertvolles (Erfahrungs-)Wissen generiert.
Schauen wir uns in diesem Zusammenhang den bekannten Gartner Hype Cycle 2025 an, so können wir sehen, dass AI Agents ihren „Peak of Inflated Expectations“ erreicht haben, und es nun in das Tal „Through of Desillusionment“ geht. Dabei wird in dem oben genannten Artikel natürlich auch darauf hingewiesen, dass Gartner gerne beratend behilflich ist, Agentic AI wirtschaftlicher und besser zu gestalten. Honi soit qui mal y pense.
Dennoch können gerade Kleine und Mittlere Unternehmen (KMU) von dieser Entwicklung profitieren, indem sie bewusst und sinnvoll KI Agenten nutzen. Am besten natürlich in Zusammenhang mit Open Source AI. Komisch ist, dass Open Source AI in dem Gartner Hype Cycle gar nicht als eigenständiger Begriff vorkommt. Honi soit qui mal y pense.
Der Begriff User Experience (UX) spielt bei der Entwicklung von Produkten und Dienstleistungen eine große Rolle. Etwas kurz ausgedrückt, geht es bei UX um das „Benutzererlebnis“ oder auch „Nutzererlebnis“. Dabei wird davon ausgegangen, dass es sich bei dem User um Menschen (Human) handelt.
In Zukunft wird es neben der Interaktion zwischen Technologien und Menschen auch immer mehr Interaktionen zwischen Technologien selbst stattfinden. Am Beispiel von KI-Agenten lässt sich das ganz gut nachvollziehen, denn hier muss das Design auf einen oder mehrere Agenten abgestimmt sein (Agentic Experience: AX). Der folgende Text unterstreicht das noch einmal:
„The designs of tomorrow will have to consider two kinds of users: humans and agents. The agent experience (AX) will be using APIs to compose workflows but now includes desktop interactions“ (Thomas et al. 2025).
Ich bin gespannt, wie die UX-Community auf diese Entwicklung reagiert.
WEF (2024): Navigating the AI Frontier. A Primer on the Evolution and Impact of AI Agents
Alle reden und schreiben über KI (Künstliche Intelligenz / AI: Artificial Intelligence) und meinen damit meistens GenAI. Bei den verschiedenen KI-Anwendungen geht es mehrheitlich darum, Abläufe mit ihren verschiedenenTasks zu unterstützen. Siehe dazu beispielsweise Künstliche Intelligenz beeinflusst den gesamten Lebenszyklus der Software-Entwicklung. Ähnliches findet man auch bei anderen Branchen wie z.B. der Kommunikationsbranche usw.
Diese vielfältigen Möglichkeiten faszinieren Menschen und Organisationen so sehr, dass sie das auch bei den entsprechenden Kompetenzentwicklungen als einen der Schwerpunkte sehen. Hervorheben möchte ich hier beispielsweise das oft erwähnte Prompt-Engineering.
Betrachten wir allerdings neuere KI-Entwicklungen, so wird immer deutlicher, dass es in der nahen Zukunft immer mehr darum gehen wird, mit KI-Agenten (Agentic AI) umzugehen. Dabei verändern sich allerdings die Perspektiven auf die Nutzung von KI grundlegend. Der folgende Absatz zeigt das deutlich auf:
„Quite simply, today, most people use AI in a task-oriented workflow (for example, to finish a code stub or summarize a document), whereas agents are goal oriented. You give an AI agent a task, and it will get it done and even plan future actions without needing your explicit guidance or intervention. Working with agents requires a change in perspective: instead of designing an AI driven app to run some specific tasks, you use an agentic approach that focuses on outcomes and objectives. An agent will try to achieve a desired outcome and will figure out on its own which tasks are necessary“ (Thomas, R.; Zikopoulos, P.; Soule, K. 2025).
Die in dem Zusammenhang mit KI thematisierten Kompetenzen waren und sind immer noch zu sehr auf den „task-oriented workflow“ ausgerichtet. Dabei benötigen wird bei der eher „goal oriented“, also ergebnisorientierten (zielorientierten) Herangehensweise, andere Kompetenzen.
Ich bin gespannt, wie die vielen KI-Kompetenzmodelle diese Entwicklungen abfangen werden. Denn: Kaum ist das eher task-oriented Kompetenzmodell veröffentlicht, muss schon nachgebessert werden. In der Logik dieser Kompetenzmodelle wird es wohl bald eine Weiterentwicklung geben, die in Zukunft „AI Agentic“ – Kompetenzen in den Mittelpunkt stellt, usw. usw. Ob das für Menschen und Organisationen einen guten (stabilen) Rahmen für ein modernes Kompetenzmanagement bietet?
Wie Sie als Leser meines Blogs wissen, stehe ich diesen KI-Kompetenzmodellen etwas kritisch gegenüber, da sie zu „Bindestrich“-Kompetenzen (Digitale Kompetenzen, Agile Kompetenzen, KI-Kompetenzen) führen, die sich in großen Teilen verändern müssen. Meines Erachtens ist es besser, allgemein von Kompetenzen von Selbstorganisationsdispositionen zu sprechen – und zwar auf den Ebenen Individuum, Gruppe, Organisation und Netzwerk – natürlich auch unter dem Aspekt der Nutzung von KI. Siehe dazu Kompetenzmanagement.
Diese Website benutzt Cookies. Wenn du die Website weiter nutzt, gehen wir von deinem Einverständnis aus.