Mistral AI ist ein französisches Unternehmen, das eine Modellfamilie veröffentlicht, die europäischen Anforderungen an KI-Modelle entspricht, und Open Source verfügbar ist. (Open Models) Die Leistungsfähigkeit von den Mistral- Modellen nähert sich den Cloud AI Modellen (Closed Models) wie ChatGPT, Gemini etc. an (Open Source AI holt auf). Mit Le Chat gibt es auch eine europäische Alternative zu ChatGPT.
Mistral-Modelle können bei Mistral selbst, also auf in deren Cloud, getestet werden. Darüber hinaus ist es auch möglich, die Modelle über Hugging Face herunterzuladen und auf dem eigenen Server zu nutzen, z.B. mit LocalAI.
Der Trend zu immer kleineren, speziellen und leistungsstarken Modellen (SLM: Small Language Models) macht es immer attraktiver, solche Modelle auf dem eigenen Laptop, also auf „Heim-Hardware„, zu nutzen. Das ist u.a. auch mit Mistral möglich. Wie genau, wird in dem folgenden Artikel gut beschrieben:
Künstliche Intelligenz (GenAI) kann in der Zwischenzeit viele traditionelle Tätigkeiten oder Abläufe optimieren und ersetzen. Bei der Interaktion mit KI-Modellen passt sich diese immer stärker an die Anforderungen des Nutzers an.
Künstliche Intelligenz verstärkt durch diese Personalisierung allerdings – oft unbemerkt vom Nutzer – Schmeicheleien (Blogbeitrag). Es wundert daher nicht, dass KI immer mehr als Compagnon wahrgenommen wird, der möglicherweise als angenehmer empfunden wird, als andere Menschen. Es kommt bei dieser Entwicklung zu einer Art Transformation von den eher funktionsorientierten Nutzung der KI, hin zum Aufbau von einer Art „Beziehung“.
„AI companions differ from traditional task-oriented AI by prioritizing relationship building over functionality (Zhang and Lu, 2023; Zhang et al., 2025). Modern systems incorporate memory of past interactions, can recognize emotion, and adapt their responses to individual users’ needs (Yang et al., 2025). Platforms like Replika, Character.ai, and XiaoICE have attracted user bases in the millions. Many users have reported forming emotional attachments to their AI companions, viewing them as friends, mentors, or romantic partners (Zhang et al., 2024; Kouros et al., 2024)“ (The AI Index 2026 Annual Report).
Einerseits ist also die Anpassung an die persönlichen Bedürfnisse eine positive Entwicklung, andererseits kann es über den Weg der (unbemerkten) Schmeicheleien einen Lock-in geben, aus dem die jeweiligen Nutzer selbst nicht mehr herauskommen. Diese sich dann entwickelnde Pfadabhängigkeit ist aus der Innovationsforschung bekannt.
Beyer (2005) weist allerdings in seinem Beitrag darauf hin, dass es auch dazu kommen kann, dass „Akteure jeweils einen Schlüssel finden können, um das Schloss wieder aufzuschließen“.
Beyer, J. (2005): Pfadabhängigkeit ist nicht gleich Pfadabhängigkeit!Wider den impliziten Konservatismus eines gängigen Konzepts, in Zeitschrift für Soziologie, Jg. 34, Heft 1, Februar 2005, S. 5–21 | PDF
Bei der Nutzung von Künstlicher Intelligenz kommt es immer stärker darauf an, KI-Agenten sinnvoll und effizient einzusetzen. Dabei geht es oft auch darum zu wissen, welche Token-Kosten bei der Nutzung von KI-Agenten anfallen.
Bei der Abrechnung auf Basis von Tokens geht es um die Menge verarbeiteter Textbausteine (Tokens), die sich Modelle wie GPT-4 oder Gemini gut bezahlen lassen. Dabei kommt es allerdings oftmals zu starken Schwankungen, und zu regelrechten Abrechnungsschocks.
In einer Studie haben Forscher nun untersucht, inwiefern KI-Agenten bei Codierungs-Aufgaben (coding tasks) in der Lage sind, vor Start des Tasks die Kosten für die benötigten Tokens vorherzusagen. Immerhin wäre eine gut abschätzbare, und somit im voraus gut planbare, Anzahl von Tokens für die wirtschaftliche Bewertung von coding tasks von großer Bedeutung. Eine aktuelle Studie belegt allerdings sehr ausführlich, dass KI-Agenten dazu nicht in der Lage sind:
“Agents are not capable of predicting their own token costs. This is the fundamental bottleneck for result-based pricing for agents. You can’t really price the agent well unless you can figure out the cost, but now you only see the token costs after everything is done” (Bai, L. et al. (2026) https://arxiv.org/abs/2604.22750).
Man wird also erst nachdem alles erledigt ist wissen, was alles gekostet hat (in Token-Kosten). In dem genannten Paper sind noch viele weitere Detail zu finden.
Gerade Kleine und Mittlere Unternehmen (KMU), die stark auf ihre Kosten achten müssen, können die Ergebnisse der Studie eine gute Basis für die wirtschaftliche Nutzung von KI-Agenten sein.
Wenn es um Künstliche Intelligenz geht, lesen wir in letzter Zeit immer häufiger, dass für die großen KI-Modelle „unbedingt“ größere Rechenzentren benötigt werden. Dafür wurden auch schon hohe Milliarden-Beträge auf dem Kapitalmarkt eingesammelt. Es scheint hier kein Limit zu geben.
Andererseits stehen allerdings auch Fragen zu den dafür benötigten Ressourcen im Raum. In einer modernen Welt geht es nicht mehr alleine um die Bedürfnisse von Tech-Konzernen, sondern auch darum, eine lebenswerte Umwelt zu erhalten. In dem Zusammenhang geht es somit auch um den CO2-Verbauch und um den Bedarf an Wasser. Dazu findet man im Aktuellen AI Report folgendes:
„AI’s environmental footprint is expanding alongside its capabilities. Grok 4’s estimated training emissions reached 72,816 tons of CO2 equivalent. AI data center power capacity rose to 29.6 GW, comparable to New York state at peak demand, and annual GPT-4o inference water use alone may exceed the drinking water needs of 12 million people“ (AI Report 2026).
Es ist schon erstaunlich, welche Ressourcen die hier genannten KI-Modelle verschlingen. Dabei streben die großen KI-Systeme eine übergreifende Art von Intelligenz an: Artificial General Intelligence (AGI), die der menschlichen Intelligenz weit überlegen sein soll. Betrachten wir daher einmal, wie viel Energie ein Mensch für eine komplexe Problemlösung benötigt:
„Unser Gehirn benötigt für hochkomplexe Informationsübertragungen und -verarbeitungen weniger Energie als eine 30-Watt-Glühbirne“ (Prof. Dr. Amunts).
Es wird deutlich, dass der Energieverbrauch der großen Tech-KI-Modelle weniger intelligent ist, als man es uns weismachen möchte. Es wundert daher nicht, dass die Entwicklung immer größerer Modelle (Large Language Models) infrage gestellt wird.
Forscher sind aktuell auf der Suche nach Modellen, die ganz anders aufgebaut sind und nur einen Bruchteil der aktuell benötigten Energie verbrauchen. Gerade in China gibt es dazu schon deutliche Entwicklungen. Auch in Deutschland befassen sich Forscher mit dem Thema neuroinspirierte Technologien.
Auf der Produktionsseite sind daher schon fast alle Prozesse digitalisiert, sodass die meisten Produkte schon heute ohne großen Aufwand individualisiert werden können. Auf der Kundenseite haben die vielen Konfiguratoren manchmal mehr Verwirrung gestiftet, als dass es für die Kunden nützlich war.
Interessant ist, dass Mass Customization and Personalization durch Künstliche Intelligenz wieder eine Art Revival erlebt.
Einer der führenden Innovationsforscher, Prof. Dr. Frank Piller von der RWTH Aachen, hat nun in einem Podcast mit der Sendung WDR Quarks – Wissenschaft und mehr, Mass Customization, und die neuen Möglichkeiten durch Künstliche Intelligenz, erläutert. Das Gespräch ist in dem Podcast bis Minute 34:26 zu hören.
Maßanfertigung für Massen WDR 5 Quarks – Wissenschaft und mehr 07.04.2026 01:20:01 Std.
Es freut mich, dass Mass Customization nicht nur in der Forschung, sondern auch im allgemeinen Bewusstsein der Kunden wieder thematisiert wird.
Aktuelle Entwicklungen werden auf der von mir initiierten Konferenz Mass Customization and PersonalizationMCP 2026, vom 16.-19.09.2026 in Balatonfüred, Ungarn, vorgestellt.
AI (Artificial intelligence) AI management and support technology in the Business plan marketing success customer. AI management concept.
Es ist nur natürlich, dass jeder Einzelne, Organisationen und Öffentliche Verwaltungen ausprobieren, was mit Künstlicher Intelligenz (GenAI) möglich ist. Im wissenschaftlichen Umfeld wundere ich mich allerdings immer wieder darüber, wie unkritisch GenAI eingesetzt wird, wodurch die Kriterien wissenschaftlicher Arbeit konterkariert werden. Warum ist das so? Eine ausführlich Begründung habe ich im aktuellen OECD Report gefunden. Dabei geht es hier speziell um die Reproduzierbarkeit als Säule wissenschaftlichen Arbeitens geht.
Reproducibility is a pillar of scientific operations. To be accepted by the scientific community, results must (usually) be verifiable, and reproducible by others. One condition for reproducibility is full disclosure of the methods and data that led to the conclusion, meaning transparency and accessibility. From this perspective, GenAI models do not meet scientific criteria. First, the most popular models of GenAI are “black boxes”, as neither their weights (the parameters that define a neural network) nor their training data are publicised. Thus, disentangling the contribution of the data and the contribution of various components of the model is difficult in any scientific result coming from such a model. This comes from the very nature of neural networks: knowledge is distributed, hence difficult to localise. As GenAI models have a random component at their core, some results might not be robust. In addition, access to the training data can be limited due to the proprietary nature of many GenAI models: one example is the “AI Structural Biology Consortium”, a follow-up to AlphaFold-3, an ongoing project which makes use of data owned by pharmaceutical companies, which is secret and will remain secret (Callaway, 2025). Currently, solutions for access include open weights (e.g. Llama) and open source (including access to training data). The importance of openness was demonstrated by AlphaFold2, as the disclosure of its code and data triggered a series of initiatives refining the tool (Saplakoglu, 2024). Openness is essential to the cumulative progress at the core of science“ (OECD Digital Education Report 2026).
Am Beispiel von Pharmaunternehmen wird deutlich, dass es gerade in sensiblen Branchen wichtig ist, offene KI-Modelle zu nutzen. Offenheit ist: „Offenheit ist für den kumulativen Fortschritt im Kern der Wissenschaft unerlässlich“ (ebd.). Siehe dazu auch
KI-Agenten sind aktuell gefühlt überall. Natürlich bieten die proprietären Modelle wie ChatGPT, Gemini, Grok etc. viele Möglichkeiten an, solche KI-Agenten zu erstellen und zu nutzen. Wie Sie als Leser unseres Blogs wissen, tentieren wir allerdings dazu, Open Source AI zu nutzen, gerade wenn es um eigene, spezielle Expertise, oder unternehmensspezifisches Wissen in Innovationsprozessen geht.
Neben den von uns schon beschriebenen Möglichkeiten von Langflow und Ollama, möchten wir Ihnen eine weitere Alternative vorstellen, eigene KI-Agenten zu nutzen, und dabei unterschiedliche LLMs einzubinden.
„Smolagents is a minimalist AI agent framework developed by the Hugging Face team, crafted to enable developers to deploy robust agents with just a few lines of code. Embracing simplicity and efficiency, smolagents empowers large language models (LLMs) to interact seamlessly with the real world“ (Source: https://smolagents.org/de/).
Das Team von Hugging Face bietet hier eine minimalistische Möglichkeit, auf Open Source Basis KI-Agenten zu entwickeln, und der Community in einem Repository zur Verfügung zu stellen (Best Smolagents in Hugging Face).
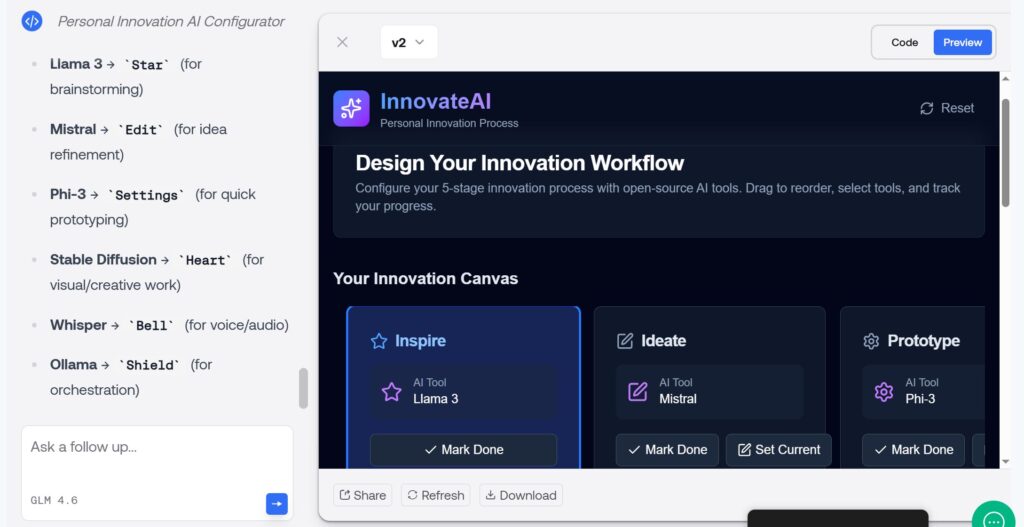
Es ist interessant zu sehen, wie einfach man seine Idee in einem ersten KI-Agenten umsetzen kann. In dem folgenden Beispiel habe ich versucht, einen persönlichen Innovationsprozess abzubilden. In jedem Prozessschritt wollte ich ein anderes Open Source KI-Modell einsetzen.
Eigener Screenshot
In der Abbildung sind erste Prozessschritte für die Entwicklung von Innovationen zu sehen: Inspire mit Llama 3, Ideate mit Mistral, Prototype mit Phi 3 etc. Die jeweiligen LLM kann ich auswählen und testen. Das ging sehr schnell und war super einfach.
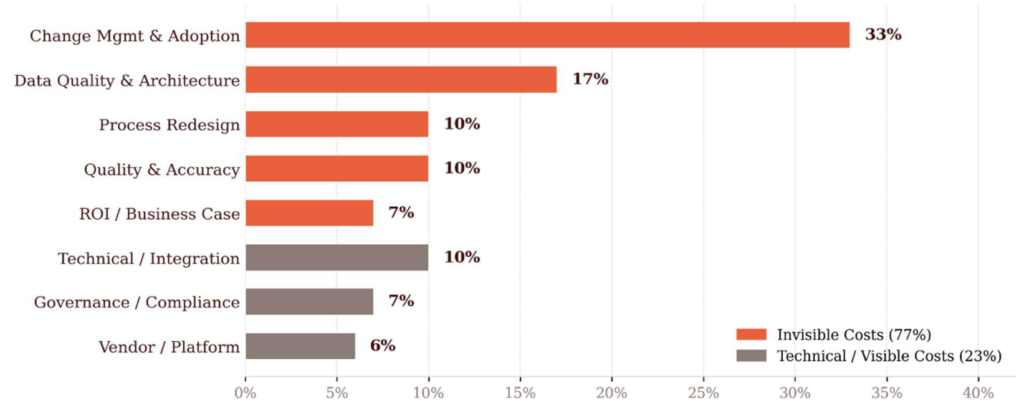
Hardest challenges in AI implementation (Pereira et al. 2026)
Wenn es um Implementation von Künstlicher Intelligenz im Unternehmen geht, werden oft nicht alle Kosten beachtet. In einer Analyse von 51 erfolgreichen Implementationen aus verschiedenen Branchen, haben Pereira, Graylin und Brynjolfsson im April 2026 herausgefunden, das 77% der Kosten, unsichtbar sind (Abbildung).
„77% of the hardest challenges practitioners faced were invisible costs: change management, data quality, and process redesign, not technical issues. Technology was consistently described as the easiest part. The true cost of a successful deployment usually includes at least one failed attempt, and the bulk of investment goes to everything except the model“ (Pereira et al. 2026).
Es zeigt sich auch hier wieder, dass der Einsatz von Künstlicher Intelligenz über den Hype hinaus auch wirtschaftlich genauer betrachtet werden muss. Das ist bei Kleinen und Mittleren Unternehmen (KMU) besonders wichtig, da KMU oft nur stark begrenzte Ressourcen zur Verfügung stehen.
Wenn man sich die vielen Meldungen in den Medien ansieht, kann man zu dem Schluss kommen, dass es (fast) allen um Aufmerksamkeit, und damit auch um Beeinflussung geht. Dahinter können wirtschaftliche, politische oder soziale Interessen stecken. Viele gehen dabei sehr subtil vor, indem sie Daten nicht genau wiedergeben, oder bewusst aus dem Zusammenhang nehmen.
Oft fehlt bei den Angaben auch die genaue Quelle. Es wird von einer diffusen Studie gesprochen oder geschrieben, doch wird die Quelle nicht genannt. Weiterhin steht bei Zeitungsartikel oft der Hinweis, dass der Beitrag auf Basis von Inhalten anderer Medien geschrieben wurde – diese werden allerdings im Text – wenn überhaupt – nicht deutlich kenntlich gemacht.
Die wenigen Beispiele zeigen schon auf, dass eine mehr wissenschaftlich basierte Arbeit wünschenswert wäre. Die Prinzipien einer solchen Arbeit würden helfen, zwischen eigener Meinung und Quelle zu unterscheiden, um sich ein eigenes Bild machen zu können. Damit kommen wir zur Akademischen Integrität, die es ermöglichen soll, dass wissenschaftlich korrekt und damit transparent gearbeitet und veröffentlicht wird. Gerade in Zeiten von Künstlicher Intelligenz muss das ganz besonders beachtet werden.
Was ist unter Akademischer Integrität zu verstehen?
Dazu habe ich eine Definition der International Centre for Academic Integrity [ICAI] gefunden, die eher im amerikanischen Umfeld genutzt wird. In Europa beziehen sich akademische Institutionen eher auf die Definition der ENAI:
The definition from the European Network for Academic Integrity [ENAI] (2022) is less philosophical than ICAI’s. ENAI states that academic integrity is: Compliance with ethical and professional principles, standards, practices and consistent system of values, that serves as guidance for making decisions and taking actions in education, research and scholarship.“ (Gallant, T. B. ; Davis, M. Khan, Z. R. (2026): ACADEMIC INTEGRITY IN THE AGE OF AI. DOI 10.1017/9781009672078).
Wenn wir unterstellen, dass akademische Integrität bedeutet, selbst verantwortlich, transparent und ethisch zu arbeiten wird klar, dass sich diese Vorgehensweise dann auch auf die Gesellschaft auswirkt.
Es wird Zeit, dass alle Akteure in einer von Künstlicher Intelligenz getriebenen Welt, akademische Prinzipien berücksichtigen. In Europa haben wir erste Ansätze dazu, die oftmals platt mit Regulierung gleichgesetzt werden. In den USA oder China erodieren diese Grundlagen eher. Es ist daher gut, dass wir in Europa einen eigenen Weg gehen, bei dem die Gesellschaft im Mittelpunkt steht.
Sogar in unseren Blogbeiträgen haben wir von Anfang an darauf geachtet, zwischen Originaltexten mit Quellenangaben, und unserer eigenen Meinung zu unterscheiden. Dass ich die Prinzipien bei meiner Dissertation und bei meinen verschiedenen wissenschaftlichen Paper einhalte, versteht sich von selbst. Aktuell beispielsweise für die beiden Paper, die ich für die MCP 2026, 16.-19.09.2026, in Balatonfüred, Ungarn vorbereite.
In mehreren Blogbeiträge habe ich verschiedene Aspekte aus einem Kurzlehrbuch thematisiert, das als Download zur Verfügung steht: Es freut mich besonders, dass darin herausgestellt wird, dass Open Source AI gerade für Kleine und Mittlere Unternehmen (KMU) geeignet ist, Digitale Souveränität im Unternehmen zu erzielen. Am Ende des Kurzlehrbuchs fassen die Autoren die fünf wichtigsten Punkte noch einmal zusammen:
Mittelstand Digital Fokus Mensch (2026): Digitale Souveränität als Basis für sichere KI-Anwendungen | PDF.
(1) Die Arbeitswelt verändert sich – wir müssen uns mit verändern.
(2) Generative KI kann schon bei kleinen Aufgaben große Wirkung entfalten.
(3) Die Entscheidung für KI ist individuell – ebenso die Wahl der passenden Anwendung.
(4) KI-Nutzung erfordert rechtliche Orientierung – insbesondere im Hinblick auf den EU AI Act.
(5) Menschen müssen Teil der Lösung sein – sowohl bei KI als auch bei Cybersicherheit
Diese Website benutzt Cookies. Wenn du die Website weiter nutzt, gehen wir von deinem Einverständnis aus.