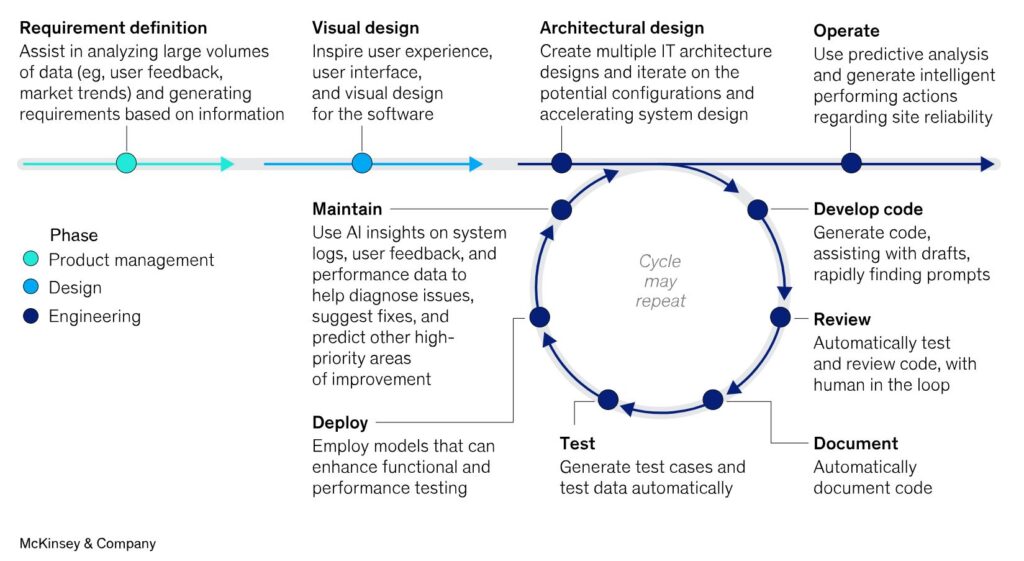
Wie in dem Beitrag von McKinsey (2024) ausführlich erläutert wird, beeinflusst Künstliche Intelligenz (GenAI) alle Schritte/Phasen der Softwareentwicklung. Drüber hinaus werden in Zukunft immer mehr KI-Agenten einzelne Tasks eigenständig übernehmen, oder sogar über Multi-Agenten-Systeme ganze Entwicklungsschritte.
Die Softwareentwicklung hat dazu beigetragen, dass Anwendungen der Künstlichen Intelligenz heute überhaupt möglich sind. Es kann allerdings sein, dass Künstliche Intelligenz viele Softwareentwickler und deren Unternehmen überflüssig macht.
Möglicherweise ist in Zukunft auch jeder Einzelne Mensch in der Lage, sich mit Künstlicher Intelligenz kleine erste Programme schreiben zu lassen – ohne dass Programmierkenntnisse erforderlich sind. Ganz im Sinne von Low Code, No Code und Open Source.
Es ist schon erstaunlich, wie unreflektiert viele Privatpersonen, Organisationen oder auch Öffentliche Verwaltungen Künstliche Intelligenz (AI / GenAI) von den bekannten Tech-Unternehmen nutzen. Natürlich sind diese Closed Source AI Models, oder auch Open Weights Models, sehr innovativ und treiben durch immer mehr neue Funktionen die Anwender vor sich her. Viele kommen dabei gar nicht richtig zum Nachdenken. Möglicherweise ist das ja auch so gewollt….
Hinzu kommt noch, dass es immer mehr länderspezifische KI-Modelle gibt, die den sprachlichen Kontext, und damit die sprachlichen Besonderheiten besser abbilden. Die wichtigsten LLM (Closed Source AI) sind mit englischsprachigen Daten trainiert und übersetzen dann in die jeweilige Sprache. Das klappt zwar recht gut, doch fehlt es gerade bei Innovationen, oder kulturellen regionalen Besonderheiten, an der genauen Passung.
Die spanische Verwaltung hat nun die Initiative ALIA gestartet, die 100% öffentlich finanziert ist, und eine KI-Ressource für alle Spanisch sprechenden Menschen sein soll. Dazu gehören auch frei verfügbare AI Modelle (LLM) (…)
“(…) to generate ethical and trustworthy AI standards, with open-source and transparent models, guaranteeing the protection of fundamental rights, the protection of intellectual property rights and the protection of personal data, and developing a framework of best practices in this field (Vasquez in OSOR 2025).
“ALIA es una iniciativa pionera en la Unión Europea que busca proporcionar una infraestructura pública de recursos de IA, como modelos de lenguaje abiertos y transparentes, para fomentar el impulso del castellano y lenguas cooficiales -catalán y valenciano, euskera y gallego- en el desarrollo y despliegue de la IA en el mundo” (ALIA Website)
Es freut mich zu sehen, wie die einzelnen europäischen Regionen oder Länder Initiativen starten, die die europäischen, oder auch regionalen Besonderheiten berücksichtigen – und das alles auf Open Source Basis. Siehe dazu auch
Die Grafik illustriert den Zusammenhang noch einmal anhand der zwei Dimensionen Degree of Openness und Completeness. Man sieht hier deutlich, dass der Firmenname OpenAI dazu führen kann, z.B. ChatGPT von OpenAI als Open Source AI zu sehen, obwohl es komplett intransparent ist und somit in die Kategorie Closed Source AI gehört. Die Open Weights Models liegen irgendwo zwischen den beiden Polen und machen es nicht einfacher, wirkliche Open Source AI zu bestimmen.
Eine erste Entscheidungshilfe kann die Definition zu Open Source AI sein, die seit 2024 vorliegt. Anhand der (recht wenigen) Kriterien kann man schon eine erste Bewertung der Modelle vornehmen.
In der Zwischenzeit hat sich auch die Wissenschaft dem Problem angenommen und erste Frameworks veröffentlicht. Ein erstes Beispiel dafür ist hier zu finden:
White et al. (2024): The Model Openness Framework: Promoting Completeness and Openness for Reproducibility, Transparency, and Usability in Artificial Intelligence | Quelle).
Die Abhängigkeit von amerikanischen oder chinesichen KI-Anbietern ist zu einem großen Problem in Europa geworden, da wir in Europa einen anderen Ansatz im Umgang mit Künstlicher Intelligenz haben. Siehe dazu Digitale Souveränität: Europa, USA und China im Vergleich.
Wir haben beispielsweise im ersten Schritt Nextcloud als Alternative zu den bekannten Microsoft-Produkten auf einem eigenen Server installiert, und weitere Bausteine wie Open Project, Moodle usw. integriert. In Nextcloud ist ein Assistent integriert, über den wir auch KI-Modelle lokal (LocalAI) auf unserem Server nutzen können. Siehe dazu auch LocalAI: Aktuell können wir aus 713 Modellen auswählen.
Eine professionelle Möglichkeit, KI-Agenten zu nutzen – also Prozesse mit internen/externen Daten und KI-Modellen zu kombinieren – haben wir mit Langflow (Open Source) auf unserem Server installiert. Siehe dazu AI Agents: Langflow (Open Source) auf unserem Server installiert. Mit der neuen Version 1.4 stehen uns nun stark erweiterte Funktionen zur Verfügung. In dem Beitrag Langflow 1.4: Organize Workflows + Connect with MCP werden diese ausführlich erläutert:
This release introduces Projects, a new way to organize, modularize, and expose your AI workflows.
Beyond organization, Projects are now also MCP servers! MCP (Model Context Protocol) is an open standard from Anthropic designed to establish seamless interoperability between LLM applications and external tools, APIs, or data sources.
In der nächsten Zeit werden wir verschiedene Anwendungen für KI-Agenten testen und unsere Erafhrungen hier mitteilen.
Auch bei dem Thema Smart City wird oft der Begriff “Intelligenz” verwendet. Dabei denkt man meistens an die noch vorherrschende Meinung, dass sich Intelligenz in einem Intelligenz-Quotienten (IQ), also in einer Zahl, darstellen lässt.
Die Entgrenzungstendenzen bei dem Thema Intelligenz in den letzten Jahrzehnten zeigen allerdings, dass der Intelligenz-Quotient gerade bei komplexen Problemlösungen nicht mehr ausreicht – somit keine Passung mehr zur Wirklichkeit hat. Begriffe wie “Soziale Intelligenz”, “Multiple Intelligenzen” oder auch “Emotionale Intelligenz” werden in diesem Zusammenhang genannt. Am Beispiel einer Smart City, oder später einer AI City, wird das wie folgt beschrieben:
“For a smart city, having only “IQ” (intelligence quotient) is not enough; “EQ” (emotional quotient) is equally essential. Without either, the abundant data generated and accumulated in urban life may either remain dormant and isolated or be used solely for data management without truly serving the people. In the concept of an AI-driven city, emotional intelligence refers to utilizing technological means to better perceive the emotions of citizens in the era of the “Big Wisdom Cloud.” This involves actively expressing urban sentiment, self-driving and motivating the emotions of citizen communities, empathizing with the vulnerable in the city, and establishing a comprehensive sentiment feedback mechanism” (Wu 2025).
Es wird in Zukunft immer wichtiger werden, ein besseres Verständnis von Intelligenz zu entwickeln, das besser zu den heutigen Entwicklungen passt. Die angesprochene Entgrenzung des Konstrukts “Intelligenz” ist dabei ein Ansatz, die Perspektive auf Intelligenz als biopsychologisches Potential eine weitere:
„Ich verstehe eine Intelligenz als biopsychologisches Potenzial zur Verarbeitung von Informationen, das in einem kulturellen Umfeld aktiviert werden kann, um Probleme zu lösen oder geistige oder materielle Güter zu schaffen, die in einer Kultur hohe Wertschätzung genießen“ (Gardner 2002:46-47).
Das Konzept einer Smart City wird in vielen Regionen der Welt schon umgesetzt: “In einer Smart City wird intelligente Informations- und Kommunikationstechnologie (IKT) verwendet, um Teilhabe und Lebensqualität zu erhöhen und eine ökonomisch, ökologisch und sozial nachhaltige Kommune oder Region zu schaffen” (BSI). Der Schwerpunkt liegt somit auf der Verwendung von IKT.
Nun gibt es mit Hilfe der Künstlichen Intelligenz (AI: Artificial Intelligence) ganz neue Möglichkeiten, die über das Konzept einer Smart City hinausgehen. Der folgende Text stammt aus einem Buch des führenden Wissenschaftlers, der sich mit dem Konzept einer “AI City” befasst:
“The essence of an AI city is empowerment. In the definition of “AI city,” the city obtains strong empowerment in urban organization and civilization development with the help of AI. The past process of urban intelligence emphasized information networking and promoted the comprehensive construction of smart cities. But the AI city is different: the city begins to learn and, after learning, better empowers life, production, and ecology through the learning process in order to continuously improve the energy level. The data of the daily operation of the city has become the different raw materials of AI technology, once data integration is fully achieved— spanning macro-level aspects such as society, economy, environment, and transportation, down to micro-level aspects such as individual and group activities—the overall functioning of the city will significantly improve. It is not the simple general smart city, but the intelligence that can learn. In the AI 2.0 era, with the break-through of the five key technologies of big data intelligence, swarm intelligence, autonomous unmanned systems, cross-media intelligence, and hybrid enhanced intelligence, the ability of AI city learning, problem solving, and empowerment has been greatly improved, moreover, numerous patterns and insights can be discovered within massive datasets. Therefore, the city began to iterate, and the urban agglomeration began to interact deeply. After learning, AI can formulate city rules according to a reasonable ideal vision. And when this formulation becomes the goal of deduction, the city can constantly predict, evolve, and revise itself” (Wu 2025: The AI City).
Die neuen Chancen der Künstlichen Intelligenz in Städten oder Ballungszentren, für die Menschen und deren Probleme zu nutzen, sollte dabei auf Transparenz bei den verwendeten KI-Anwendungen basieren. Diese Bedingung erfüllen die meisten Closed Source Modelle der Tech-Giganten aktuell nicht. Wenn es wirklich um die Menschen geht, und nicht primär im wirtschaftliche Interessen (USA) oder parteipolitische Interessen (China), so kommen für mich hier nur Open Source KI-Modelle und – Anwendungen infrage.
AI (Artificial intelligence) AI management and support technology in the Business plan marketing success customer. AI management concept.
Aktuell überschlagen sich die Meldungen darüber, wie die Zukunft von Künstlicher Intelligenz (AI: Artificial Intelligence) wohl aussehen wird. Die Dynamik ist in diesem Feld allerdings so groß, dass es unmöglich ist, genauere Voraussagen zu machen.
Dennoch glauben einige, dass ein Modell, wie z.B. ChatGPT, Gemini usw. mit ihren vielfältigen Möglichkeiten, die Lösung für alles sein wird. Grundannahme ist hier also One Size fits all.
Demgegenüber steht der Gedanke, dass es viele unabhängig und vernetzt nutzbare KI-Anwendungen geben wird, die eher den Anforderungen der Menschen und Organisationen entsprechen. Weiterhin sollten diese KI-Apps Open Source sein, also offen und transparent. Dazu habe ich den folgenden aktuellen Text gefunden:
“The future of AI is not one amazing model to do everything for everyone (you will hear us tell you time and time again in this book: one model will not rule them all). AI’s future will not just be multimodal (seeing, hearing, writing, and so on); it will also most certainly be multimodel (in the same way cloud became hybrid). AI needs to be democratized—and that can only happen if we collectively leverage the energy and the transparency of open source and open science—this will give everyone a voice in what AI is, what it does, how it’s used, and how it impacts society. It will ensure that the advancements in AI are not driven by the privileged few, but empowered by the many” (Thomas, R.; Zikopoulos, P.; Soule, K. 2025).
Es wird hier noch einmal deutlich herausgestellt, dass Künstliche Intelligenz demokratisiert werden muss. Das wiederum kann durch Open Source und Open Science ermöglicht werden. Siehe dazu auch
In dem Blogbeitrag Open Source AI-Models for Europe: Teuken 7B – Training on >50% non English Data hatte ich schon erläutert, wie wichtig es ist, dass sich Organisationen und auch Privatpersonen nicht nur an den bekannten AI-Modellen der Tech-Giganten orientieren. Ein wichtiges Kriterien sind die dort oftmals hinterlegten Daten, die natürlich zum überwiegenden Teil in Englisch (oder Chinesisch) vorliegen.
In Europa haben wir gegenüber China und den USA in der Zwischenzeit ein eigenes Verständnis von der gesellschaftlichen Nutzung der Künstlichen Intelligenz entwickelt (Blogbeitrag). Dabei spielen die technologische Unabhängigkeit (Digitale Souveränität) und die europäische Kultur wichtige Rollen.
Die jeweiligen europäischen Kulturen drücken sich in den verschiedenen Sprachen aus, die dann auch möglichst Bestandteil der in den KI-Modellen genutzten Trainingsdatenbanken (LLM) sein sollten – damit meine ich nicht die Übersetzung von englischsprachigen Texten in die jeweilige Landessprache.
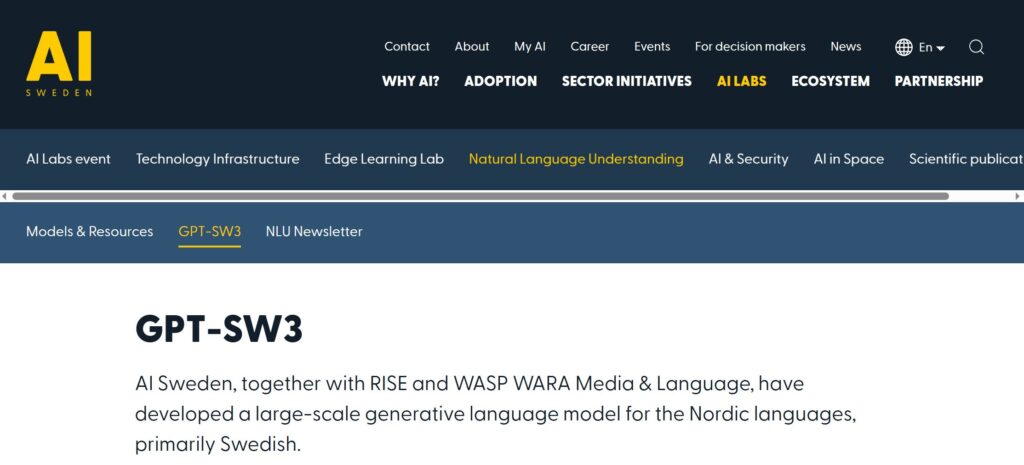
Ein Beispiel für so eine Entwicklung ist AI SWEDEN mit dem veröffentlichten GPT-SW3 (siehe Abbildung). Das LLM ist im Sinne der Open Source Philosophie (FOSS: Free Open Source Software) transparent und von jedem nutzbar – ohne Einschränkungen.
“GPT-SW3 is the first truly large-scale generative language model for the Swedish language. Based on the same technical principles as the much-discussed GPT-4, GPT-SW3 will help Swedish organizations build language applications never before possible” (Source).
Für schwedisch sprechende Organisationen – oder auch Privatpersonen – bieten sich hier Möglichkeiten, aus den hinterlegten schwedischen Trainingsdaten den kulturellen Kontext entsprechend Anwendungen zu entwickeln. Verfügbar ist das Modell bei Huggingface.
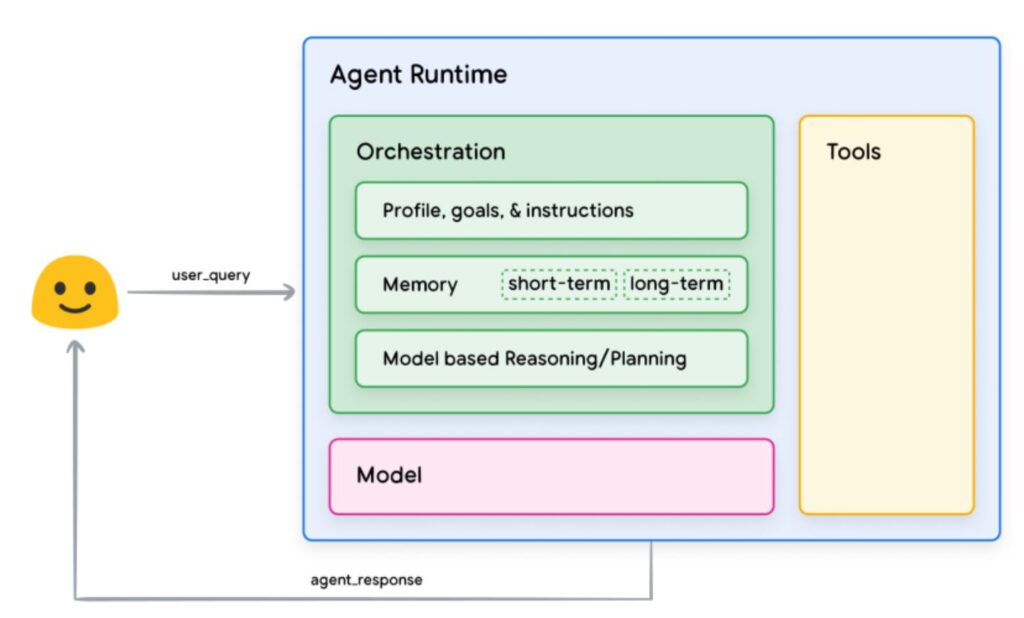
General agent architecture and components (Wiesinger et al. (2024): Agents)
In der letzten Zeit kommt immer mehr der Begriff AI Agent – oder auch Gen AI Agent – auf. Mit Hilfe der Abbildung möchte ich die Zusammenhänge der verschiedenen Komponenten erläutern.
Die Modelle (Model), oft als Language Models, Small Language Models oder Large Language Models (LLM) bezeichnet, enthalten eine sehr große Menge an Trainingsdaten. Dabei können Open Source AI Models, Open Weights Models und Closed AI Models unterschieden werden. An dieser Stelle merkt man schon, wie wichtig die Auswahl eines geeigneten Modells ist. Diese Modelle sind üblicherweise nicht auf typische Tools oder Kombinationen von Tools trainiert. Oftmals wird dieser Teil dann mit Hilfe von immer detaillierteren Eingaben (Prompts, Dateien etc.) des Users spezifiziert.
Die Beschränkungen von Modellen bei der Interaktion mit der “äußeren Welt” kann durch geeignete Tools erweitert werden. Dazu können spezielle Datenbanken, API-Schnittstellen usw. genutzt werden. Siehe dazu auch RAG: KI-Basismodelle mit eigener Wissensbasis verknüpfen.
Der AI Agent orchestriert nun alle Komponenten, wie die Eingabe des Users, das jeweilige Modell (oder sogar mehrere), die Tools und gibt das Ergebnis (Output) für den User in der gewünschten Form aus.
Die Möglichkeit, AI Agenten zu erstellen, bieten in der Zwischenzeit viele kommerzielle KI-Anbieter an. Wir gehen demgegenüber den Weg, Open Source AI auf unserem Server zu installieren und zu nutzen:
AI Agenten konfigurieren wir mit Langflow (Open Source). Dabei können wir in Langflow auf sehr viele Open Source AI Modelle über Ollama (Open Source) zugreifen, und vielfältige Tools integrieren. Alle Daten bleiben dabei auf unserem Server.
Gerade Kleine und Mittlere Unternehmen (KMU) können es sich oftmals nicht leisten, eigene Trainingsmodelle (Large Language Models) zu entwickeln. KMU greifen daher gerne auf bekannte Modelle wie ChatGPT usw. zurück.
Es wird allerdings gerade bei innovativen KMU immer klarer, dass es gefährlich sein kann, eigene Datenbestände in z.B. ChatGPT einzugeben. Da diese Modelle nicht transparent sind ist unklar, was mit den eigenen Daten passiert.
Eine Möglichkeit aus dem Dilemma herauszukommen ist, RAG (Retrieval-Augmented Generation) zu nutzen – also ein Basismodell mit einer internen Wissensbasis zu verknüpfen:
“Retrieval-Augmented Generation (RAG): Bei RAG wird ein Basismodell wie GPT-4, Jamba oder LaMDA mit einer internen Wissensbasis verknüpft. Dabei kann es sich um strukturierte Informationen aus einer Datenbank, aber auch um unstrukturierte Daten wie E-Mails, technische Dokumente, Whitepaper oder Marketingunterlagen handeln. Das Foundation Model kombiniert die Informationen mit seiner eigenen Datenbasis und kann so Antworten liefern, die besser auf die Anforderungen des Unternehmens zugeschnitten sind” (heise business services (2024): KI für KMU: Große Sprachmodelle erfolgreich einsetzen – mit Finetuning, RAG & Co.).
Wir gehen noch einen Schritt weiter, indem wir (1) einerseits LocalAI und Open Source AI mit einem Assistenten nutzen, und (2) darüber hinaus mit Hilfe von Ollama und Langflow eigene KI-Agenten entwickeln, die auf Basis von Open Source AI Modellen und beliebig konfigurierbaren eigenen Input einen gewünschten Output generieren In dem gesamten Prozess bleiben alle Daten auf unserem Server.
Translate »
Diese Website benutzt Cookies. Wenn du die Website weiter nutzt, gehen wir von deinem Einverständnis aus.OK