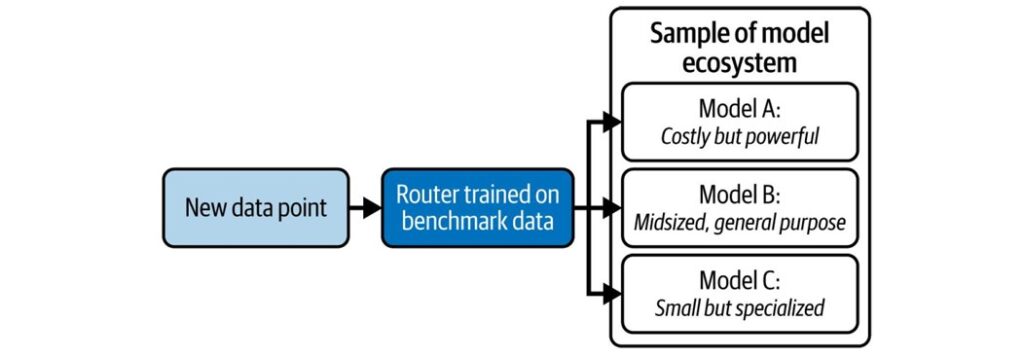
An AI router that understands the capabilities of models in its library directs a given inference request to the best model able to perform the task at hand (Thomas et al. 2025)
Wenn es um die bei der Anwendung von Künstlicher Intelligenz (GenAI) verwendeten Trainingsmodelle geht, stellt sich oft die Frage, ob ein großes Modell (LLM: Large Language Model) für alles geeignet ist – ganz im Sinne von „One size fits all“. Siehe dazu diesen Blogbeitrag zu den Vorteilen und Nachteilen dieser Vorgehensweise.
Neben den genannten Extremen gibt es noch Modelle, die dazwischen anzusiedeln sind, und daher als „midsized“ bezeichnet werden können.
Diese drei Möglichkeiten sind beispielhaft in der Abbildung unter „Sample of model ecosystem“ zusammengefasst. Erfolgt also eine neue Anfrage über den „New data point“ an den AI Router, so kann der vorher trainierte AI Router das geeignete Trainingsmodell (Small, Midsized, Large) zuweisen.
Die Autoren (Thomas et al. 2025) konnten in verschiedenen Tests zeigen, dass ein guter Mix an geeigneten Modellen, zusammen mit einem gut trainierten AI Router bessere und wirtschaftlichere Ergebnisse erzielt.
Die Vorteile liegen auf der Hand: Sie sparen Geld, reduzieren die Latenz und helfen der Umwelt. Diese Punkte sind gerade für Kleine und Mittlere Unternehmen (KMU) interessant.
Es ist schon eine Binsenweisheit, dass Künstliche Intelligenz (GenAI) alle Bereiche der Gesellschaft mehr oder weniger berühren wird. Das ist natürlich auch im Projektmanagement so. Dabei ist es immer gut, wenn man sich auf verlässliche Quellen, und nicht auf Berater-Weisheiten verlässt.
Eine dieser Quellen ist die Gesellschaft für Projektmanagement e.V., die immer wieder Studien zu verschiedenen Themen veröffentlicht. In der Studie GPM (2025): Gehalt und Karriere im Projektmanagement. Sonderthema: Die Anwendung Künstlicher Intelligenz im Projektmanagementfindet sich auf Seite 13 folgende Zusammenfassung:
„Künstliche Intelligenz im Projektkontext Künstliche Intelligenz (KI) wird im Bereich Projektmanagement in der Mehrheit der Unternehmen eingesetzt, allerdings in noch geringem Maße. (1) KI-basierte Tools werden insgesamt eher selten genutzt, wenn sie zum Einsatz kommen, dann sind es hauptsächlich ChatGPT, Jira, MS Pilot oder eigenentwickelte Tools. (2) Es zeichnet sich kein eindeutiger Projektmanagement-Bereich ab, in dem KI bevorzugt zum Einsatz kommt. Am deutlichsten noch in der Projektplanung und in der Projektinitiierung, am seltensten im Projektportfolio- und im Programmmanagement. (3) Der Nutzen der KI wird tendenziell eher positiv gesehen, insbesondere als Unterstützung der alltäglichen Arbeit, zur Erleichterung der Arbeit im Projektmanagement und zur Erhöhung der Produktivität. (4) Der Beitrag von KI zu einem höheren Projekterfolg wird von der Mehrheit der Befragten nicht gesehen – allerdings nur von einer knappen Mehrheit. (5) Es besteht eine grundlegende Skepsis gegenüber KI, was verschiedene Leistungsparameter im Vergleich zum Menschen betrifft. Alle hierzu gestellten Fragen wie Fehleranfälligkeit, Genauigkeit, Konsistenz der Information oder Konsistenz der Services wurden mehrheitlich zu Gunsten des Menschen bewertet. (6) Die überwiegende Mehrheit der befragten Projektmanagerinnen und Projektmanager teilt diverse Ängste gegenüber der KI nicht, wie z. B. diese werde Jobs vernichten oder dem Menschen überlegen sein.“ Quelle: GPM (2025). Anmerkung: Im Originaltext wurden Aufzählungszeichen verwendet. Um besser auf einzelnen Punkte einzugehen, habe ich diese nummeriert, was somit keine Art von Priorisierung darstellt.
An dieser Stelle möchte ich nur zwei der hier genannten Ergebnisse kommentieren:
Punkt (1): Es wird deutlich, dass hauptsächlich Closed Source Modelle verwendet werden. Möglicherweise ohne zu reflektieren, was mit den eigenen Daten bei der Nutzung passiert – gerade wenn auch noch eigene, projektspezifische Daten hochgeladen werden. Besser wäre es, ein Open Source basiertes KI-System und später Open Source basierte KI-Agenten zu nutzen. Dazu habe ich schon verschiedene Blogbeiträge geschrieben. Siehe dazu beispielhaft Open Source AI: Besser für einzelne Personen, Organisationen und demokratische Gesellschaften.
In dem Blogbeitrag Was unterscheidet Künstliche Intelligenz von Suchmaschinen? hatte ich dargestellt, wie sich Suchmaschinen von Künstlicher Intelligenz unterscheiden. Content-Anbieter können dabei nur bedingt auf Datenschutz, Urheberrecht, EU AI Act usw. vertrauen. In der folgenden Veröffentlichung sind die verschiedenen Punkte noch einmal strukturiert zusammengefasst, inkl. einer möglichen Lösung für die skizzierten Probleme:
Creative Commons (2025): From Human Content to Machine Data. Introducing CC Signals | PDF
Creative Commons (CC) kennen dabei viele von uns als eine Möglichkeit, anderen unter bestimmten Bedingungen das Recht zur Nutzung des eigenen Contents einzuräumen. Creative Commons erläutert, dass KI-Modelle die üblichen gesellschaftlichen Vereinbarungen mehr oder weniger ignoriert, und somit den „social contract“ aufkündigt. Diesen Hinweis finde ich bemerkenswert, da hier das Vorgehen der KI-Tech-Unternehmen mit den möglichen gesellschaftlichen Auswirkungen verknüpft wird.
Mit CC Signalshat Creative Commons ein erstes Framework veröffentlich, das es ermöglichen soll, Content mit Berechtigungsstufen für KI-Systeme zu versehen.
„CC signals are a proposed framework to help content stewards express how they want their works used in AI training—emphasizing reciprocity, recognition, and sustainability in machine reuse. They aim to preserve open knowledge by encouraging responsible AI behavior without limiting innovation“ (ebd.)
Machen Sie bei der Weiterentwicklung dieses Ansatzes mit:
Zielgruppe für Wolpers, S. (2020): The Remote Agile Guide sind Scrum Master, Product Owner und Agile Coaches, die mit einem oder mehreren verteilten Team(s) zusammenarbeiten. Dabei wird der Download als „free“ bezeichnet, obwohl man sich einschreiben muss – „Subscribe Now“.- und somit mit seinen Daten bezahlt. Ich weiß durchaus, dass diese Vorgehensweise üblich ist, dennoch mag ich es nicht.
Insgesamt bietet der Guide eine gute Basis, sich über die verteilte digitale Zusammenarbeit Gedanken zu machen, und konkrete Möglichkeit für die eigene Vorgehensweise abzuleiten. Der Guide, auf den ich mich beziehe, stammt aus dem Jahr 2020. Dazu möchte ich noch einige Anmerkungen machen:
Zunächst wird mir der technische Aspekt der Zusammenarbeit zu stark betont (MS Teams, Zoom, Trello, Jira, etc.). Die Neurowissenschaften haben dazu beispielsweise bei der Nutzung von Zoom in der Zwischenzeit wichtige Hinweise gegeben: „Zoom scheint im Vergleich zu persönlichen Gesprächen ein dürftiges soziales Kommunikationssystem zu sein.“ Sieh Persönliche Gespräche und Zoom im Vergleich: Das sagt die Neurowissenschaft dazu. Weiterhin erwähnt auch schon das Agile Manifest aus dem Jahr 2001, dass der persönliche Austausch bei komplexen Problemlösungsprozesse wichtig ist, da es dabei um die wichtige implizite Dimension des Wissens geht. Diese ist mit Technologie nur bedingt zu erschließen.
Weiterhin werden in dem Guide zu wenige Open Source Alternativen genannt, die die remote Arbeit in verteilten Teams unterstützen können. Gerade wenn es um die heute wichtige Digitale Souveränität geht, ist das wichtig. Siehe dazu beispielhaft Souveränitätsscore: Zoom und BigBlueButton im Vergleich.
Nicht zuletzt geht es heute auch darum, in verteilten Teams im agilen Prozess der Zusammenarbeit Künstliche Intelligenz zu nutzen. Aus meiner Sicht ist auch hier die Nutzung von Open Source AI zeitgemäß.
Diese Anmerkungen sind als Ergänzungen zu verstehen. Möglicherweise ergibt sich daraus ja noch ein weiterer, aktualisierter Guide.
Es ist für Unternehmen heute nicht leicht, eine geeignete Strategie für Innovationen zu entwickeln. Dabei können inkrementelle oder auch disruptive Innovationen im Fokus stehen. Kleine, inkrementelle Verbesserungen sind möglicherweise in Zeiten von Künstlicher Intelligenz (Artificial Intelligence) nicht mehr ausreichend. An dieser Stelle kommt die Blue-Ocean-Strategie ins Spiel:
„Die Blue-Ocean-Strategie beschäftigt sich mit disruptiven Verbesserungen von Produkten bzw. Produktideen. Disruption (= zerstören, unterbrechen) beschreibt einen Prozess, bei dem ein bestehendes Geschäftsmodell oder ein Markt von Innovationen abgelöst bzw. verdrängt wird. Die Blue-Ocean-Strategie unterteilt Märkte in sogenannte Red Oceans und Blue Oceans. Blue Oceans umfassen zukünftige, noch zu schaffende Markträume, in denen Wettbewerb eine Zeit lang wenig Relevanz hat. Der Fokus von Unternehmen liegt auf dem Aufbau von Nutzeninnovationen für die Kundschaft in neuen Markträumen. Dadurch erreichen Blue-Ocean-Produkte eine Differenzierung (Alleinstellungsmerkmale); sie sind zunächst wettbewerbsarm und erlauben höhere Gewinne (vgl. Kim/ Mauborgne 2015). Red Oceans umfassen hingegen die Gesamtheit des bereits bestehenden Wettbewerbs. Es gilt die existierende Nachfrage zu nutzen und zu steigern, um sich im bestehenden Wettbewerb zu behaupten“ (RKW 2018).
Was hat das nun mit Künstlicher Intelligenz zu tun? Wie ich in dem Beitrag Warum wird GESCHÄFTSMODELL + AI nicht ausreichen? erläutert habe, ist es in Zukunft nicht mehr ausreichend, einfach zu den bestehenden Innovationsprozessen Künstliche Intelligenz hinzuzunehmen. Es kommt eher darauf an, die Möglichkeiten von Künstlicher Intelligenz (Artificial Intelligence) für ganz neue/neuartige Produkte und Dienstleistungen zu nutzen. Ganz im Sinne von AI +. Mit AI meine ich dabei immer Open Source AI.
Wenn es um allgemein verfügbare Daten aus dem Internet geht, können die bekannten Closed Source KI-Modelle erstaunliche Ergebnisse liefern. Dabei bestehen die genutzten Trainingsdaten der LLMs (Large Language Models) oft aus den im Internet verfügbaren Daten – immer öfter allerdings auch aus Daten, die eigentlich dem Urheberrecht unterliegen, und somit nicht genutzt werden dürften.
Wenn es um die speziellenDaten einer Branche oder eines Unternehmens geht, sind deren Daten nicht in diesen Trainingsdaten enthalten und können somit bei den Ergebnissen auch nicht berücksichtigt werden. Nun könnte man meinen, dass das kein Problem darstellen sollte, immerhin ist es ja möglich ist, die eigenen Daten für die KI-Nutzung zur Verfügung zu stellen – einfach hochladen. Doch was passiert dann mit diesen Daten?
Wollen Sie wirklich IHRE Daten solchen Modellen zur Verfügung stellen, um DEREN Wettbewerbsfähigkeit zu verbessern?
„So here’s the deal: you’ve got data. That data you have access to isn’t part of these LLMs at all. Why? Because it’s your corporate data. We can assure you that many LLM providers want it. In fact, the reason 99% of corporate data isn’t scraped and sucked into an LLM is because you didn’t post it on the internet. (…) Are you planning to give it away and let others create disproportionate amounts of value from your data, essentially making your data THEIR competitive advantage OR are you going to make your data YOUR competitive advantage?“ (Thomas et al. 2025).
Doch was ist die Alternative? Nutzen Sie IHRE Daten zusammen mit Open Source AI auf ihren eigenen Servern. Der Vorteil liegt klar auf der Hand: Alle Daten bleiben bei Ihnen.
AI (Artificial intelligence) AI management and support technology in the Business plan marketing success customer. AI management concept.
Der Finanzbereich mit seinen unglaublichen Mengen an Daten (historische Daten und Echtzeitdaten) ist prädestiniert für den Einsatz Künstlicher Intelligenz (KI, oder englisch AI: Artificial Intelligence). Die Nutzung von LLM (Large Language Models) ,oder in Zukunft Small Language Models (SLM) und KI-Agenten, kann für eine Gesellschaft positiv, oder eher negativ genutzt werden. Dabei können Open Source AI Models, Open Weights Models und Closed AI Models unterschieden werden.
Es ist aus meiner Sicht gut, dass die Europäische Union mit dem EUAI-Act weltweit erste Rahmenbedingungen für die Nutzung Künstlicher Intelligenz festgelegt hat. Im Vergleich zu dem US-amerikanischen vorgehen (KI-Unternehmen können alles machen, um Profite zu generieren) und dem chinesischen Vorgehen (KI für die Unterstützung der Partei), ist der Europäische Weg eine gute Mischung. Natürlich muss dabei immer abgewogen werden, welcher Freiraum für Innovationen bleiben sollte.
Um nun herauszufinden, wie KI-Ssteme z.B. für den Finanzbereich bewertet und letztendlich ausgewählt werden sollten, hat das Federal Office for Information Security (Deutsch: BSI) einen entsprechenden Kriterienkatalog veröffentlicht:
„Publication Notes Given the international relevance of trustworthy AI in the financial sector and the widespread applicability ofthe EUAIAct across memberstates and beyond,this publication was prepared in English to ensure broader accessibility and facilitate collaboration with international stakeholders. English serves as the standard language in technical, regulatory, and academic discourse on AI, making it the most appropriate choice for addressing a diverse audience, including researchers, industry professionals, and policymakers across Europe and globally“ (Federal Office for Information Security 2025).
Es stellt sich dabei auch die Frage, ob diese Kriterien nur für den Finanzbereich geeignet sind, oder ob alle – oder einige – der Kriterien auch für andere gesellschaftlichen Bereiche wichtig sein könnten.
Das Bild zeigt ein Glas mit einer Flüssigkeit. Es ist allerdings nicht genau zu erkennen, um welchen Inhalt es sich handelt. Es könnte also sein, dass die Flüssigkeit gut für Ihre Gesundheit ist, oder auch nicht. Vertrauen Sie dieser Situation? Vertrauen Sie demjenigen, der das Glas so hingestellt hat?
Würden Sie aus diesem Glas trinken?
So ähnlich ist die Situation bei Künstlicher Intelligenz. Die Tech-Unternehmen veröffentlichen eine KI-Anwendung nach der anderen. Privatpersonen, Unternehmen, ja ganze Verwaltungen nutzen diese KI-Apps als Black Box, ohne z.B. zu wissen, wie die Daten in den Large Language Models (LLM) zusammengetragen wurden – um nur einen Punkt zu nennen.
Der Vergleich von dem Glas mit Künstlicher Intelligenz hinkt zwar etwas, doch erscheint mir die Analogie durchaus bemerkenswert, da der erste Schritt zur Anwendung von Künstlicher Intelligenz Vertrauen sein sollte.
Step 1: It All Starts with Trust „Think about it: the glass is opaque, you can’t even see inside it! The water inside that glass could pure spring water, but it could also be cloudy and murky puddle water, or even contaminated water! If you couldn’t see inside that glass, would you still drink what’s inside it after adding tons of high-quality sugar and lemon to it? Probably not, so why would you do this with one of your company’s most previous assets—your data?“ (Thomas et al. 2025).
Vertrauen Sie der Art von Künstlicher Intelligenz, wie sie von den etablierten Tech-Giganten angeboten wird? Solche Closed Source Modelle sind nicht wirklich transparent, und wollen es auch weiterhin nicht sein. Siehe dazu auch Das Kontinuum zwischen Closed Source AI und Open Source AI.
Aktuell wird alles mit Künstlicher Intelligenz (AI: Artificial Intelligence) in Verbindung gebracht. Die Neukombination von bestehenden Ansätzen kann dabei zu interessanten Innovationen führen.
Die Website ALL Our Ideas verbindet beispielsweise Online-Umfragen mit Crowdsourcing und Künstlicher Intelligenz.
„All Our Ideas is an innovative tool that you can use for large-scale online engagements to produce a rank-ordered list of public input. This „Wiki Survey“ tool combines the best of survey research with crowdsourcing and artificial intelligence to enable rapid feedback“ (ebd.).
Ein kurzes Tutorial ist gleich auf der Website zu finden. Darin wird erläutert, wie Sie die Möglichkeiten selbst nutzen können. Starten Sie einfach mit einer eigenen Online-Umfrage.
Die Idee und das Konzept finde ich gut, da auch der Code frei verfügbar ist: Open Source Code. Damit kann alles auf dem eigenen Server installiert werden. Bei der Integration von KI-Modellen schlage ich natürlich vor, Open Source KI (Open Source AI) zu nutzen.
Organisationen und Privatpersonen befassen sich mit Künstlicher Intelligenz (GenAI) und sind fasziniert von den Möglichkeiten. Dabei setzen fast alle Organisationen auf die Formel
GESCHÄFTSMODELL +AI
Gut zu erkennen ist das beispielsweise in dem Beitrag Künstliche Intelligenz beeinflusst den gesamten Lebenszyklus der Software-Entwicklung. Man geht von dem üblichen Softwareentwicklungsprozess aus und überlegt, wie Künstliche Intelligenz in den einzelnen Schritten (einzelnen Tasks) genutzt werden kann. Ähnlich ist es im Projektmanagement, z.B. nach DIN 69901 mit den vorgeschlagenen Minimum-Prozessen usw. usw. In dem Zusammenhang habe ich folgenden Text gefunden:
„(…) if you’re content to sit on your +AI mindset, things aren’t going to go well for your business (or you personally) because you will lack the agility and capability that come with the next generation of AI“ (Thomas et al. 2025).
In Zukunft bietet Künstliche Intelligenz, und hier meine ich speziell auch Agentic AI (KI-Agenten), ganz neue, andere Möglichkeiten. Wir sollten daher mittel- und langfristig von einem anderen Ansatz (Mindset) ausgehen:
AI+
Dieser Blick sollte sich von den bestehenden Geschäftsmodellen lösen, und von den (neuen) Möglichkeiten der KI ausgehen. Das ist dann nicht mehr evolutionär, sondern eher disruptiv und wird ganze Bereiche verändern.