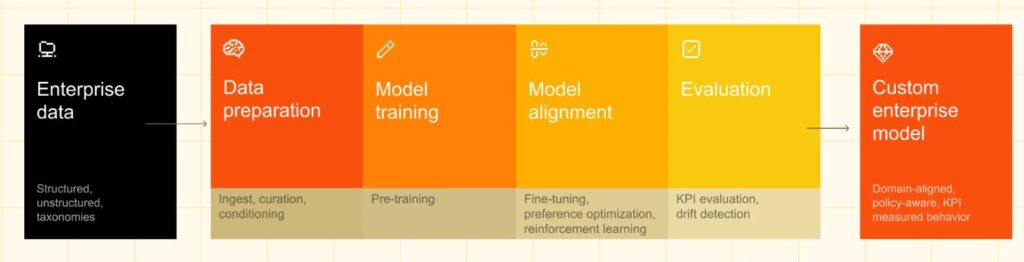
In dem Blogbeitrag Für agglutinierende Sprachen wie Ungarisch, Baskisch, etc. reichen die üblichen KI-Modelle nicht aus wurde deutlich, dass es beispielsweise für die ungarische Sprache gut ist, ein spezielles Modell zu haben. So ein Modell (LLM) liegt nun mit Racka (Regionális Adatokon Célzottan Kialakított Alapmodell) vor.
„We present Racka-4B, a lightweight, continually pretrained large language model designed to bridge the resource gap between Hungarian and high-resource languages such as English and German. (…) The results also showcase that Racka-4B is capable of Hungarian chat with English reasoning even in the absence of explicit Hungarian post-training on these tasks“ (Csibi, Z. et al. (2026): Racka: Efficient Hungarian LLM Adaptation on Academic Infrastructure | PDF).
Das Modell Racka-4B basiert auf Qwen-3 und steht bei Huggingface zur Verfügung. Es ist also transparent und offen – ganz im Gegensatz zu den proprietären KI-Modellen der großen Tech-Konzerne. Diese suggerieren, dass es ausreicht, ein Modell für alles zu haben.
Dieser One Size Fits All – Gedanke ist zwar aus deren Sicht wirtschaftlich interessant, doch trifft dieser Ansatz immer weniger die Bedürfnisse der Menschen. Auch Racka-4B bestätigt eine Entwicklung zu europäischen Sprach-Modellen, die stärker regionale Besonderheiten berücksichtigen. Siehe dazu auch
Die MCP Community of Europe trifft sich in diesem Jahr vom 16.-19.09.2026 auf der MCP 2026 in Balatonfüred, Ungarn. Neueste Entwicklungen zu Mass Customization and Personalization, auch in Zeiten von Künstlicher Intelligenz, werden auf der Konferenz vorgestellt und diskutiert. Die Konferenz findet seit 2004 durchgehend alle 2 Jahre statt – die MCP 2026 ist somit die 12. Konferenz ihrer Art.
Open EuroLLM: Ein Modell Made in Europe – eingebunden in unsere LocalAI
Künstliche Intelligenz: Das polnische Sprachmodell PLLuM
Minerva AI LLM: Das italienischsprachige KI-Modell