In dem Beitrag Künstliche Intelligenz: Würden Sie aus diesem Glas trinken? ging es um die Frage, ob man KI-Modellen vertrauen kann. Bei den Closed Source Models der Tech-Konzerne ist das kaum möglich, da die Modelle gar nicht, bzw. kaum transparent sind und nicht der Definition von Open Source AI entsprechen.
Wenn aber der erste Schritt zur Nutzung von Künstlicher Intelligenz Vertrauen sein sollte (Thomas et al. 2025), sollte man sich als Privatperson, als Organisation, bzw. als Verwaltung nach Alternativen umsehen.
Wie Sie als Leser unseres Blogs wissen, tendieren wir zu (wirklichen) Open Source AI Modellen, doch in dem Buch von Thomas et al. (2025) ist mir auch der Hinweis auf das von IBM veröffentlichte KI-Modell Granite aufgefallen. Die quelloffene Modell-Familie kann über Hugging Face, Watsonx.ai oder auch Ollama genutzt werden.
Das hat mich neugierig gemacht, da wir ja in unserer LocalAI Modelle dieser Art einbinden und testen können. Weiterhin haben wir ja auch Ollama auf unserem Server installiert, um mit Langflow KI-Agenten zu erstellen und zu testen.
Im Fokus der Granite-Modellreihe stehen Unternehmensanwendungen, wobei die kompakte Struktur der Granite-Modelle zu einer erhöhten Effizienz beitragen soll. Unternehmen können das jeweilige Modell auch anpassen, da alles über eine Apache 2.0-Lizenz zur Verfügung gestellt wird.
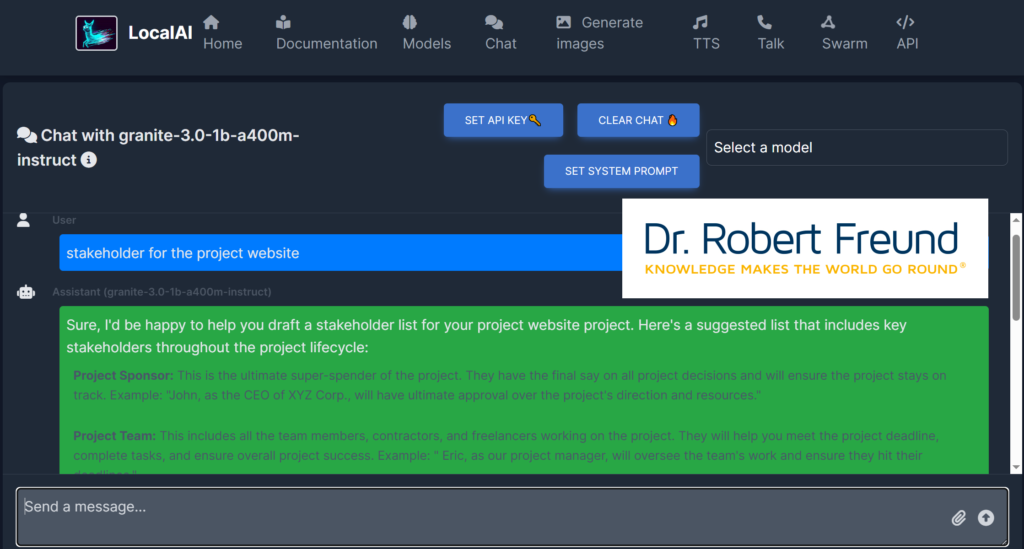
Wie Sie der Abbildung entnehmen können, haben wir Granite 3.0 -1b-a400m in unsere lokale KI (LocalAI) eingebunden. Das geht relativ einfach: Wir wählen aus den aktuell mehr als 1.000 Modellen das gewünschte Modell zunächst aus. Anschließend brauchen wir nur auf „Installieren“ zu klicken, und das Modell steht in der Auswahl „Select a model“ zur Verfügung.
Im unteren Fenster (Send a message) habe ich testweise „Stakeholder for the project Website“ eingegeben. Dieser Text erscheint dann blau hinterlegt, und nach einer kurzen Zeit kommen dann schon die Ergebnisse, die in der Abbildung grün hinterlegt sind. Wie Sie am Balken am rechten Rand der Grafik sehen können, gibt es noch mehrere Stakeholder, die man sieht, wenn man nach unten scrollt.
Ich bin zwar gegenüber Granite etwas skeptisch, da es von IBM propagiert wird, und möglicherweise eher zu den Open Weighted Models zählt, doch scheint es interessant zu sein, wie sich Granite im Vergleich zu anderen Modellen auf unserer LocalAI-Installation schlägt.
Bei allen Tests, die wir mit den hinterlegten Modellen durchführen, bleiben die generierten Daten alle auf unserem Server.


