In letzter Zeit gibt es immer mehr Meldungen, dass der Einsatz von Künstlicher Intelligenz in allen gesellschaftlichen Bereichen steigt. Doch nicht immer sind KI-Projekte erfolgreich und werden daher eingestellt – was bei neuen Technologien ja nicht ungewöhnlich ist. Siehe dazu beispielsweise Künstliche Intelligenz: 40% der Projekte zu Agentic AI werden wohl bis Ende 2027 eingestellt (Gartner).
Dennoch ist deutlich zu erkennen, dass es immer mehr Anbieter in allen möglichen Segmenten von Künstlicher Intelligenz – auch bei den Language Models – gibt. Wenn man sich alleine die Vielzahl der Modelle bei Hugging Face ansieht: Heute, am17.09.2025, stehen dort 2,092,823 Modelle zur Auswahl, und es werden jede Minute mehr. Das erinnert mich an die Diskussionen auf den verschiedenen (Welt-) Konferenzen zu Mass Customization and Personalization. Warum?
Large Language Models (LLM): One Size Fits All
Wenn es um die bei der Anwendung von Künstlicher Intelligenz (GenAI) verwendeten Trainingsmodellen geht, stellt sich oft die Frage, ob ein großes Modell (LLM: Large Language Model) für alles geeignet ist – ganz im Sinne von “One size fits all”. Diese Einschätzung wird natürlich von den Tech-Unternehmen vertreten, die aktuell mit ihren Closed Source Models das große Geschäft machen, und auch für die Zukunft wittern. Die Argumentation ist, dass es nur eine Frage der Zeit ist, bis das jeweilige Large Language Model die noch fehlenden Features bereitstellt – bis hin zur großen Vision AGI: Artificial General Intelligence. Storytelling eben…
Small Language Models (SLM): Variantenvielfalt
In der Zwischenzeit wird immer klarer, dass kleine Modelle (SLM) viel ressourcenschonender, in speziellen Bereichen genauer, und auch wirtschaftlicher sein können. Siehe dazu Künstliche Intelligenz: Vorteile von Small Language Models (SLMs) und Muddu Sudhakar (2024): Small Language Models (SLMs): The Next Frontier for the Enterprise, Forbes, LINK.
Komplexitätsfalle
Es wird deutlich, dass es nicht darum geht, noch mehr Möglichkeiten zu schaffen, sondern ein KI-System für eine Organisation passgenau zu etablieren und weiterzuentwickeln. Dabei sind erste Schritte schon zu erkennen: Beispielsweise werden AI-Router vorgeschlagen, die verschiedene Modelle kombinieren – ganz im Sinne eines sehr einfachen Konfigurators. Siehe dazu Künstliche Intelligenz: Mit einem AI Router verschiedene Modelle kombinieren.
Mit Hilfe eines KI-Konfigurators könnte man sich der Komplexitätsfalle entziehen. Ein Konfigurator in einem definierten Lösungsraum (Fixed Solution Space) ist eben das zentrale Element von Mass Customization and Personalization.
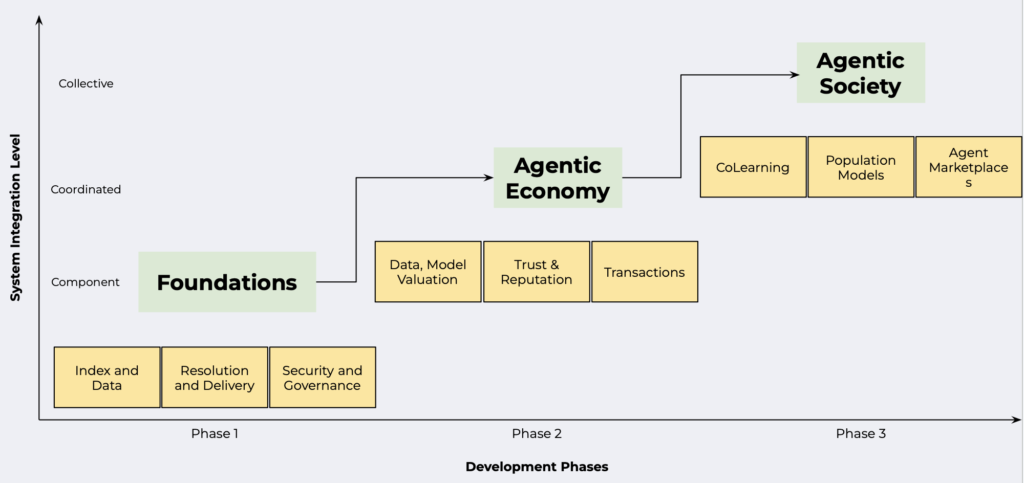
Die Lösung könnte also sein, massenhaft individualisierte KI-Modelle und KI-Agents dezentralisiert für die Allgemeinheit zu schaffen. Am besten natürlich alles auf Open Source Basis – Open Source AI – und für alle in Repositories frei verfügbar. Auch dazu gibt es schon erste Ansätze, die sehr interessant sind. Siehe dazu beispielsweise (Mass) Personalized AI Agents für dezentralisierte KI-Modelle.
Genau diese Überlegungen erinnern – wie oben schon angedeutet – an die Hybride Wettbewerbsstrategie Mass Customization and Personalization. Die Entgrenzung des definierten Lösungsraum (Fixed Solution Space) hat dann weiter zu Open Innovation (Chesbrough und Eric von Hippel) geführt.