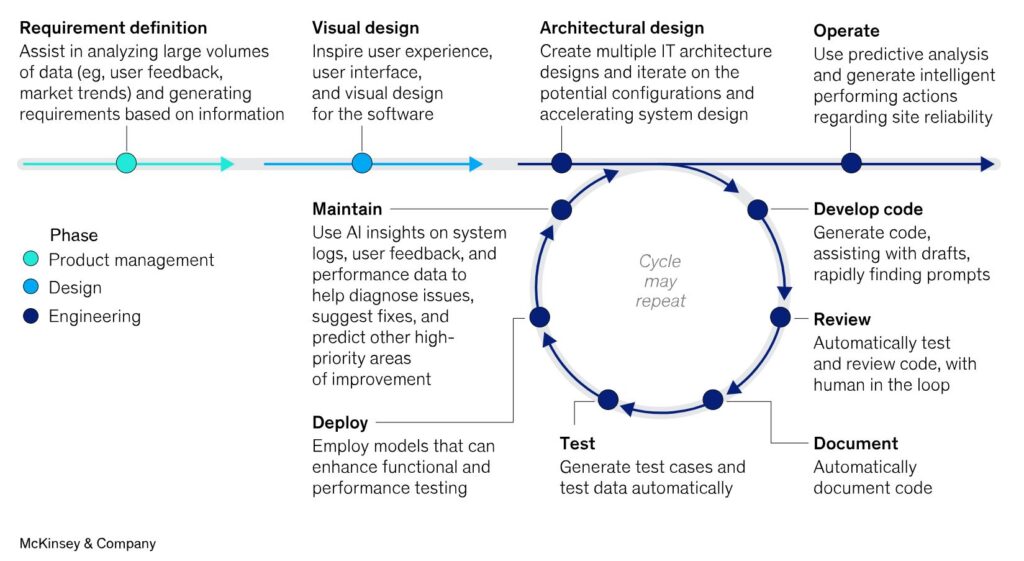
Wie in dem Beitrag von McKinsey (2024) ausführlich erläutert wird, beeinflusst Künstliche Intelligenz (GenAI) alle Schritte/Phasen der Softwareentwicklung. Drüber hinaus werden in Zukunft immer mehr KI-Agenten einzelne Tasks eigenständig übernehmen, oder sogar über Multi-Agenten-Systeme ganze Entwicklungsschritte.
Die Softwareentwicklung hat dazu beigetragen, dass Anwendungen der Künstlichen Intelligenz heute überhaupt möglich sind. Es kann allerdings sein, dass Künstliche Intelligenz viele Softwareentwickler und deren Unternehmen überflüssig macht.
Möglicherweise ist in Zukunft auch jeder Einzelne Mensch in der Lage, sich mit Künstlicher Intelligenz kleine erste Programme schreiben zu lassen – ohne dass Programmierkenntnisse erforderlich sind. Ganz im Sinne von Low Code, No Code und Open Source.
So eine Entwicklung kann als Reflexive Innovation bezeichnet werden: „Die Revolution frisst ihre eigenen Kinder“ (Quelle). Siehe dazu ausführlicher Freund, R.; Chatzopoulos, C.; Lalic, D. (2011): Reflexive Open Innovation in Central Europe.