In allen möglichen Kontexten soll und wird Künstliche Intelligenz genutzt. Dabei dominieren in unserem Kulturkreis die von den amerikanischen Konzernen entwickelten GenAI-Modelle. Diese werden in allen privaten und organisatorischen Prozessen integriert. Ein Großteil der Personen und Organisationen nutzen dabei die gleichen KI-Workflows.
Das hat beispielsweise im wissenschaftlichen Kontext einen unschönen Effekt: Dadurch, dass alle Wissenschaftler mehr oder weniger stark die selben GenAI-Modelle für ihre Arbeiten nutzen, kommt es zu einer Art „wissenschaftlicher Monokultur„.
Traberg, C.S., Roozenbeek, J. & van der Linden, S. AI is turning research into a scientific monoculture. Commun Psychol 4, 37 (2026). https://doi.org/10.1038/s44271-026-00428-5
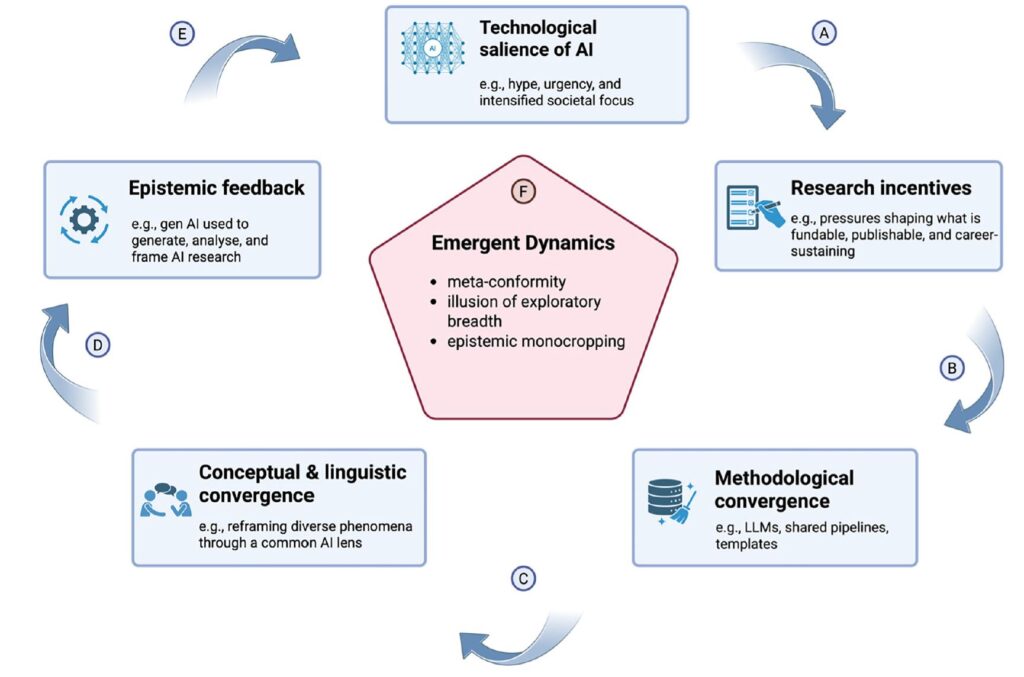
In der Abbildung ist der Kreislauf mit seinen einzelnen Schritten dargestellt. Es wird deutlich, dass es sich hier um eine Art Generator handelt, also ein sich selbst verstärkender Wirkungskreislauf.
Auch hier wird deutlich, dass es gut ist, verschiedene KI-Modelle für wissenschaftliche Arbeiten zu nutzen, und die jeweiligen Ergebnisse zu bewerten.
Es stellt sich natürlich auch gleich die Frage, ob diese „wissenschaftliche Monokultur“ auch bei Innovationsprozessen vorkommt. Auch hier nutzen viele Personen und Unternehmen oftmals die gleichen KI-Modelle.








