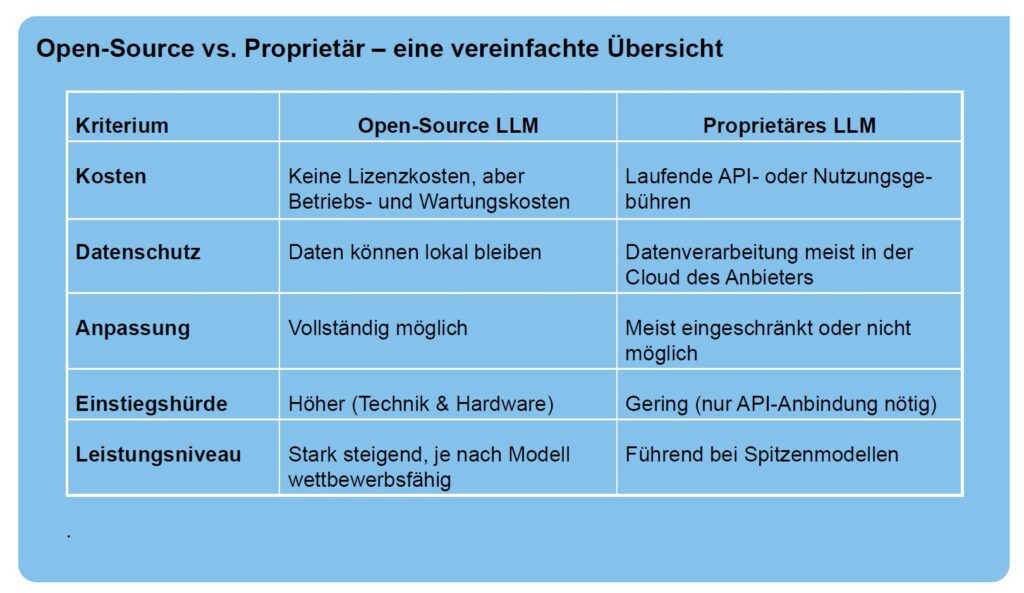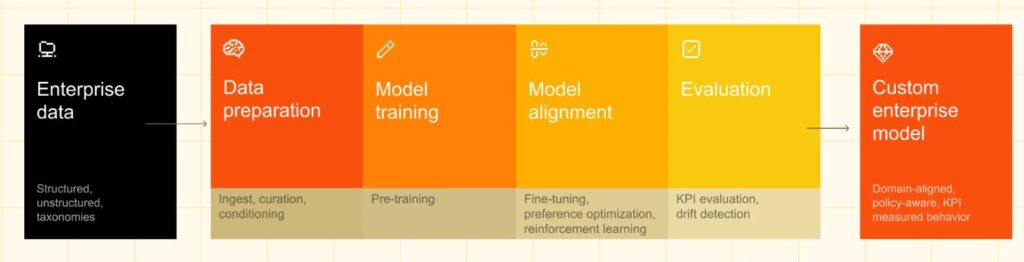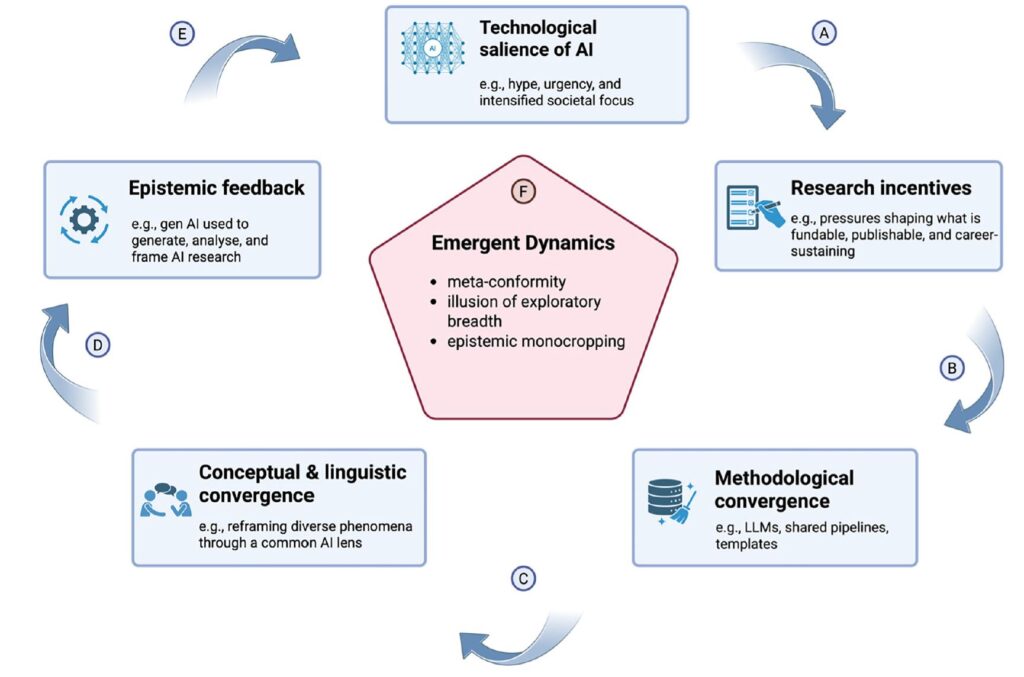
Über die Mistral 3 Modell-Familie, Mistral Le Chat und Mistral Forge habe ich hier schon ausführlich geschrieben. Mistral ist für die Digitale Souveränität in Europa wichtig, da alle KI-Anwendungen europäisch (französisch), DSGVO-konform und Open Source sind. Ganz im Sinne einer Digitalen Souveränität.
Was im Vergleich zu den bekannten proprietären KI-Anwendungen noch fehlte, war das Coding mit Mistral. Dazu wurde nun Mistral Vibe veröffentlicht:
„Agentic coding that meets you where you work. Write, test, and deploy autonomously with full codebase context“ (ebd.).
Da ich kein Experte für das Coding mit Künstlicher Intelligenz bin, habe ich einen Beitrag gesucht, der die Möglichkeiten von Mistral Vibe aus der Coding-Perspektive beschreibt. In dem Artikel Mistral Vibe 2.0: Der terminalbasierte KI-Codierungsagent von Oluseye Jeremiah, veröffentlicht am 02. Februar 2026 auf datacam werden die vielen Vorteile von Mistral Vibe beschrieben.
„Mistral Vibe 2.0 ist ein Terminal-basierter KI-Codierungsagent, der direkt über die Befehlszeile läuft. Anstatt in einem Browser oder als IDE-Plugin zu laufen, arbeitet es direkt im Entwickler-Workflow mit Zugriff auf Dateien und Repositorys.“
Es ist spannend zu sehen, wie sich Mistral, als europäische Alternative zu den bekannten KI-Anwendungen der etablierten amerikanischen Konzerne auf dem Markt behauptet. Erstaunlich ist allerdings auch, dass darüber gar nicht so viel geschrieben wird. Honi soit qui mal y pense.