Wenn es um Open Source Software geht (OSS) geht, muss natürlich auch über die anfallenden Kosten gesprochen werden. Dazu zählen beispielsweise Installations- und Supportkosten, Anforderungen an die Lizenzkonformität und um potenzielle Sicherheitslücken. Neben den anfallenden Kosten stellt sich natürlich auch die Frage, wie es mit dem Nutzen von Open Source Software aussieht. In einer Studie von Henry Chesbrough aus dem Jahr 2023 konnte nachgewiesen werden, dass der Nutzen diese Kosten deutlich übersteigt.
„However, the results of this survey are quite consistent with earlier survey research (Nagle, 2019; European Commission, 2021), which shows that the perceived benefits of utilizing OSS significantly exceed these costs for the large majority of organizations that use OSS“ (Chesbrough, H. (2023), Measuring the Economic Value of Open Source: A Survey and a Preliminary Analysi, The Linux Foundation | PDF).
Die wirtschaftlichen Vorteile gehen einher mit einer stärkeren Unabhängigkeit (Digitale Souveränität) und damit verbunden mit einer besseren Widerstandsfähigkeit (Resilienz) der Organisation.
Die in der Zwischenzeit eingetretene Unmündigkeit (Digitale Abhängigkeit) von US amerikanischen digitalen Angeboten, hat einzelne Personen, Organisationen und ganze Öffentliche Verwaltungen in eine Pfadabhängigkeit geführt, aus der viele einfach nicht mehr herauskommen. Denn es ist ja so bequem, unmündig zu sein.
Immanuel Kant schrieb schon 1784 in seiner Streitschrift: „Beantwortung der Frage: Was ist Aufklärung?“: „Unmündigkeit ist das Unvermögen, sich seines Verstandes ohne Leitung eines anderen zu bedienen. Faulheit und Feigheit sind die Ursachen, warum ein so großer Teil erwachsener Menschen, nachdem sie die Natur längst von fremder Leitung freigesprochen hat, dennoch gerne zeitlebens unmündig bleiben, und warum es anderen so leicht wird, sich zu deren Vormündern aufzuwerfen. Es ist so bequem, unmündig zu sein!“ (Fuchs, J.; Stolorz, C. (2001): Produktionsfaktor Intelligenz. Wiesbaden).
Die Zeit ist reif, sich auf seinen eigenen Verstand zu besinnen, und sich von den aufgebauten digitalen Abhängigkeiten zu lösen. Ganz im Sinne des Wahlspruchs der Aufklärung: „Habe Mut, Dich Deines eigenen Verstandes zu bedienen!“
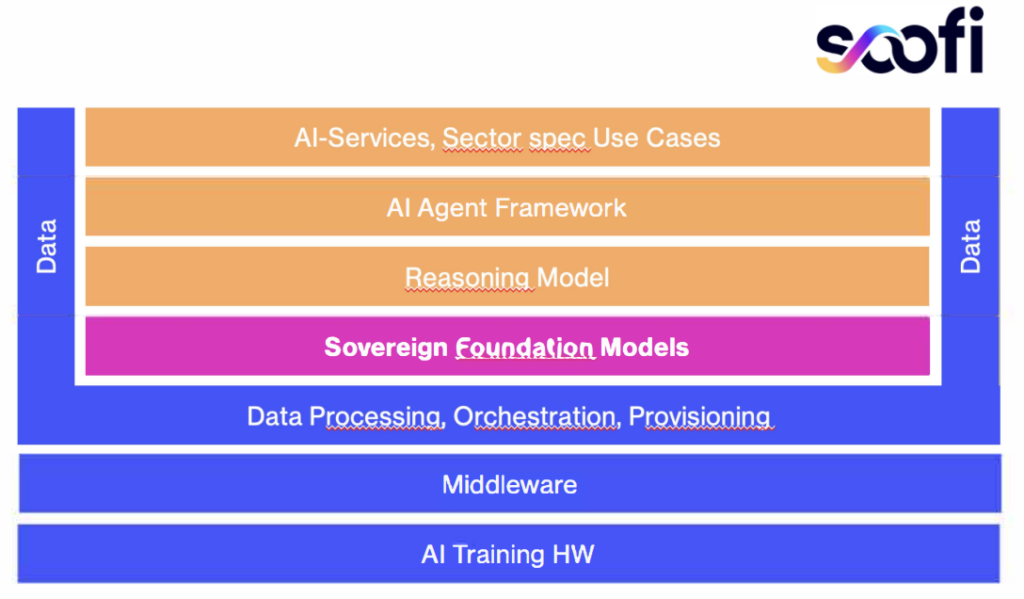
Siehe dazu auch Die erfolgreiche Geschichte von Open Source KI zeigt, wie dieser Weg aussehen kann. Digitale Souveränität: Europa, USA und China im Vergleich.