Der Begriff “Wissen” hat sich n der Vergangenheit immer wieder verändert, und wird dies auch in Zukunft tun. In dem Beitrag Vom Wissen als Besitz zum Wissen als Prozess wird diese Transformation deutlich. Zusammen mit den neuen Technologien, wie das WWW oder auch Künstliche Intelligenz, entsteht ein neuer Wissensbegriff.
„Wissen begründet sich in der gegenwärtigen Gesellschaft in dem Zusammenspiel vieler Wissensfragmente, die unter anderem im world wide web (www) technisch zusammengeführt werden und dort als gemeinsam verfügbares Wissen auftauchen, das durch Prozesse der Wissensbegründung in einer Erfahrungsgemeinschaft konstituiert wird. Dieser Wissensbegriff ist neu“ (vgl. Neusser 2013, zitiert in Arnold 2017:88).
Diese Entwicklung wirft zugleich Fragen zum Umgang mit diesem neuen Wissensbegriff auf. Welche Herausforderungen ergeben sich daraus für ein modernes Wissensmanagement?
In der Vergangenheit wurden z.B. im Projektmanagement nach und nach immer mehr digitale Tools verwendet. Zunächst waren das Anwendungen aus dem Office-Paket, dann kam Microsoft Project hinzu und in der Zwischenzeit gibt es von Microsoft eine integrierte Kollaborationsplattform (Sharepoint, Microsoft Project Online, Teams, Office Apps etc.), die das Arbeiten in Projekten effektiver/produktiver macht. Der nächste Booster wird Künstliche Intelligenz (KI) sein, die über OpenAI als KI-Assistent Projektmanagement-Prozesse unterstützen wird. Andere Tech-Größen wie Google, Facebook und Apple werden diesem Beispiel folgen. Der Vorteil des von Microsoft etablierten IT-Ökosystems ist, dass sich Mitarbeiter, Teams, Organisationen – ja sogar ganze staatliche Verwaltungsstrukturen – an die Logik von Microsoft angepasst haben. Ob das gut ist, kann allerdings infrage gestellt werden. Siehe dazu Warum geschlossene Softwaresysteme auf Dauer viel Zeit und viel Geld kosten.
Dieser Lock-in führt zu einer Pfadabhängigkeit und macht es für Alternativen schwer – Alternativen wie z.B. Open Source Anwendungen. Denn obwohl berechtigte Gründe gegen ein kommerzielles IT-Ökosystem sprechen, bleiben viele Organisationen bei den etablierten IT-Strukturen, da diese Organisationen die Kosten für einen Wechsel (Switching Costs) scheuen. Es wird in Zukunft somit um die Frage gehen, was teurer ist: Das Festhalten an etablierten IT-Strukturen oder ein Wechsel zu Open Source Anwendungen, die einen Souveränen Arbeitsplatz auf Open Source Basis garantieren. Dazu zählt auch, die Verwaltung und die Nutzen der eigenen Daten auf den eigenen Servern, denn Daten sind das neue Öl. Siehe dazu auch Was wäre wenn jeder über seine Daten selbst entscheiden könnte?
Solche Zusammenhänge thematisieren wir auch in den von uns entwickelten Blended Learning Lehrgängen Projektmanager/in (IHK) und Projektmanager/in AGIL (IHK). Informationen dazu, und zu aktuellen Terminen, finden Sie auf unserer Lernplattform.
Viele Einzelpersonen, Unternehmen, NGO und Öffentliche Verwaltungen haben sich an die Nutzung von allseits bekannter Software gewöhnt. Ob es ERP-Systeme für die technische und kaufmännische Abwicklung von Geschäftsprozessen sind, Webkonferenztools, Kollaborationssoftware usw. – für alles gibt es Anwendungen (Apps) der Marktführer Microsoft, SAP, Apple usw. usw. Die Anwendungen werden oft auch als eigenes Software-Ökosystem beschrieben, bei dem Personen oder Organisationen eben drinnen oder draußen sind – was die Sache schon etwas verkompliziert, wenn nicht sogar auf Dauer unwirtschaftlich macht. Warum könnte das so sein? Dazu habe ich einen Beitrag vom November 2023 gefunden, der das thematisiert und aus dem ich folgendes zitieren möchte:
“In Deutschland haben sich sowohl der Mittelstand als auch viele Großunternehmen an geschlossene Softwaresysteme gebunden, die sie nur in dem Maße gestalten können, wie es die Hersteller der betreffenden Systeme zulassen. Wer als Automobilhersteller beispielsweise auf Apple Carplay setzt, kann neue Features nur dann liefern, wenn Apple das ermöglicht. Das gleiche gilt für Maschinenbauer, die zur Analyse der beim Betrieb ihrer Maschinen anfallenden Daten auf proprietäre Cloud-Lösungen setzen: Es geht dann nicht primär darum, was vorteilhaft wäre, sondern darum, was das System anbietet” (Ganten/Doenheim/Schröter 2023).
Diese einseitige digitale Abhängigkeit ist genau so gefährlich, wie es die Energieabhängigkeit von Russland (Gas) war, und von den Arabischen Staaten (ÖL) noch ist. Wenn Daten das neue Öl sind, so muss Deutschland, bzw. die Europäische Union auf eine Souveränität bei den Daten bestehen, die in der EU generiert werden. Diese Daten können aus meiner Sicht nur mit Hilfe von Open Source Anwendungen (statt geschlossene Anwendungen) geschützt und transparent behandelt werden. Darüber hinaus fördern Open Source Anwendungen den vielfältigen Austausch und somit den Mode 2 in der Wissensproduktion, was wiederum zu mehr Innovation und Agilität führt.
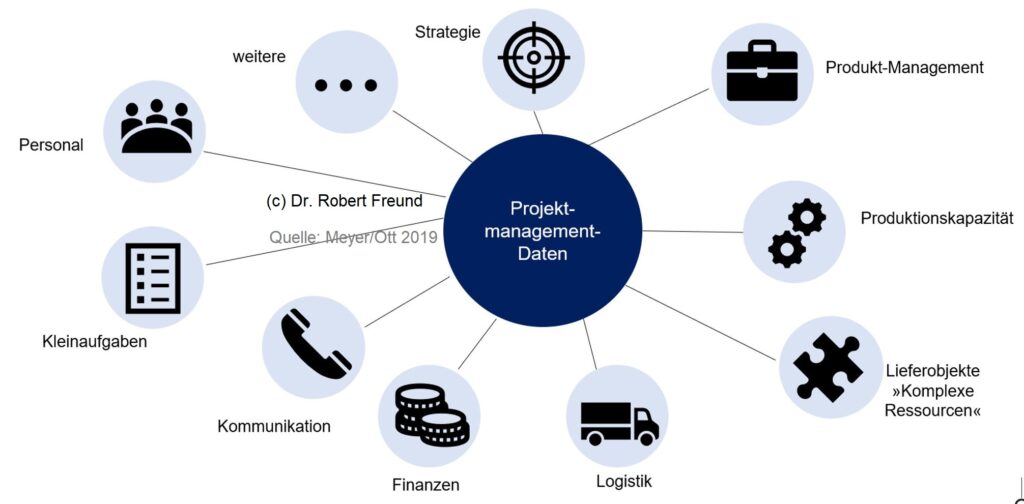
Im klassischen/plangetriebenen Projektmanagement werden an vielen Stellen Daten generiert und benötigt. Es ist daher gut, sich klar zu machen, dass diese Daten in einem recht komplexen Netzwerk mit anderen Systemen verbunden sind.
Im Bereich “Personal” geht es natürlich um die Frage, welche Personalkapazitäten werden für das Projekt benötigt, und welche Kapazitäten stehen aus den Abteilungen zur Verfügung. Ein Ressourcenpool kann hier über viele Arbeitspakete, bzw. über viele Projekte im Multiprojektmanagement helfen, die Übersicht zu behalten. Im Bereich “Finanzen” werden beispielsweise Daten zu Stunden- und Tagessätzen, bzw. Verrechnungssätzen für die Kalkulation der Kosten benötigt. Auch die Liquiditätsplanung für ein Projekte oder auch viele Projekte basiert auf den Projektmanagement-Daten. Weiterhin kann es Sinn machen den Ablauf eines Projekts mit der Logistik abzustimmen. Grundsätzlich sind die Projektmanagement-Daten natürlich auch für das Informations-, Kommunikations- und Berichtswesen (IKBD), sowie für die Dokumentation wichtig.
Das sind nur wenige Beispiele, doch deutet es sich hier schon an, dass eine Software zu Projektmanagement nicht ausreicht, alle Anforderungen an ein professionelles Datenmanagement zu erfüllen. Besser ist es, eine Kollaborationsplattform zu etablieren, in der verschiedene Apps (inkl. Projektmanagement-Apps) zu einem Gesamtsystem integriert sind, und bei dem Sie die Datenhoheit (Datenschutz) in Ihrem Unternehmen behalten. Siehe dazu auch Von der Projektmanagement-Software zur Kollaborationsplattform.
Solche Zusammenhänge thematisieren wir auch in den von uns entwickelten Blended Learning Lehrgängen, Projektmanager/in (IHK) und Projektmanager/in Agil (IHK), die wir an verschiedenen Standorten anbieten. Weitere Informationen zu den Lehrgängen und zu Terminen finden Sie auf unserer Lernplattform.
Ja, es gibt ChatGPT von OpenAI, Bard von Google usw. usw. und ich muss sagen, dass die Ergebnisse z.B. von ChatGPT schon beeindruckend sind. Warum sollte man sich dennoch mit Alternatiuven befassen? Es ist relativ einfach, denn manche Unternehmen verbieten den Einsatz von diesen Systemen. Den Grund liefert die Google-Mutter Alphabet selbst: Bard: Google warnt Mitarbeiter vor der Nutzung des eigenen Chatbots. Hier ein Auszug:
Ausgerechnet die Google-Mutter Alphabet warnt seine Mitarbeiter vor der Nutzung generativer KI – inklusive des hauseigenen Chatbots Bard. Speziell Ingenieure sollten weder Code zur Fehleranalyse in trainierten Sprachmodelle eingeben, noch die ausgegebenen Zeilen nutzen. In einem am 1. Juni aktualisierten Datenschutzhinweis von Google heißt es Reuters zufolge: “Fügen Sie keine vertraulichen oder sensiblen Informationen in Ihre Bard-Konversationen ein”. (ebd.)
Die Entwicklungen von NEXTCLOUD könnten in diesem Zusammenhang interessant werden, da es auf Open-Source-Basis die in KI-Anwednungen generieten Daten in ihrer eigenen geschützten Cloud behält. Wie kann man sich das vorstellen? Wie Sie wissen, haben wir Nextcloud als Open-Source-Anwendung für Cloudanwendungen auf unseren Servern installiert. Dabei war bisher der Schwerpunkt auf der Weiterentwicklung zu einer integrierten Kollaborationsplattform auf Open-Source-Basis.
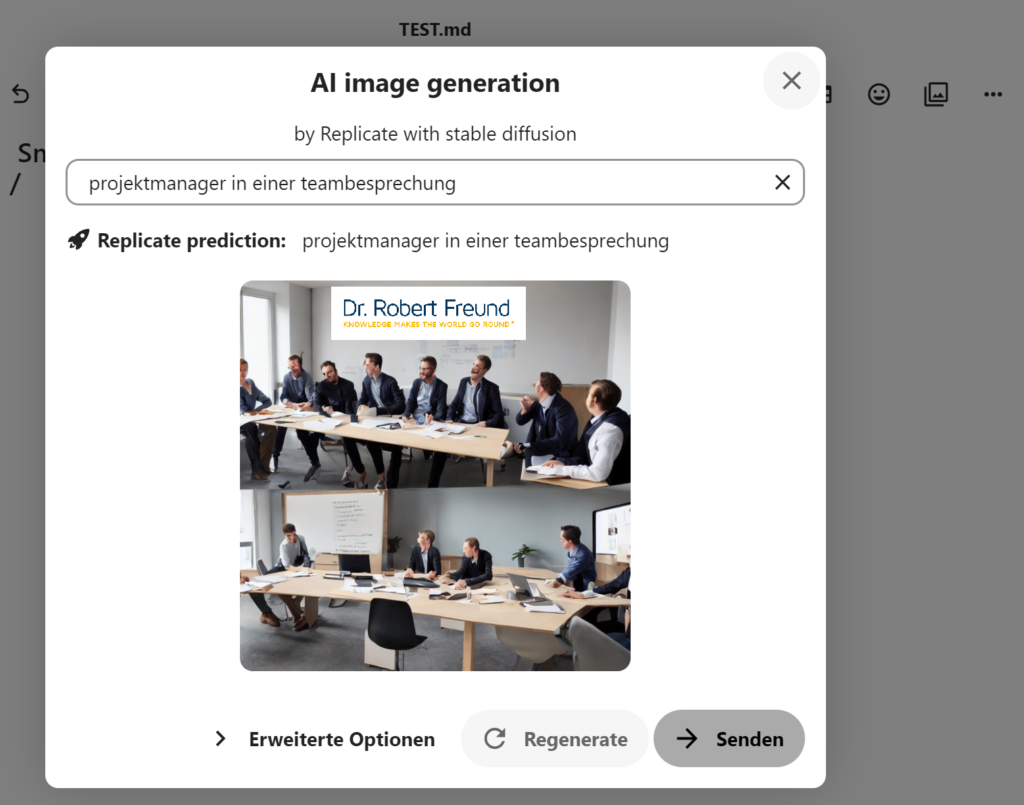
Seit Nextcloud Hub 4 gibt es die Möglichkeit, Apps zur Künstlicher Intelligenz (KI; AI: Articicial Intelligence) in Dateien aufzurufen. In dem Beispiel (Screenshot) haben wir eine Textdatei (TEXT.md) geöffnet, und mit dem Smart Picker (“/”) verschiedene KI-Anwendungen geöffnet. Eine davon basiert auf Stabe Diffusion und kann Bilder auf Basis einer Eingabe (Prompt) generieren. Beispielhaft haben wir in der vorgesehenen Zeile “Projektmanager in einer Teambesprechung” eingegeben. Das Ergebnis sehen Sie in dem Screenshot. Die generierten Daten und die Prompts bleiben alle auf unseren Servern. In einem der nächsten Blogbeiträge, werde ich eine weitere KI-Anwendung innerhalt von NEXTCLOUD vorstelen.
Ziel von Nextcloud ist es, in Zukunft immer mehr AI-Anwendungen integriert anzubieten, wobei die AI-Apps auch ethisch eingeordnet werden sollen. Basis dafür ist eine Ampelfunktion. Siehe dazu Nextcloud Hub 4 mit “ethical AI” Integration – Open Source.
Wir werden in der nächsten Zeit immer mehr AI-Apps in Nextcloud in Bezug zu unseren Themen wie z.B. Projektmanagement ausprobieren, und so wichtige Erfahrungen sammeln.
Solche Zusammenhänge thematisieren wir auch in den von uns entwickelten Blended Learning Lehrgängen, Projektmanager/in (IHK) und Projektmanager/in Agil (IHK), die wir an verschiedenen Standorten anbieten. Weitere Informationen zu den Lehrgängen und zu Terminen finden Sie auf unserer Lernplattform.
Öl ,als Treiber für die wirtschaftlichen und gesellschaftlichen Entwicklungen der letzten 150 Jahre, gehörte und gehört einigen wenigen Ländern, bzw. Konzernen. Diese Konzerne stellen uns das Öl recht kostspielig zur Verfügung – wir zahlen dafür.
Öl wird als Treiber nun immer mehr durch Daten ersetzt. Daten sind das neue Öl. Diese Kurzfassung hat ihren Ursprung in einem Artikel des Economist aus dem Jahr: The world’s most valuable resource is no longer oil, but data. Auch diese Quelle für wirtschaftliche und gesellschaftliche Entwicklungen wird hauptsächlich von großen Konzernen verwendet. Wir dürfen die verschiedenen Tools “kostenlos” nutzen, und zahlen mit unseren Daten. Nun gibt es nicht nur die wirtschaftlich generierten Daten sondern auch die, die bei Verwaltungen hinterlegt sind. Auch diese Daten werden teilweise im Sinne von Open Data zur Nutzung freigegeben.
Jeder generiert also immer und überall Daten, die mit einem persönlichen Schutz versehen, nur denjenigen zur Verfügung gestellt werden könnten, denen die jeweilige Person das Recht dazu einräumt – beispielsweise über eine private Blockchain. Zur freien Nutzung oder gegen Gebühr. Jeder könnte die Nutzung der selbst generierten Daten also verkaufen und dadurch selbst Einnahmen generieren. An manchen Stellen sind wir schon ein stückweit auf diesem Weg, doch dominiert aktuell noch bei weitem nicht die Selbstbestimmung des einzelnen Bürgers, sondern das Primat der relativ freien Nutzung unserer Daten durch Wirtschaftsunternehmen.
Was wäre also, wenn jeder Bürger über seine generierten Daten selbst entscheiden könnte?
In einer aktuellen Studie von Researchscape im Auftrag von Lucid Software wurden 2.196 Wissensarbeiter aus den USA, aus UK, den Niederlanden, Deutschland und Australien befragt. Dabei kamen doch recht überraschende Ergebnisse heraus, die in der englischsprachigen Website von Lucid Software zu finden sind. ZDNET hat die wichtigsten Erkenntnisse in einem deutschsprachigen Artikel zusammengefasst.
“Demnach wenden deutsche Wissensarbeiter im Schnitt etwa 6,5 Stunden für die Suche nach Informationen auf, bevor sie mit der eigentlichen Arbeit beginnen können – was fast einem ganzen Arbeitstag pro Woche entspricht. Zudem erschwert eine schlechte Koordination im Team die produktive Arbeit” (Quelle: ZDNET vom 01.06.2023).
Qualitativ gute Daten und Informationen sind für die Wissensarbeit elementar. Insofern ist es wichtig, diese Basis mit Hilfe digitaler Strukturen aufzubauen und die Koordination im Team zu verbessern. Technologisch kann das durch Kollaborationsplattformen geschehen, die auch eine stärkere Selbstorganisation unterstützen sollte. Kollaborationsplattformen unterscheiden sich dadurch auch von Software. Siehe dazu auch Von der Projektmanagement-Software zur Kollaborationsplattform.
Solche Zusammenhänge thematisieren wir auch in den von uns entwickelten Blended Learning Lehrgängen, die wir an verschiedenen Standorten anbieten. Weitere Informationen zu den Lehrgängen und zu Terminen finden Sie auf unserer Lernplattform.
Unsere westliche Sicht auf Wissen wird von einem eher technisch-wissenschaftlichen Modell dominiert: “the hegemony of the techno-scientific model in defining legitimate and productive knowledge” (UNESO 2005: 5). Es wundert daher nicht, dass versucht wird, verschiedene Begriffe zu unterscheiden – zu definieren. Es geht ganz praktisch um die Unterscheidung der Begriffe “Zeichen”, “Daten”, “Informationen” und “Wissen”, die in der ursprünglichen, bzw. in der erweiterten Wissenstreppe dargestellt werden. Siehe dazu auch Ein besseres Verständnis der Wissenstreppe führt zu einem besseren Umgang mit Wissen. Auf der Ebene der “Daten” gibt es allerdings mit dem Begriff “Fakten” ein weiters Konstrukt. Dazu habe ich folgendes gefunden:
“Aufschlussreicher sollte es sein, zwischen Daten und Fakten terminologisch zu unterscheiden. ‚Daten‘ sind das, was einem Beobachter buchstäblich gegeben ist (lat.: datum / frz.: donnée) und daher insbesondere das, was sich in irgendeiner Weise feststellen und vielleicht sogar messen lässt. In erster Linie darf man also das als Datum verstehen, was niemand bestreiten kann, und mithin gilt ein Datum fraglos, sofern es korrekt ermittelt worden ist. Ein Faktum ist demgegenüber kein simples Datum, sondern wortwörtlich eine ‚Tat-Sache‘, das heißt ein im Kern menschliches Produkt. Wo wir von Fakten reden, sprechen wir jedenfalls immer von Dingen, die wir selber erst zu dem gemacht haben, was sie sind (lat.: factum / frz.: fait). Können Daten insofern nicht anders als ‚richtig‘ sein, solange man sie nicht irrtümlich oder sachwidrig erfasst hat, stellt sich bei Fakten von vornherein die Frage, inwiefern sie als ‚wahr‘ gelten dürfen” Meier, A. (2020): In Science We Trust: Überlegungen zum Wissen der Wissenschaften. In: Horatschek, A. M. (Hrsg.) (2020): Competing Knowledges – Wissen im Widerstreit. Abhandlungen der Akademie der Wissenschaften in Hamburg, Band 9).
Wenn also oftmals hervorgehoben wird, “das ist Fakt” oder “Fakt ist”, so ist diese Formulierung kritisch zu sehen, denn sie ist nicht so unumstößlich, wie es auf den ersten Blick den Anschein hat. Wie in der Quelle erwähnt, stellt sich bei “Fakten” die Frage, “inwiefern sie als ‚wahr‘ gelten dürfen”.
Dass wir uns mit Daten und Informationen im Projektmanagement befassen ist allgemein üblich. Wir nutzen dazu verschiedene Kollaborationsplattformen, die gerade für explizites Wissen gut geeignet sind. Was ist mit dem impliziten Wissen? Wie gehen wir damit um? Wissensmanagement hat schon seit vielen Jahren Konjunktur, was schon der folgende Beitrag aus dem Jahr 2004 zeigt.
“Wissensmanagement in Organisationen hat Konjunktur. Davon profitiert auch die Disziplin ´Projektmanagement´. Der Erfahrungssicherung in Projekten stellen sich dabei spezifische Hürden in den Weg, insbesondere das Faktum, dass das ausführende Team nach Beendigung des Projekts in aller Regel aufgelöst wird. Trotz der zahllosen Publikationen und theoretischen Konzepte, die sich mit Lernen aus Projekten befassen, dürfte ihre praktische Nutzung noch nicht allzu weit fortgeschritten sein. Vor allem das Lernen aus wenig erfolgreichen Projekten stößt auf erhebliche Widerstände” (Schelle 2004).
Bemerkenswert ist dabei auch der Hinweis im letzten Satz, dass Lernen aus wenig erfolgreichen Projekten schon damals auf erhebliche Widerstände gestoßen ist. Lernen ist der Prozess und Wissen das Ergebnis (Willke). Es ist erforderlich, sich zunächst einmal mit dem Begriff “Wissen” auseinanderzusetzen um ihn auch von Daten, Informationen, Kompetenz usw. abzugrenzen. Erst wenn verstanden ist, was unter “Wissen” zu verstehen ist, kann der Umgang mit Wissen (Wissensmanagement) thematisiert und sinnvoll in Projekten, im Projektmanagement und in der gesamten Organisation gestaltet werden. In unserem Blog finden Sie dazu mehr als 1.000 Beiträge.
In den von uns entwickelten Blended Learning Lehrgängen Projektmanager/in (IHK) und Projektmanager/in AGIL (IHK) gehen wir auf diese Zusammenhänge ein. Informationen zu den Lehrgängen und zu Terminen finden Sie auf unserer Lernplattform.
Die einfache Wissenstreppe nach North unterscheidet Daten, Informationen und Wissen in einem Stufenmodell. Die erweiterte Wissenstreppe ergänzt diese Stufen noch mit Kompetenz, bei der diese Stufen von unten nach oben, und von oben nach unten “gegangen” werden können. North und Maier (2018) erweiterten ihr Modell später zu einer Art Wissenstreppe 4.0, die sich an der Unterscheidung von Arbeit 1.0 bis 4.0 orientiert und eher ambidexter (“beidhändig”) ist. Im angelsächsischen Raum wird die Wissenstreppe mit den Abkürzungen DIKW-Pyramide beschrieben (Data – Information – Knowledge – Wisdom).
Prof. Dr.-Ing Peter Heisig hat 2022 in einem Kommentar bei LinkedIn folgendes dazu erwähnt: “Well, I always suggest my students to read the paper by Ilkka Tuomi (1999) ´Data is more than knowledge: Implications of the Reversed Knowledge Hierarchy for Knowledge Management and Organizational Memory´ which provides a very good discussion of the D-I-K hierarchy suggesting a different approach. Also Martin Fricke points out logical errors if the DIKW hierarchy in his paper (2009) „The knowledge pyramid: a critique of the DIKW hierarchy“. Finally, for the German reading colleagues, Derboven, Dick & Wehner (1999) present a very interesting approach from a work psychology perspective. Would be useful to consider the research already undertaken in our domain (Heisig 2022).
Es kann durchaus Sinn machen, sich am Anfang mit Hilfe der Wissenstreppe in das Themenfeld einzulesen. Die erwähnten kritischen Anmerkungen führen dann zu einem immer besseren Verständnis des Konstrukts “Wissen”, was letztendlich auch zu einem besseren Umgang mit Wissen in den Organisationen führt (Wissensmanagement).
Diese Website benutzt Cookies. Wenn du die Website weiter nutzt, gehen wir von deinem Einverständnis aus.OK