Immer mehr Menschen nutzen Künstliche Intelligenz, um gesundheitliche, psychologische oder berufliche Themen zu analysieren. Der Ratgeber ist in diesen Fällen also nicht der Arzt, der Psychologe, oder ein Kollege am Arbeitsplatz, sondern ChatGPT oder andere bekannte KI-Modelle.
Es ist in dem Zusammenhang wichtig, welche Werte von dem KI-Modell „vertreten“ werden. Warum? In dem Beitrag Digitale Souveränität: Europa, USA und China im Vergleich wird deutlich, wie unterschiedlich die Werte von KI-Modellen der US-amerikanischen Tech-Konzerne, chinesischen Modellen, und europäischen Modellen sein können.
Da wiederum Werte Ordner sozialer Komplexität sind, ermöglichen sie ein Handeln unter Unsicherheit und bestimmen die menschliche Selbstorganisation.
Systemische Sicht auf Werte: „Werte können als Ordnungsparameter (Ordner) selbstorganisierter komplexer biotischer, individueller, gruppenförmiger oder aggregierterer sozialhistorischer Systeme aufgefasst werden. Diese Ordner bestimmen oder beeinflussen zumindest stark die individuell-psychische und sozial-kooperativ kommunikative menschliche Selbstorganisation und ermöglichen eben damit jenes Handeln unter prinzipieller kognitiver Unsicherheit“ (Haken 1996).
In früheren Beiträgen hatte ich schon darauf hingewiesen, dass der Großteil der Trainingsdaten der bekannten KI-Modelle aus englischsprachigen (chinesischen) Elementen zusammengesetzt sind. Das Open Source AI-Modell für Europa Teuken 7B hat hier angesetzt, und enthält daher mehr als 50% non englisch data.
Es stellt sich dabei natürlich auch die Frage, warum es so wichtig ist, Trainingsdaten in den jeweiligen (europäischen) Sprachen zu haben. Dazu habe ich eine Erläuterung zur ungarischen, bzw. finnischen Sprache gefunden:
„The current landscape is dominated by models pretrained on vast corpora composed predominantly of English and a few other high-resource languages, creating a significant performance and resource disparity for less-resourced linguistic communities (Zhong et al. 2025). For medium-resource languages such as Hungarian, a Finno-Ugric language characterized by its agglutinative nature and rich morphology, this gap is particularly pronounced. Off-the-shelf multilingual models often exhibit suboptimal performance due to insufficient representation in training data and tokenizers that are ill-suited to language specific morphology. This is particularly the case for open-source models, which visibly struggle with Hungarian grammar“ (Cesibi et al. 2026).
Die hier angesprochenen Agglutinierenden Sprachen (Wikipedia) sind gar nicht so selten. Neben der hier angesprochenen ungarischen Sprache, sind das auch Finnisch, Baskisch, Japanisch, Türkisch usw. Schauen Sie sich dazu bitte die angegebene Wikipedia-Seite an, Sie werden überrascht sein.
Für all diese Sprachen macht es also Sinn, spezifische Trainingsdaten in der jeweiligen Sprache, inkl. der jeweiligen Besonderheiten zu entwickeln. In der Zwischenzeit ist dieser Trend auch deutlich zu beobachten, nicht nur bei den Agglutinierenden Sprachen.
Diese speziellen KI-Modelle können gerade für kultur-, sprachen- und kontextbezogene Innovationen geeignet sein. Siehe dazu auch
Immer mehr Menschen nutzen Künstliche Intelligenz, um gesundheitliche oder psychologische Themen zu analysieren. Der Ratgeber ist dann also nicht der Arzt oder der Psychologe, sondern ChatGPT oder andere bekannte KI-Modelle.
Bei der Kommunikation Mensch – KI dringt die KI immer tiefer in das Profil des Menschen ein. Die Profile werden dann auch dazu genutzt, dem Nutzer zu schmeicheln.
Schmeicheln bedeutet „jemandem übertrieben und nicht ganz aufrichtig Angenehmes sagen, um dessen Gunst zu gewinnen“ (Quelle).
In einer Studie (Jain et al. 2026) wurden zwei Schmeicheleien unterschieden: (1) Zustimmungsschmeichelei (agreement sycophancy) – die Tendenz von Modellen, übermäßig positive Reaktionen hervorzurufen, und (2) Perspektivenschmeichelei (perspective sycophancy) – das Ausmaß, in dem Modelle die Sichtweise eines Nutzers widerspiegeln.
Es stellte sich daher die Frage: Verstärkt Personalisierung das Ausmaß der Schmeicheleien?
„Our results raise the question of whether some personalization approaches may amplify sycophancy. Prior work often attributes sycophancy to preference alignment, since users prefer responses that are affirmative or aligned with their perspective. Yet in aligned models, we find that user memory profiles are associated with further increases in agreement sycophancy, and that contexts providing more information about the user drive perspective sycophancy“ Source: Jain et al. (2026): Interaction Context Often Increases Sycophancy in LLM | PDF
Es wurde also in der Studie klar, dass Nutzerprofile eher Zustimmungsschmeicheleien, und Kontextinformationen eher Perspektivenschmeichelei verstärken. Egal welches Element man also betrachtet, Schmeicheleien verstärken sich wohl mit der Zeit.
Bei diesen Entwicklungen stehen wir noch am Anfang, doch deutet sich schon jetzt ein entsprechender Klärungsbedarf an: Wie können Personalisierung und Schmeicheleien ausbalanciert werden? Siehe dazu auch
Auf den verschiedenen Konferenzen, an denen ich teilgenommen habe, ging es über viele Jahre um Mass Customization and Personalization. Auslöser der Entwicklung war die Veröffentlichung B. Joseph Pine II (1992): Mass Customization. The New Frontier in Business Competition, in der die damals neue hybride Wettbewerbsstrategie vorgestellt wurde.
In der Zwischenzeit gibt es beim Fraunhofer Institut in Stuttgart das Leistungszentrum Mass Personalization. Dort ist man der Auffassung, dass es sich bei Mass Personalization um einen Megatrend handelt
„Mass Personalization ist ein eigenständiges radikal nutzerzentriertes und dennoch nachhaltiges und ressourceneffizientes Konzept, das als Toolbox oder plattformtechnologische Anwendung in der Produktion von morgen fungieren kann“ (Krieg/Groß/Bauernhansl (2024) (Hrsg.): Einstieg in die Mass Personalization. Perspektiven für Entscheider).
Mass Customization ist hier zeitpunktbezogen, und Mass Personalization eher Zeitdauer bezogen zu interpretieren. Beides, Mass Customization und Mass Personalization, sind allerdings immer noch aus der Perspektive des Unternehmens gedacht.
Wenn sich ein Unternehmen auf jeden einzelnen Nutzer so intensiv einstellen will, benötigt es viele Problem- und möglicherweise auch erste Lösungsinformationen vom Nutzer. Bei komplexen Problemen sind diese Informationen nur sehr schwer zu beschreiben (Kontext, Implizites Wissen, Expertise), und schwer vom Nutzer zum Unternehmen übertragbar (Sticky Information, Träges Wissen).
Der Nutzer weiß oft am besten, was er für sein Problem benötigt. Es fehlt oft noch der Schritt zur ersten Umsetzung von eigenen Lösungen. Dieser war in der Vergangenheit sehr aufwendig (Zeit, Geld), sodass die Umsetzung oft von Unternehmen übernommen wurde.
In der Zwischenzeit gibt es durch die Möglichkeiten der Künstlichen Intelligenz, des 3D-Drucks (Additive Manufacturing), oder auch der Robotik und der Open Source Community viele Möglichkeiten, das Produkt selbst zu entwickeln und im Idealfall selbst oder in einer Community herzustellen. Siehe Eric von Hippel (2016): Free Innovation (Open Access).
Titel (Ausschnitt) https://direct.mit.edu/books/book/5344/Free-Innovation
Eric von Hippel hat dazu schon sehr viele Studien veröffentlich, aus denen hervorgeht, dass der Anteil dieser Open User Innovation in den letzten Jahrzehnten stark angewachsen ist. Diese Innovationen findet man nicht in den offiziellen Statistiken zu Innovationen, denn Innovationen werden dort von Unternehmen entwickelt und auf den Markt gebracht. Was versteht nun von Hippel unter Open User Innovation?
„An innovation is ´open´ in our terminology when all information related to the innovation is a public good—nonrivalrous and nonexcludable”(Baldwin and von Hippel 2011:1400).
”… involves contributors who share the work of generating a design and also reveal the outputs from their individual and collective design efforts openly for anyone to use“ (Baldwin and von Hippel 2011:1403).
Wir wissen alle, dass die Unternehmen nur die Innovationen auf den Markt bringen, die eine entsprechende Rendite versprechen – alles andere bleibt liegen… Doch genau darin liegt die Chance von Open User Innovation: Jeder einzelne kann nicht nur kreativ, sondern auch innovativ sein (Ideen umsetzen) und seine Innovationen anderen (auch kostenlos) zur Verfügung stellen.
Sie meinen das gibt es nicht? Dann schauen Sie sich einmal die vielen Plattformen zu Open Source Software, oder die Plattform Patient Innovation an – Sie werden staunen.
Wenn Sie sich zu diesen Themen informieren wollen: Die MCP Community of Europe trifft sich auf der Konferenz zu Mass Customization and Personalization – MCP 2026 – vom 16.-19.09.2026 in Balatonfüred, Ungarn. Wir sind dabei.
Weiterhin wurde Open EuroLLM veröffentlicht, ein „Large language Modelmade in Europebuilt to support allofficial 24 EU languages„. Die generierten Modelle sind Multimodal, Open Source, High Performance und eben Multilingual.
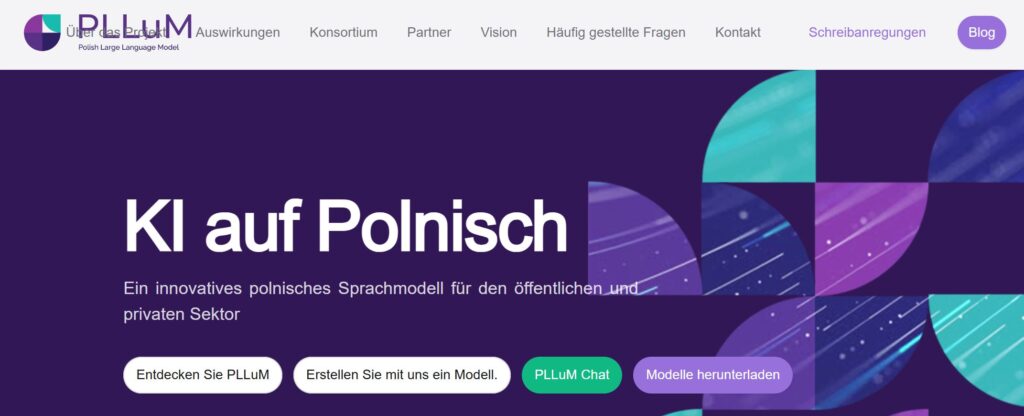
Zusätzlich zur europäischen Ebene gibt es allerdings auch immer mehr spezielle, länderspezifische Large Language Models (LLMs), wie das in 2025 veröffentlichte PLLuM ((Polish Large Language Model). Ich möchte an dieser Stelle drei wichtige Statements wiedergeben, die auf der Website zu finden sind:
Polnische Sprachunterstützung Ein wichtiges Element dieses Projekts ist die Entwicklung eines umfassenden und vielfältigen Datensatzes, der die Komplexität der polnischen Sprache widerspiegelt.
Die polnische Sprachunterstützung geht darauf ein, dass die üblichen proprietären LLM überwiegend in englischer (chinesischer) Sprache trainiert wurden, und dann entsprechende Übersetzungen liefern. Diese sind für den Alltagsgebrauch durchaus nützlich, doch wenn es um die kulturellen, kontextspezifischen Nuancen einer Sprache geht, reichen diese großen KI-Modelle der Tech-Konzerne nicht aus.
Das PLLuM-Modell setzt auf Offenheit, Transparenz und einfache Bedienung. Es versteht sich daher von selbst, dass die Modelle bei Huggingface zur Verfügung stehen und genutzt werden können. Probieren Sie den Chat einfach einmal aus:
Sicherheit und Ethik Wir stellen sicher, dass unser Modell sicher und frei von schädlichen und falschen Inhalten ist, was für seinen Einsatz in der öffentlichen Verwaltung von entscheidender Bedeutung ist.
Nicht zuletzt sind Sicherheit und Ethik wichtige Eckpunkte für das polnische Modell. Es unterscheidet sich dadurch von den bekannten großen KI-Modellen der Tech-Konzerne. Siehe dazu auch Künstliche Intelligenz: Würden Sie aus diesem Glas trinken?
Interessant ist auch, dass auf der PLLuM-Website darauf hingewiesen wird, dass man durch diese KI-Modelle auch Innovationen fördern möchte. Wieder ein direkter Bezug zwischen Open Source AI und Innovationen.
Seit langem geht es um die Frage, ob es möglich ist, Künstliche Intelligenz mit Menschlicher Intelligenz zu vergleichen. In der Zwischenzeit mehren sich dazu die Meinungen, dass dieser Vergleich ein Kategorienfehler sein kann. Siehe dazu beispielhaft Künstliche Cleverness statt Künstliche Intelligenz?
Auch Walter Quattrociocchi, Full Professor of Computer Science at Sapienza University, hat in verschiedenen psychologischen Tests Unterschiede zwischen Künstlicher Intelligenz und Menschlicher Intelligenz herausgefunden.
Quattrociocchi, W. (2026): What we risk when we confuse AI and human intelligence. Putting humans and LLMs head-to-head in classic tests of judgment from human psychology underscores the differences between them. Scientific American, 18.02.2026.
Zunächst beschreibt Quattrociocchi die Ausbildung von Ärzten, die über Jahre nicht nur lesen, sondern auch mit und an menschlichen Körpern arbeiten, Diagnosen stellen und Behandlungen durchführen. Wenn man das mit den Antworten der Künstlichen Intelligenz (genauer: Antworten auf Basis der Large Language Models) vergleicht, wird deutlich, dass etwas Wesentliches fehlt.
„Across all the tasks we have studied, a consistent pattern emerges. Large language models can often match human responses but for reasons that bear no resemblance to human reasoning. Where a human judges, a model correlates. Where a human evaluates, a model predicts. When a human engages with the world, a model engages with a distribution of words. Their architecture makes them extraordinarily good at reproducing patterns found in text. It does not give them access to the world those words refer to“ (ebd.).
Der Autor weist auf die Stärken von KI-Modellen hin, die er „linguistic automation“ nennt. Weiterhin wird im Artikel auch hervorgehoben, dass den KI-Modellen ein wichtiges Element fehlt: die Verbindung zur realen Welt. Siehe dazu auch Rent a Human: KI-Agenten bieten Arbeit für Menschen an.
Keiner will Chaos! Es geht um Kontrolle über Abläufe, die Umwelt, das eigene Leben usw. Doch lernen wir langsam (sehr langsam), dass das Leben mit seiner Entwicklung in den letzten Milliarden von Jahren immer wieder überraschende Sprünge gemacht hat. Siehe dazu auch Die Selbstorganisation des Universums.
Solche Bifurkationspunkte in komplexen Systemen (siehe Synergetik nach Haken) haben in Summe eben auch dazu geführt, dass es uns Menschen gibt. Es scheint so zu sein, als ob es in manchen Situationen gut ist, wenn etwas regelmäßig passiert, in anderen Situationen eben nicht. Das kann man sich am eigenen Körper gut klarmachen:
„Es ist wohlbekannt, dass das Herz im Prinzip regelmäßig schlagen muss, weil wir sonst stürben. Das Hirn aber muss im Prinzip unregelmäßig arbeiten, sonst würden wir epileptisch. Dies zeigt, dass Unregelmäßigkeit, Chaos, zu komplexen Systemen führt. Das bedeutet nicht etwa Unordnung, im Gegenteil, ich würde sagen, gerade das Chaos macht das Leben und die Intelligenz möglich“ (Prigogine, zitiert in Briggs, J.; Peat, F. D. (1999): Die Entdeckung des Chaos. Eine Reise durch die Chaos-Theorie).
Wenn Chaos allerdings Leben und die Intelligenz möglich macht, dann ist Chaos eben nicht nur negativ, sondern auch positiv zu sehen. Das entspricht leider nicht der umgangssprachigen Interpretation des Wortes Chaos, das fast immer dann gebraucht wird, um etwas negativ darzustellen. Wir tun gut daran, diese Interpretation zu ändern, denn immerhin sind wir als Menschen aus einem Chaos entstanden.
Wenn wir heute über Medien sprechen oder schreiben, geht es meistens um Digitale Medien. Der althergebrachte Gedanke, dass Digitale Medien eher neutral sind, und nur Botschaften übermitteln, ist heute nicht mehr zeitgemäß. Denn ganz nach McLuhan (1968) ist das Medium die Botschaft. Was heißt das?
„Für eine medienwissenschaftliche Betrachtung Digitaler Medien ist der von dem kanadischen Medienwissenschaftler Marshall McLuhan formulierte Medienbegriff relevant, wie er in dem häufig zitierten Satz „the medium is the message“ (McLuhan 1968:15) zum Ausdruck kommt. Die Botschaft eines Mediums ist nach McLuhan die „Veränderung des Maßstabs, Tempos, Schemas, die es der Situation der Menschen bringt“ (ebd.: 22). Das heißt, dass Medien unabhängig vom transportierten Inhalt neue Maßstäbe setzen (ebd.: 21). Digitale Medien setzen im Bereich der Informations-, Kommunikations-, Arbeits- und Lernmöglichkeiten neue Maßstäbe. Der McLuhan’sche Medienbegriff steht im Kontrast zu einem Medienverständnis, wonach Medien neutral sind und lediglich als Übermittler von Botschaften dienen“.
Quelle: Carstensen, T. Schachtner, C.; Schelhowe, H.; Beer, R. (2014): Subjektkonstruktion im Kontext Digitaler Medien. In: Carstensen, T. (Hrsg.) (2014): Digitale Subjekte. Praktiken der Subjektivierung im Medienumbruch der Gegenwart.
Gerade in Zeiten Künstlicher Intelligenz geht es daher nicht alleine um den Content, sondern auch darum, dass KI-Modelle neue Maßstäbe setzen. Gerade dieser Effekt von KI ist bei Verlagen, in der Musikbranche, bei Psychologen, Ärzten, usw. deutlich zu erkennen. Dabei ist auch der Hinweis von McLuhan wichtig, dass dadurch auch die Neutralität dieser Digitalen Medien verlorengeht.
KI-Modellen, mit den darin enthaltenen Ansichten zum Menschenbild,, zur Gesellschaftsformen usw., werden zu starken Beeinflusser von Individuen, die erst durch „das Gegenüber“ und durch Kontexte zu einem „Ich“ wird.
„Wer bin ich ohne die anderen? Niemand. Es gibt mich nur so, in einem Zusammenhang mit Menschen, Orten und Landschaften“ (Marica Bodroži 2012:81).
Conceptual technology illustration of artificial intelligence. Abstract futuristic background
Für komplexe Problemlösungen ist es wichtig, implizites Wissen zu erschließen. Wenig überraschend stellt Polanyi daher die Meister-Lehrling-Beziehung, in der sich Lernen als Enkulturationsprozess vollzieht, als essentielles Lern-Lern-Arrangement heraus:
„Alle Kunstfertigkeiten werden durch intelligentes Imitieren der Art und Weise gelernt, in der sie von anderen Personen praktiziert werden, in die der Lernende sein Vertrauen setzt“ (PK, S. 206). (Neuweg 2004).
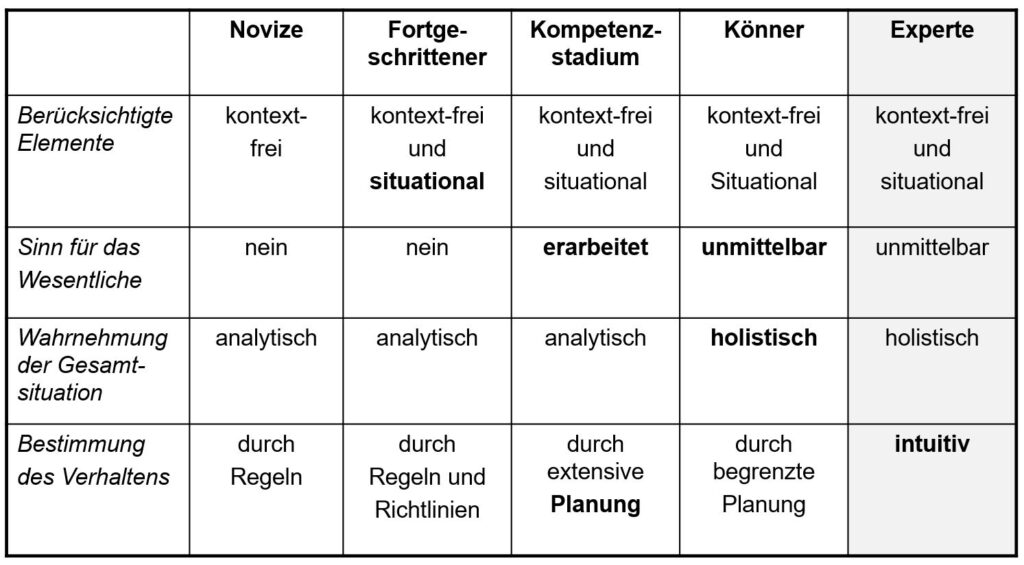
Das setzt auch die Anerkenntnis der Autorität des Experten voraus. Nach Dryfus/Dryfus ergeben sich vom Novizen bis zum Experten folgende Stufen der Kompetenzentwicklung:
Das Modell des Fertigkeitserwerbs nach Dreyfus/Dreyfus (Neuweg 2004)
Wenn wir uns nun die Beziehung zwischen Künstlicher Intelligenz und dem (nutzenden) Menschen ansehen, so kann diese Beziehung oftmals wie eine Meister-Lehrling-Beziehung beschrieben werden.
Dabei ist die „allwissende“ Künstliche Intelligenz (z.B. in Form von ChatGPT etc.) der antwortende Meister, der die Fragen (Prompts) des Lehrlings (Mensch) beantwortet. Gleichzeitig wird vom Lehrling (Mensch) die Autorität des Meisters (ChatGPT) anerkannt. Dieser Aspekt kann dann allerdings auch für Manipulationen durch die Künstliche Intelligenz genutzt werden.
Ein weiterer von Polanyi angesprochene Punkt ist das erforderliche Vertrauen auf der Seite des Lernenden in den Meister. Kann ein Mensch als Nutzer von Künstlicher Intelligenz Vertrauen in die KI-Systeme haben? Siehe dazu Künstliche Intelligenz – It All Starts with Trust.
Gerade wenn es um komplexe Probleme geht hat das Lernen von einer Person, gegenüber dem Lernen von einer Künstlichen Intelligenz, Vorteile. Die Begrenztheit von KI-Agenten wird beispielhaft auf der Plattform Rent a Human deutlich, wo: KI-Agenten Arbeit für Menschen anbieten, denn
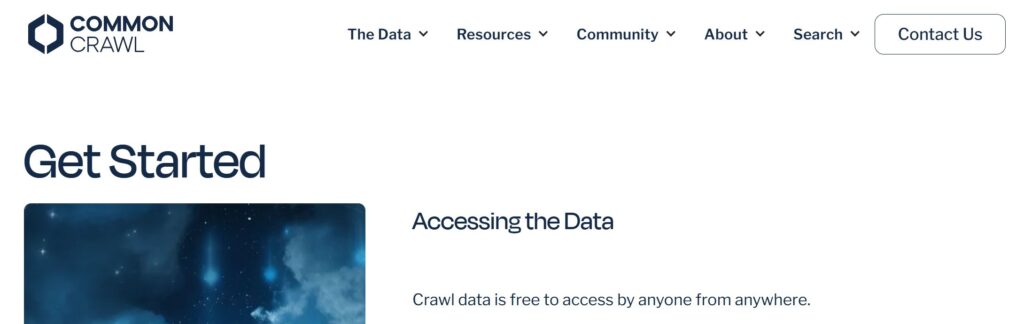
Large Language Models (LLMs) benötigen eine Unmenge an Daten. Bei den Closed Source KI-Modellen von OpenAI, Meta, etc. ist manchmal nicht so klar (Black Box), woher diese ihre Trainingsdaten nehmen. Eine Quelle scheint Common Crawl zu sein.
„Common Crawl maintains a free, open repository of web crawl data that can be used by anyone. The Common Crawl corpus contains petabytes of data, regularly collected since 2008“ (ebd.)
Die Daten werden von Amazon gehostet, können allerdings auch ohne Amazon-Konto genutzt werden. Eine Datensammlung, die für jeden frei nutzbar und transparent ist, und sogar rechtlichen und Datenschutz-Anforderungen genügt, wäre schon toll.
Es ist also Vorsicht geboten, wenn man Common Crawl nutzen möchte. Dennoch kann diese Entwicklung interessant für diejenigen sein, die ihr eigenes, auf den Werten von Open Source AI basierendes KI-Modell nutzen wollen. Siehe dazu auch