Im April fand in Rom eine Konferenz für Henry Chesbrough statt, um das Werk des Forschers zu seinem 70. Geburtstag zu ehren. Chesbrough hat mit seinem Ansatz eines eher offenen Innovationsprozesses (Open Innovation) in Organisationen, und auch in Forschungsbereichen viel bewirkt.
Enge Mitstreiter haben sich daher in Rom zusammengefunden, auch um Paper zum Thema und zur Person vorzustellen, die in den nächsten Monaten veröffentlicht werden sollen.
„The April 2026 event is thus organized as a paper development workshop in three tracks: for the CMR special issue, the ICC special section, or the R&D Mgmt special issue“ (ebd.).
Ich bin sehr auf die verschiedenen Veröffentlichungen gespannt, denn ich habe den Weg von Henry Chesbrough in den letzten Jahren intensiv verfolgt.

Beispielsweise habe ich Henry Chesbrough schon auf dem MCPC 2011: 6th Worldcongress on Mass Customization, Personalization and Co-Creation, UC Berkeley, San Francisco, USA (Blogbeitrag) live erlebt.
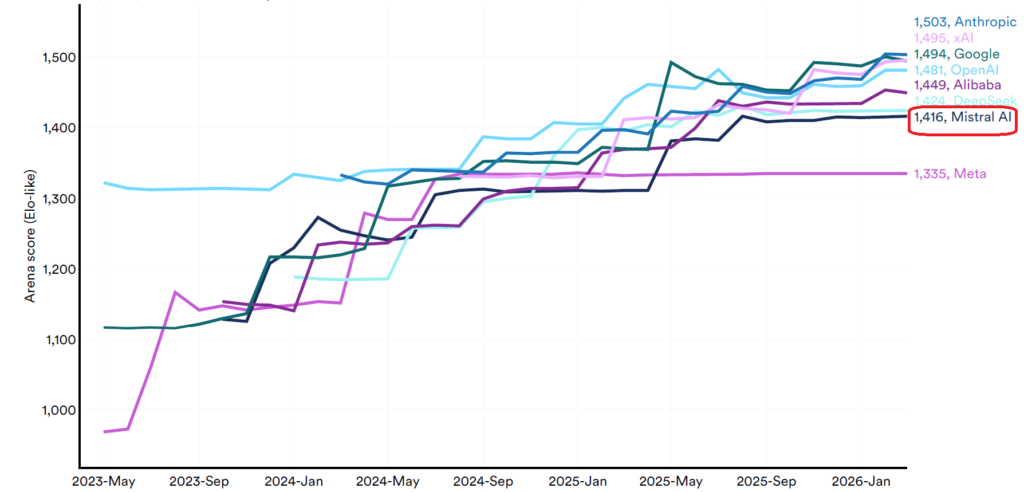
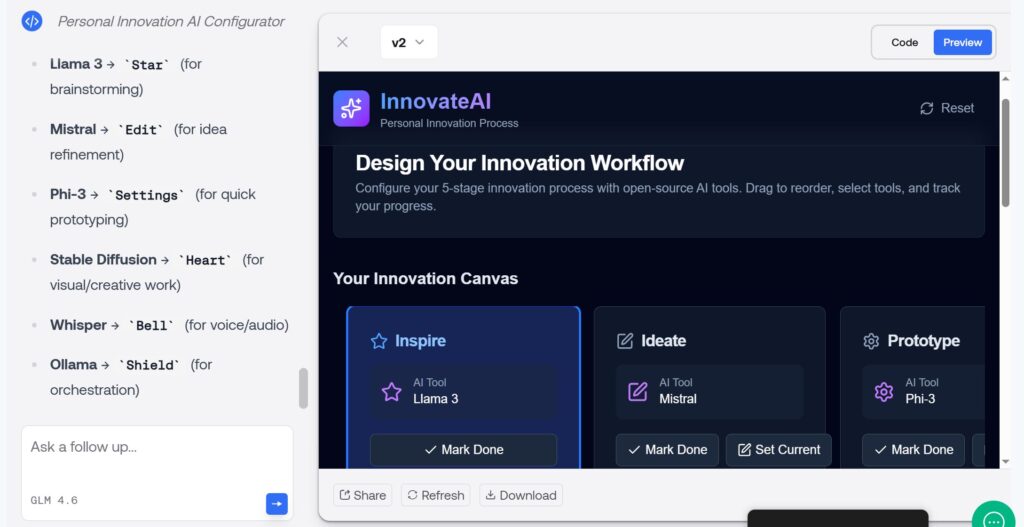
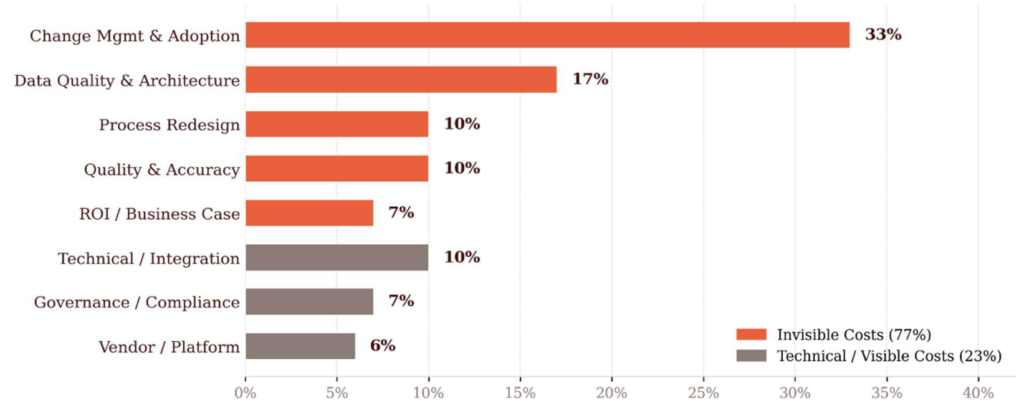
Es war auch für mich inspirierend zu sehen, wie die Öffnung des Innovationsprozesses (Open Innovation) in Organisationen entwickelt werden kann, und was es für die Organisationen und für deren Kunden bedeutet. In der Zwischenzeit gibt es in allen Bereichen Beispiele für die den erfolgreichen Einsatz von Open Innovation – auch in Zeiten Künstlicher Intelligenz.

In einem meiner beiden Paper, die für die MCP 2026, 16.-19.09.2026, Balatonfüred, Ungarn angenommen wurde, gehe ich auch auf Open Innovation ein. Allerdings betrachte ich hier eher die Perspektive von Eric von Hippel, der Open User Innovation favorisiert.