Es gibt für Projektmanagement internationale und nationale Normen, Standards und Vorgehensmodelle. Alle sind mehr oder weniger branchenunabhängig. Dennoch gibt es natürlich in den verschiedenen Branchen Besonderheiten, die berücksichtigt werden sollten.
Das Projektmanagement in Öffentlichen Verwaltungen, oder auch bei NGOs (Non-Government Organisations) und Not-for-Profit Organisationen, haben im Gegensatz zu wirtschaftlichen Unternehmen häufig gesellschaftliche, soziale Ziele. Siehe dazu auch Wirkungstreppe bei Not-for-Profit-Projekten: Output, Outcome und Impact.
Der folgende englischsprachige Guide stellt das Projektmanagement für die genannten Branchen ausführlich dar.
PM4NGOs (2025): Social Good DPro Guide – Project Management for Social Good. Erste Veröffentlichung 2020, aktualisiert im Mai 2025 | Link
Bei der Durchsicht fallt auf, dass viele angesprochenen Elemente des Projektmanagements branchenunabhängig sind und sich an den gängigen Standards orientieren. Ich hätte mir gewünscht, dass der Guide noch stärker auf die branchenspezifischen Besonderheiten eingeht.
Wenn es um allgemein verfügbare Daten aus dem Internet geht, können die bekannten Closed Source KI-Modelle erstaunliche Ergebnisse liefern. Dabei bestehen die genutzten Trainingsdaten der LLMs (Large Language Models) oft aus den im Internet verfügbaren Daten – immer öfter allerdings auch aus Daten, die eigentlich dem Urheberrecht unterliegen, und somit nicht genutzt werden dürften.
Wenn es um die speziellenDaten einer Branche oder eines Unternehmens geht, sind deren Daten nicht in diesen Trainingsdaten enthalten und können somit bei den Ergebnissen auch nicht berücksichtigt werden. Nun könnte man meinen, dass das kein Problem darstellen sollte, immerhin ist es ja möglich ist, die eigenen Daten für die KI-Nutzung zur Verfügung zu stellen – einfach hochladen. Doch was passiert dann mit diesen Daten?
Wollen Sie wirklich IHRE Daten solchen Modellen zur Verfügung stellen, um DEREN Wettbewerbsfähigkeit zu verbessern?
“So here’s the deal: you’ve got data. That data you have access to isn’t part of these LLMs at all. Why? Because it’s your corporate data. We can assure you that many LLM providers want it. In fact, the reason 99% of corporate data isn’t scraped and sucked into an LLM is because you didn’t post it on the internet. (…) Are you planning to give it away and let others create disproportionate amounts of value from your data, essentially making your data THEIR competitive advantage OR are you going to make your data YOUR competitive advantage?” (Thomas et al. 2025).
Doch was ist die Alternative? Nutzen Sie IHRE Daten zusammen mit Open Source AI auf ihren eigenen Servern. Der Vorteil liegt klar auf der Hand: Alle Daten bleiben bei Ihnen.
AI (Artificial intelligence) AI management and support technology in the Business plan marketing success customer. AI management concept.
Der Finanzbereich mit seinen unglaublichen Mengen an Daten (historische Daten und Echtzeitdaten) ist prädestiniert für den Einsatz Künstlicher Intelligenz (KI, oder englisch AI: Artificial Intelligence). Die Nutzung von LLM (Large Language Models) ,oder in Zukunft Small Language Models (SLM) und KI-Agenten, kann für eine Gesellschaft positiv, oder eher negativ genutzt werden. Dabei können Open Source AI Models, Open Weights Models und Closed AI Models unterschieden werden.
Es ist aus meiner Sicht gut, dass die Europäische Union mit dem EUAI-Act weltweit erste Rahmenbedingungen für die Nutzung Künstlicher Intelligenz festgelegt hat. Im Vergleich zu dem US-amerikanischen vorgehen (KI-Unternehmen können alles machen, um Profite zu generieren) und dem chinesischen Vorgehen (KI für die Unterstützung der Partei), ist der Europäische Weg eine gute Mischung. Natürlich muss dabei immer abgewogen werden, welcher Freiraum für Innovationen bleiben sollte.
Um nun herauszufinden, wie KI-Ssteme z.B. für den Finanzbereich bewertet und letztendlich ausgewählt werden sollten, hat das Federal Office for Information Security (Deutsch: BSI) einen entsprechenden Kriterienkatalog veröffentlicht:
“Publication Notes Given the international relevance of trustworthy AI in the financial sector and the widespread applicability ofthe EUAIAct across memberstates and beyond,this publication was prepared in English to ensure broader accessibility and facilitate collaboration with international stakeholders. English serves as the standard language in technical, regulatory, and academic discourse on AI, making it the most appropriate choice for addressing a diverse audience, including researchers, industry professionals, and policymakers across Europe and globally” (Federal Office for Information Security 2025).
Es stellt sich dabei auch die Frage, ob diese Kriterien nur für den Finanzbereich geeignet sind, oder ob alle – oder einige – der Kriterien auch für andere gesellschaftlichen Bereiche wichtig sein könnten.
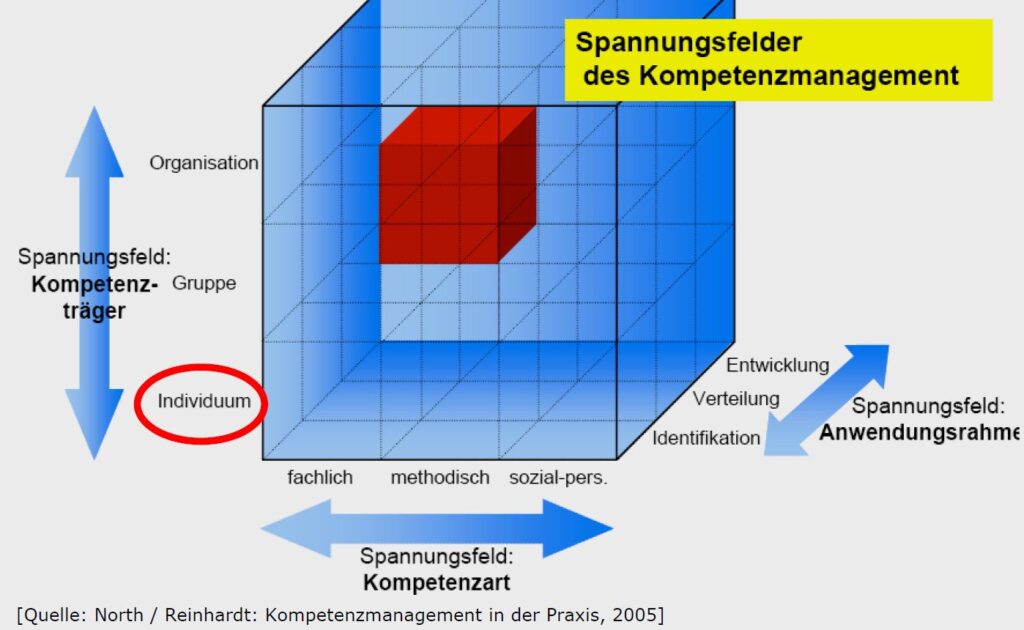
Gefunden in einem Workshop von Oliver P. Müller aus dem Jahr 2006 zu Mitarbeiterwissen identifizieren, entwickeln und dauerhaft erhalten
Die etwas ältere Abbildung zeigt gut auf, welche Spannungsfelder bei einem modernen Kompetenzmanagement zu beachten sind:
Kompetenzträger: Hier geht es um die Ebenen Individuum, Gruppe und Organisation. Hinzufügen würde ich noch die Ebene Netzwerk.
Kompetenzart: Gemeint sind hier die Fachkompetenz, die Methodenkompetenz und die Sozial-/Persönlichkeitskompetenz . Wie Sie als Leser unseres Blogs wissen, gehe ich nach Erpenbeck/Heyse von Kompetenz als Selbstorganisationsdisposition aus.
Anwendungsrahmen: Dieser Aspekt bezieht sich auf die drei Dimensionen Identifikation, Verteilung und Entwicklung. Kompetenzen sind also nicht fix, sondern relational entwickelbar.
Durch die drei Spannungsfelder entsteht eine dreidimensionale Abbildung, die einen ersten Einblick in die Dynamik des gesamten Systems gibt.
Weiterhin ist zu beachten, dass Kompetenz auf der organisationalen Ebene eher aus der betriebswirtschaftlichen Perspektive, Ressource Based View, Kernkompetenzen usw.) und Kompetenz auf der individuellen Ebene eher aus der pädagogischen Perspektive (Selbstorganisiertes Lernen etc.) betrachtet wird. In einer Organisation sollte allerdings auf allen Ebenen ein stimmiges, einheitliches Verständnis von Kompetenz und Kompetenzmanagement vorhanden sein.
Öffentliche Verwaltungen haben vielschichtige Aufgaben zu bewältigen. Aufgrund unzähliger Gesetze, Verordnungen usw. der Europäischen Union, des Bundes, der Länder, der Bezirke, der Landkreise, der Städte und Gemeinden hat sich ein Umfeld ergeben, das den Bürgern, Unternehmen, Organisationen und der öffentlichen Verwaltung selbst, kaum noch Luft zum Atmen lässt.
Die kleinteiligen Regelungen, mit ihren Millionen Schnittstellen, haben wir uns in Deutschland selbst geschaffen. Vielen wird langsam aber sicher klar, dass die öffentliche Verwaltung in manchen Bereichen des gesellschaftlichen Lebens einen Flaschenhals darstellt – Digitalisierung von Akten hin oder her.
Die Veröffentlichung GfWM (2025): Wissenstransfer und Onboarding in der öffentlichen Verwaltung ist eine Empfehlungen der GfWM-Fachgruppe Digitale Transformationsprozesse. In verschiedenen Beiträgen stellen Autoren der Fachgruppe theoretische Grundlagen und erfolgreiche Beispiele dar. Insgesamt sind das alles sehr sinnvolle Beiträge, um in Zukunft Verbesserungen in der öffentlichen Verwaltung anzustoßen.
Ich stelle mir zusätzlich folgende Fragen:
Was ist eigentlich aus den vielen Studien (zum Thema) aus der Vergangenheit (z.B. Studie aus 2013, oder länderspezifische Initiativen) geworden? Dort waren auch schon sehr viele Hilfsmittel bereitgestellt/veröffentlicht worden. Manche Vorlagen erinnern mich an ProWis, obwohl die Seite nicht speziell für die öffentliche Verwaltung ist.
Gehen alle Autoren vom selben Wissensbegriff aus? Wenn ja, von welchem? Arnold schlägt beispielsweise einen “neuen” Wissensbegriff vor.
Wenn der Wissensbegriff unklar ist, wie soll dann der Umgang mit Wissen, also auch ein Wissenstransfer gelingen?
Ist es möglich, sich auf “Wissenstransfer und Onboarding” zu konzentrieren, ohne ein geeignetes Wissenssystem mit heute sehr viel verteilten Wissensbeständen zu thematisieren?
Ist die Wissensbilanz (früher: Made in Germany) eine Möglichkeit, geeignete Ansatzpunkte (Projekte) für das jeweilige (kontextspezifische) Wissens-System zu finden, und damit Ressourcen zu sparen?
Aktuell bekannte KI-Anwendungen rühmen sich seit Jahren, sehr große Mengen an Trainingsdaten (Large Language Models) zu verarbeiten. Der Tenor war und ist oft noch: Je größer die Trainingsdatenbank, um so besser.
In der Zwischenzeit weiß man allerdings, dass das so nicht stimmt und Large Language Models (LLMs) durchaus auch Nachteile haben. Beispielsweise ist die Genauigkeit der Daten ein Problem – immerhin sind die Daten oft ausschließlich aus dem Internet. Daten von Unternehmen und private Daten sind fast gar nicht verfügbar. Weiterhin ist das Halluzinieren ein Problem. Dabei sind die Antworten scheinbar plausibel, stimmen aber nicht.
Muddu Sudhaker hat diese Punkte in seinem Artikel noch einmal aufgeführt. Dabei kommt er zu dem Schluss, dass es in Zukunft immer mehr darauf ankommen wird, kleinere, speziellere Trainingsdatenbanken zu nutzen – eben Small Language Models (SLMs).
Muddu Sudhakar (2024): Small Language Models (SLMs): The Next Frontier for the Enterprise, Forbes, LINK
Große Vorteile der SLMs sieht der Autor natürlich einmal in der Genauigkeit der Daten und damit in den besseren Ergebnissen. Weiterhin sind SLMs natürlich auch kostensparender. Einerseits sind die Entwicklungskosten geringer, andererseits benötigt man keine aufwendige Hardware, um SLMs zu betreiben. Teilweise können solche Modelle auf dem eigenen PC, oder auf dem Smartphone betrieben werden.
Solche Argumente sind natürlich gerade für Kleine und Mittlere Unternehmen (KMU) interessant, die mit den geeigneten SLMs und ihren eigen, unternehmensinternen Daten ein interessantes und kostengünstiges KI-System aufbauen können.
Voraussetzung dafür ist für mich, dass alle Daten auf den eigenen Servern bleiben, was aktuell nur mit Open Source AI möglich ist. OpenAI mit ChatGPT ist KEIN Open Source AI.
“Projektmanagement: Sie erhalten Einblicke in ausgewählte Aspekte des Projektmanagements sowie zahlreiche Impulse dazu, wie Sie Ideen und Projekte in einem Unternehmen mit Hierarchien und getrennten Verantwortungsbereichen platzieren und umsetzen können. Selbstmanagement: Angelehnt an die Heldenreise von J. Campbell können Sie die besonderen Herausforderungen je nach Projektphase reflektieren. Das unterstützt Sie im gekonnten Umgang mit Herausforderungen und bietet Ihnen die Möglichkeit zum persönlichen Wachstum” (RKW 2025).
Das Workbook können Sie herunterladen und direkt in der PDF-Datei Ihre Anmerkungen eingeben. Darüber hinaus stehen noch ergänzende Unterlagen, wie eine Projektlandkarte und ein Canvas, zur Verfügung.
Mein Eindruck ist, dass dieses Workbook einen guten niederschwelligen Einstieg bietet und Lust machen kann, sich mit Projektmanagement intensiver zu befassen. Siehe dazu auch DAS Projektmanagement-Kontinuum in der Übersicht.
Das Bild zeigt ein Glas mit einer Flüssigkeit. Es ist allerdings nicht genau zu erkennen, um welchen Inhalt es sich handelt. Es könnte also sein, dass die Flüssigkeit gut für Ihre Gesundheit ist, oder auch nicht. Vertrauen Sie dieser Situation? Vertrauen Sie demjenigen, der das Glas so hingestellt hat?
Würden Sie aus diesem Glas trinken?
So ähnlich ist die Situation bei Künstlicher Intelligenz. Die Tech-Unternehmen veröffentlichen eine KI-Anwendung nach der anderen. Privatpersonen, Unternehmen, ja ganze Verwaltungen nutzen diese KI-Apps als Black Box, ohne z.B. zu wissen, wie die Daten in den Large Language Models (LLM) zusammengetragen wurden – um nur einen Punkt zu nennen.
Der Vergleich von dem Glas mit Künstlicher Intelligenz hinkt zwar etwas, doch erscheint mir die Analogie durchaus bemerkenswert, da der erste Schritt zur Anwendung von Künstlicher Intelligenz Vertrauen sein sollte.
Step 1: It All Starts with Trust “Think about it: the glass is opaque, you can’t even see inside it! The water inside that glass could pure spring water, but it could also be cloudy and murky puddle water, or even contaminated water! If you couldn’t see inside that glass, would you still drink what’s inside it after adding tons of high-quality sugar and lemon to it? Probably not, so why would you do this with one of your company’s most previous assets—your data?” (Thomas et al. 2025).
Vertrauen Sie der Art von Künstlicher Intelligenz, wie sie von den etablierten Tech-Giganten angeboten wird? Solche Closed Source Modelle sind nicht wirklich transparent, und wollen es auch weiterhin nicht sein. Siehe dazu auch Das Kontinuum zwischen Closed Source AI und Open Source AI.
Die etablierten Automobilhersteller haben seit ca. 100 Jahren ein Selbstverständnis (Mindset), das sich hauptsächlich auf die herausragende Hardware eines Autos fokussiert (Stichwort: Spaltmaß). Software war hier ein nützliches Zusatzprodukt. Es ging prinzipiell um
HARDWARE + Software
In den letzten Jahrzehnten wird immer klarer, dass Daten und Informationen, und damit Software, in dem Ökosystem Mobilität eine immer wichtigere Rolle spielen. Viele der etablierten Autohersteller haben daher versucht, den Softwarebereich immer weiter auszubauen, um letztendlich konkurrenzfähige Software im Vergleich zu den Tech-Giganten aus dem Silicon Valley anzubieten.
Viele der Initiativen sind krachend gescheitert. Ein Konzern, der Jahrzehnte lang das Mantra der Hardware propagiert hat, kann Softwareentwicklung scheinbar nicht – zumindest nicht marktgerecht. Doch es gibt auch ein gegenteiliges Beispiel: Der Vergleich der Lines of Code für eine Autos für ein viel größere Flugzeugs (Hardware) führt zu einem überraschenden Resultat:
“Consider this: today’s cars run on about 100 million lines of code—and to put that into perspective, a Boeing 787 Dreamliner runs on just 14 million lines of code. (We know, it shocked us too.) It’s obvious that a physical car defect requires a recall, but software code defects are super costly—especially in the auto industry” (Thomas et al. 2025).
Natürlich stellt sich hier die Frage, warum in einem Auto ca. 7x mehr (im Vergleich zu einem Flugzeug) Lines of Code nötig sind. Liegt es an dem Mindset aus der Hardwareentwicklung, die Softwareentwicklung einfach zu komplex werden lässt?
Es wird weiterhin deutlich, warum sich neue Marktteilnehmer (z.B. aus China) auf Software konzentrieren und die Hardware auf ein modernes Design abstimmen. Daraus entstehen konkurrenzfähige Produkte, die den heutigen Anforderungen (Preis und Leistung) entsprechen. Diese Vorgehensweise folgt der Logik
SOFTWARE + Hardware
Es ist spannend zu beobachten, wie sich die etablierten Automobilkonzerne auf die Herausforderer einstellen, denn diese brauchen keine alten Strukturen abzubauen/umzubauen.
Aktuell wird alles mit Künstlicher Intelligenz (AI: Artificial Intelligence) in Verbindung gebracht. Die Neukombination von bestehenden Ansätzen kann dabei zu interessanten Innovationen führen.
Die Website ALL Our Ideas verbindet beispielsweise Online-Umfragen mit Crowdsourcing und Künstlicher Intelligenz.
“All Our Ideas is an innovative tool that you can use for large-scale online engagements to produce a rank-ordered list of public input. This “Wiki Survey” tool combines the best of survey research with crowdsourcing and artificial intelligence to enable rapid feedback” (ebd.).
Ein kurzes Tutorial ist gleich auf der Website zu finden. Darin wird erläutert, wie Sie die Möglichkeiten selbst nutzen können. Starten Sie einfach mit einer eigenen Online-Umfrage.
Die Idee und das Konzept finde ich gut, da auch der Code frei verfügbar ist: Open Source Code. Damit kann alles auf dem eigenen Server installiert werden. Bei der Integration von KI-Modellen schlage ich natürlich vor, Open Source KI (Open Source AI) zu nutzen.
Translate »
Diese Website benutzt Cookies. Wenn du die Website weiter nutzt, gehen wir von deinem Einverständnis aus.OK