Sir Roger Penrose ist u.a. Mathematiker und theoretischer Physiker. In 2020 hat er eine Hälfte des Nobelpreises für Physik erhalten. Penrose hat sich darüber hinaus recht kritisch mit Künstlicher Intelligenz auseinandergesetzt.
Er ist zu der Auffassung gelangt, dass man nicht von Künstlicher Intelligenz (Artificial Intelligence), sondern eher von Künstlicher Cleverness (Artificial Cleverness) sprechen sollte. Dabei leitet er seine Erkenntnisse aus den beiden Gödelschen Unvollständigkeitssätzen ab. In einem Interview hat Penrose seine Argumente dargestellt:
Sir Roger Penrose, Gödel’s theorem debunks the most important AI myth. AI will not be conscious, Interview, YouTube, 22 February 2025. This Is World. Available at: https://www.youtube.com/watch?v=biUfMZ2dts8
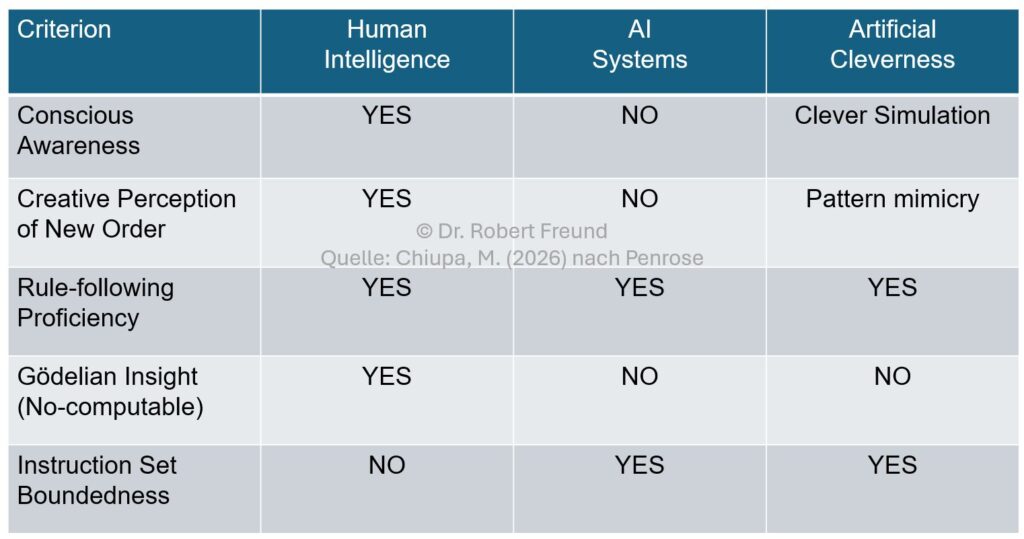
Da das alles ziemlich schwere Kost ist, hat Martin Chiupa (2026) via LinkedIn eine Übersicht (Abbildung) erstellt, die anhand verschiedener Kriterien Unterschiede zwischen Human Intelligence, AI Systems und Artificial Cleverness aufzeigt.
Darüber hinaus gibt es auch immer mehr leistungsfähige Open Source KI-Modelle, die jedem zur Verfügung stehen, und beispielsweise eher europäischen Werten entsprechen. Siehe dazu auch Das Kontinuum zwischen Closed Source AI und Open Source AI
Wenn also in Zukunft mehr als 1 Milliarde Menschen Künstliche Intelligenz nutzen, stellt sich gleich die Frage, wie Unternehmen damit umgehen. Immerhin war es üblich, dass so eine Art der intelligenten komplexen Problemlösung bisher nur spärlich – und dazu auch noch teuer – zur Verfügung stand.
Nun werden Milliarden von einzelnen Personen die Möglichkeit haben, mit geringen Mitteln komplexe Problemlösungen selbst durchzuführen. Prof. Ethan Mollick nennt dieses Phänomen in einem Blogbeitrag Mass Intelligence.
„The AI companies (whether you believe their commitments to safety or not) seem to be as unable to absorb all of this as the rest of us are. When a billion people have access to advanced AI, we’ve entered what we might call the era of Mass Intelligence. Every institution we have — schools, hospitals, courts, companies, governments — was built for a world where intelligence was scarce and expensive. Now every profession, every institution, every community has to figure out how to thrive with Mass Intelligence“ (Mollick, E. (2025): Mass Intelligence, 25.08.2025).
Ich bin sehr gespannt, ob sich die meisten Menschen an den proprietären großen KI-Modellen der Tech-Konzerne orientieren werden, oder ob es auch einen größeren Trend gibt, sich mit KI-Modellen weniger abhängig zu machen – ganz im Sinne einer Digitalen Souveränität.
In dem Beitrag Digitale Souveränität: Europa, USA und China im Vergleich wird deutlich, wie unterschiedlich die Herangehensweisen in den USA, in China und in Europa sind, wenn es um Künstliche Intelligenz geht. Darüber hinaus hat auch Japan mit dem Ansatz einer Society 5.0 beschrieben, dass Künstliche Intelligenz dazu dienen soll, die Herausforderungen einer modernen Gesellschaft zu lösen.
Auch das aufstrebende Indien hat nun seine Richtlinien für die gesellschaftliche Nutzung von Künstlicher Intelligenz (AI: Artificial Intelligence) veröffentlicht. Dabei werden gleich zu Beginn folgende 7 Prinzipien genannt:
01 Trust is the Foundation Without trust, innovation and adoption will stagnate. 02 People First Human-centric design, human oversight, and human empowerment. 03 Innovation over Restraint All other things being equal, responsible innovation should be prioritised over cautionary restraint. 04 Fairness & Equity Promote inclusive development and avoid discrimination. 05 Accountability Clear allocation of responsibility and enforcement of regulations. 06 Understandable by Design Provide disclosures and explanations that can be understood by the intended user and regulators. 07 Safety, Resilience & Sustainability Safe, secure, and robust systems that are able to withstand systemic shocks and are environmentally sustainable.
Source: Ministry of Electronics and Information Technology (2025): India AI Governance Guidelines. Enabling Safe and Trusted AI Innovation (PDF)
Bemerkenswert finde ich, dass an erster Stelle steht, dass Vertrauen die Grundlage für Innovationen bildet. Vertrauen in die Möglichkeiten der Künstlichen Intelligenz kann man meines Erachtens nur durch Transparenz erreichen. Proprietäre KI-Systeme, bei denen unklar ist, wo die Daten herkommen und wie mit (auch eigenen) Daten umgegangen wird, sind unter der genannten Bedingung (Trust) mit Vorsicht zu genießen.
Mit DeepSeek ist chinesischen Entwicklern ein Coup gelungen, denn sie konnten zeigen, dass ein KI-Modell nicht teuer sein muss. Die amerikanischen Tech-Giganten standen damals mit ihren Milliarden-Investitionen ziemlich schlecht dar.
Nun gibt es mit Kimi K2 Thinking ein weiteres Modell, mit dem chinesische Entwickler zeigen, wie mit relativ wenigen Ressourcen – und damit Kosten – ein leistungsfähiges Modell angeboten werden kann. Der Schwerpunkt des Modells liegt dabei auf „Coding“.
Es ist Open Sourcebasiert und wurde unter der MIT-Lizenz veröffentlicht. Diese enthält eine interessante Klausel: Da amerikanische Konzerne chinesische Open Source Modelle gerne für ihre Entwicklungen nutzen – ohne das transparent zu machen – ist die freie kommerzielle Nutzung bis zu einem monatlichen Umsatz von 20 Millionen Dollar möglich.
Kimi K2 Thinking ist ein MoE-Modell, (for Coding) dessen Entwicklung nur 4,6 Millionen Dollar gekostet haben soll – wieder eine beeindruckende Kennzahl. Darüber hinaus zeigen Benchmarks, die enorme Leistungsfähigkeit des Modells. Weitere Informationen sind in dem folgenden Beitrag zusammengefasst:
Mal sehen, ob wir das Modell auch in LocalAI, bzw. in Ollama auf unseren Servern einbinden können. Bis dahin kann auf der Landingpage Kimi K2 Thinking getestet werden.
Wenn es um Künstliche Intelligenz geht, kommt auch immer öfter der Hinweis auf, dass Emotionale Intelligenz immer wichtiger wird. In dem Blogbeitrag AI City und Emotionale Intelligenz wird beispielsweise auf den Zusammenhang mit AI Citys verwiesen:
“For a smart city, having only “IQ” (intelligence quotient) is not enough; “EQ” (emotional quotient) is equally essential. (…) the emotions of citizen communities …“
Hier wird also vorgeschlagen, neben dem Intelligenz-Quotienten (IQ) noch einen Emotionalen Quotienten (EQ) bei der Betrachtung zu berücksichtigen.
Doch was verstehen wir unter „Emotionale Intelligenz“?
Ich beziehe mich hier auf eine Beschreibung von Salovay und Mayer, und bewusst nicht auf den populären Ansatz von Goleman:
“Emotional intelligence is a type of social intelligence that involves the ability to monitor one’s own and others’ emotions to discriminate among them, and to use the information to guide one’s thinking and actions (Salovey & Mayer 1990)”, cited in Mayer/Salovay 1993, p. 433).
Die Autoren sehen also Emotionale Intelligenz als Teil einer Sozialen Intelligenz. Spannend ist weiterhin, dass Mayer und Salovay ganz bewusst einen Bezug zur Multiplen Intelligenzen Theorie von Howard Gardner herstellen. Siehe Emotionale Intelligenz: Ursprung und der Bezug zu Multiplen Intelligenzen.
Betrachten wir nun Menschen und AI Agenten im Zusammenspiel, so muss geklärt werden, woran AI Agenten (bisher) bei Entscheidungen scheitern. Dazu habe ich folgenden Text gefunden:
“AI agents don’t fail because they’re weak at logic or memory. They fail because they’re missing the “L3” regions — the emotional, contextual, and motivational layers that guide human decisions every second” (Bornet 2025 via LinkedIn).
Auch Daniel Goleman, der den Begriff „Emotionale Intelligenz“ populär gemacht hat, beschreibt den Zusammenhang von Emotionaler Intelligenz und Künstlicher Intelligenz am Arbeitsplatz, und weist auf die erforderliche Anpassungsfähigkeit (Adaptability) hin:
„Adaptability: This may be the key Ei competence in becoming part of an AI workplace. Along with emotional balance, our adaptability lets us adjust to any massive transformation. The AI future will be different from the present in ways we can’t know in advance“ (EI in the Age of AI, Goleman via LinkedIn, 30.10.2025).
Bei Innovationen sollten wir uns zunächst einmal klar machen, was im Unternehmenskontext darunter zu verstehen ist. Das Oslo Manual schlägt vor, Innovation wie folgt zu interpretieren:
„(…) a new or improved product or process (or combination thereof) that differs significantly from the unit’s previous products or processes and that has been made available to potential users (product) or brought into use by the unit (process)” (Oslo Manual 2018).
Dass Innovation u.a. eine Art Neu-Kombination von Existierendem bedeutet, ist vielen oft nicht so klar (combination thereof). Neue Ideen – und später Innovationen – entstehen oft aus vorhandenen Konzepten. oder Daten.
An dieser Stelle kommen nun die Möglichkeiten der Künstlichen Intelligenz (GenAI oder auch AI Agenten) ins Spiel. Mit KI ist es möglich, fast unendlich viele Neu-Kombinationen zu entwickeln, zu prüfen und umzusetzen. Das können Unternehmen nutzen, um ihre Innovationsprozesse neu zu gestalten, oder auch jeder Einzelne für seine eigenen Neu-Kombinationen im Sinne von Open User Innovation nutzen. Siehe dazu Von Democratizing Innovation zu Free Innovation.
Entscheidend ist für mich, welche KI-Modelle dabei genutzt werden. Sind es die nicht-transparenten Modelle der Tech-Unternehmen, die manchmal sogar die Rechte von einzelnen Personen, Unternehmen oder ganzer Gesellschaften ignorieren, oder nutzen wir KI-Modelle, die frei verfügbar, transparent und für alle nutzbar sind (Open Source AI)?
In den letzten Jahren wird immer deutlicher, dass Künstliche Intelligenz unser wirtschaftliches und gesellschaftliches Leben stark durchdringen wird. Dabei scheint es so zu sein, dass die Künstliche Intelligenz der Menschlichen Intelligenz weit überlegen ist. Beispielsweise kann Künstliche Intelligenz (GenAI) äußerst kreativ sein, was in vielfältiger Weise in erstellten Bildern oder Videos zum Ausdruck kommt. In so einem Zusammenhang behandeln wir Künstliche Intelligenz (AI: Artificial Intelligence) wie Kreative und im Gegensatz dazu Menschen eher wie Roboter. Dazu habe ich folgenden Text gefunden:
„We are treating humans as robots and ai as creatives. it is time to flip the equation“ (David de Cremer in Bornet et al. 2025).
David de Cremer ist der Meinung, dass wir die erwähnte „Gleichung“ umstellen sollten. Dem kann ich nur zustimmen, denn das aktuell von den Tech-Giganten vertretene Primat der Technik über einzelne Personen und sogar ganzen Gesellschaften sollte wieder auf ein für alle Beteiligten gesundes Maß reduziert werden. Damit meine ich, dass die neuen technologischen Möglichkeiten einer Künstlichen Intelligenz mit den Zielen von Menschen/Gesellschaften und den möglichen organisatorischen und sozialen Auswirkungen ausbalanciert sein sollten.
Dennoch ist deutlich zu erkennen, dass es immer mehr Anbieter in allen möglichen Segmenten von Künstlicher Intelligenz – auch bei den Language Models – gibt. Wenn man sich alleine die Vielzahl der Modelle bei Hugging Face ansieht: Heute, am17.09.2025, stehen dort 2,092,823 Modelle zur Auswahl, und es werden jede Minute mehr. Das erinnert mich an die Diskussionen auf den verschiedenen (Welt-) Konferenzen zu Mass Customization and Personalization. Warum?
Large Language Models (LLM):One Size Fits All Wenn es um die bei der Anwendung von Künstlicher Intelligenz (GenAI) verwendeten Trainingsmodellen geht, stellt sich oft die Frage, ob ein großes Modell (LLM: Large Language Model) für alles geeignet ist – ganz im Sinne von “One size fits all”. Diese Einschätzung wird natürlich von den Tech-Unternehmen vertreten, die aktuell mit ihren Closed Source Models das große Geschäft machen, und auch für die Zukunft wittern. Die Argumentation ist, dass es nur eine Frage der Zeit ist, bis das jeweilige Large Language Model die noch fehlenden Features bereitstellt – bis hin zur großen Vision AGI: Artificial General Intelligence. Storytelling eben…
Small Language Models (SLM): Variantenvielfalt In der Zwischenzeit wird immer klarer, dass kleine Modelle (SLM) viel ressourcenschonender, in speziellen Bereichen genauer, und auch wirtschaftlicher sein können. Siehe dazu Künstliche Intelligenz: Vorteile von Small Language Models (SLMs) und Muddu Sudhakar (2024): Small Language Models (SLMs): The Next Frontier for the Enterprise, Forbes, LINK.
Komplexitätsfalle Es wird deutlich, dass es nicht darum geht, noch mehr Möglichkeiten zu schaffen, sondern ein KI-System für eine Organisation passgenau zu etablieren und weiterzuentwickeln. Dabei sind erste Schritte schon zu erkennen: Beispielsweise werden AI-Router vorgeschlagen, die verschiedene Modelle kombinieren – ganz im Sinne eines sehr einfachen Konfigurators. Siehe dazu Künstliche Intelligenz: Mit einem AI Router verschiedene Modelle kombinieren.
Mit Hilfe eines KI-Konfigurators könnte man sich der Komplexitätsfalle entziehen. Ein Konfigurator in einem definierten Lösungsraum (Fixed Solution Space) ist eben das zentrale Element von Mass Customization and Personalization.
Die Lösung könnte also sein, massenhaft individualisierte KI-Modelle und KI-Agents dezentralisiert für die Allgemeinheit zu schaffen. Am besten natürlich alles auf Open Source Basis – Open Source AI – und für alle in Repositories frei verfügbar. Auch dazu gibt es schon erste Ansätze, die sehr interessant sind. Siehe dazu beispielsweise (Mass) Personalized AI Agents für dezentralisierte KI-Modelle.
Genau diese Überlegungen erinnern – wie oben schon angedeutet – an die Hybride Wettbewerbsstrategie Mass Customization and Personalization. Die Entgrenzung des definierten Lösungsraum (Fixed Solution Space) hat dann weiter zu Open Innovation (Chesbrough und Eric von Hippel) geführt.
Mit KI Agenten (AI Agents) ist es möglich, in der Geschäftswelt vielfältige Prozesse zu optimieren, oder innovative Prozesse, Produkte und Dienstleistungen zu generieren, die bisher aus den verschiedensten Gründen nicht möglich waren. Dazu zählen oftmals nicht verfügbare Daten und die dazugehörenden Kosten.
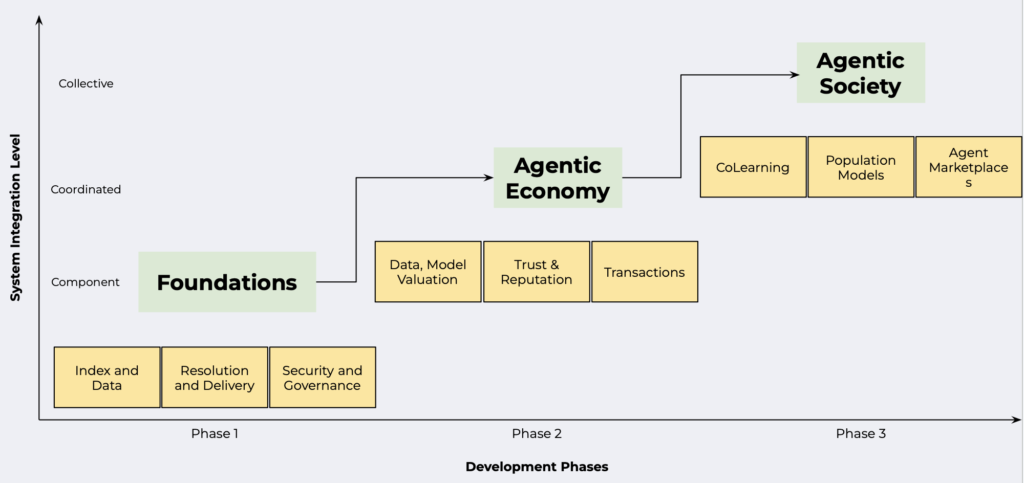
Denken wir etwas weiter, so müssen in Zukunft auch immer stärker KI-Agenten miteinander kommunizieren, also von Agent zu Agent – A2A. Passiert das zwischen sehr vielen Agenten eines Wirtschaftssystems, bzw. einer ganzen Gesellschaft, entsteht so etwas wie eine Agentic Society.
Das Projekt NANDA hat sich in dem Zusammenhang das Ziel gesetzt, diese Entwicklung mit einem Open Agentic Web zu unterstützen:
„Imagine billions of specialized AI agents collaborating across a decentralized architecture. Each performs discrete functions while communicating seamlessly, navigating autonomously, socializing, learning, earning and transacting on our behalf“ (Source).
Das vom MIT initiierte Projekt NANDA arbeitet in Europa u.a. mit der TU München und der ETH Zürich zusammen. Das Ziel ist, alles Open Source basiert zur Verfügung zu stellen..
Ich bin an dieser Stelle immer etwas vorsichtig, da beispielsweise OpenAI auch beim Start das Ziel hatte, KI als Open Source zur Verfügung zu stellen. In der Zwischenzeit wissen wir, dass OpenAI ein Closed Source Model, bzw. ein Open Weights Model ist, und kein Open Source Model. Siehe dazu Das Kontinuum zwischen Closed Source AI und Open Source AI.
Using watsonx.governance to build a dashboard and track a multimodel deployment environment (Thomas et al. 2025)
In verschiedenen Beiträgen hatte ich beschrieben, was eine Organisation machen kann, um KI-Modelle sinnvoll einzusetzen. An dieser Stelle möchte ich nur einige wenige Punkte beispielhaft dazu aufzählen.
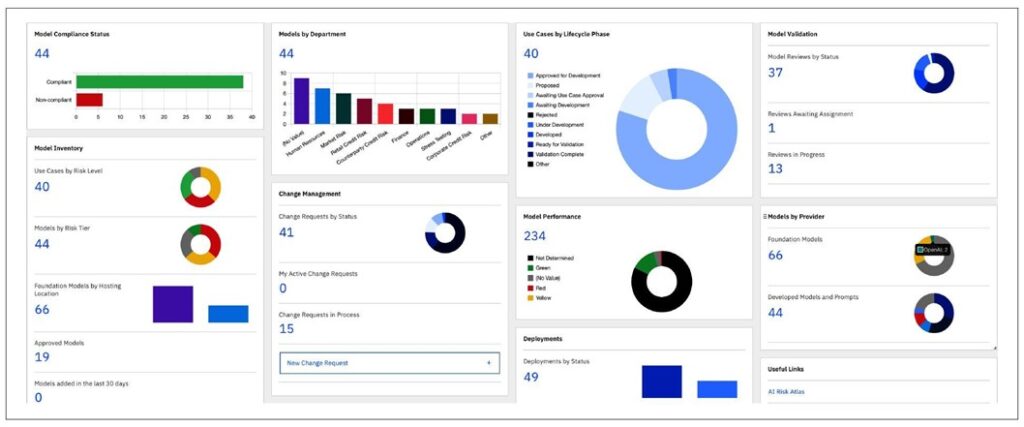
Das sind nur einige Beispiele dafür, dass eine Organisation aufpassen muss, dass die vielen Aktivitäten sinnvoll und wirtschaftlich bleiben. Doch: Wie können Sie das ganze KI-System verfolgen und verbessern? In der Abbildung sehen Sie ein Dashboard, dass den Stand eines KI-Frameworks abbildet. Die Autoren haben dafür IBM watsonx Governance genutzt.
„Our dashboard gives us a quick view of our environment. There are LLMs from OpenAI, IBM, Meta, and other models that are in a review state. In our example, we have five noncompliant models that need our attention. Other widgets define use cases, risk tiers, hosting locations (on premises or at a hyper scaler), departmental use (great idea for chargebacks), position in the approval lifecycle, and more“ (Thomas et al. 2025).
Die Entwicklungen im Bereich der Künstlichen Intelligenz sind vielversprechend und in ihrer Dynamik teilweise auch etwas unübersichtlich. Das geeignete KI-Framework zu finden, es zu entwickeln, zu tracken und zu verbessern wird in Zukunft eine wichtige Aufgabe sein.
Diese Website benutzt Cookies. Wenn du die Website weiter nutzt, gehen wir von deinem Einverständnis aus.