Die Nutzung den bekannten KI-Modelle (GenAI) wie ChatGPT, Gemini, Grok, Anthropic, Claude etc ist weit verbreitet. Es ist auch möglich, diese Modelle mit eigenen Daten zu trainieren, doch ist der Großteil dann immer noch zu wenig unternehmensspezifisch. Siehe dazu auch Digitale Souveränität: Europa, USA und China im Vergleich.
Mistral AI ist hier in den letzten Jahren einen eigenen Weg gegangen, indem es als europäische Modell Familie DSGVO-konform ist, und auch als Open Source AI zur Verfügung steht.
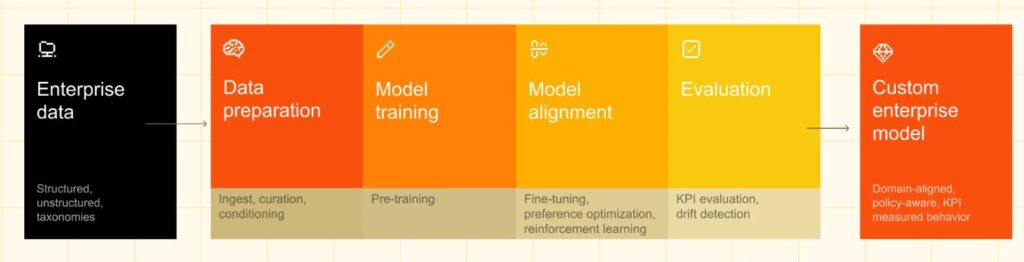
Mit dem nun veröffentlichten Mistral Forge können Unternehmen auf Basis der eigenen Daten und Expertise ihr eigenes KI-Modell entwickeln.
From your data to your model
Vorgehensweise bei Mistral Forge: https://mistral.ai/products/forge
Die einzelnen Schritte werden auf der genannten Webseite ausführlich dargestellt. Es wir spannend zu sehen, welche Organisationen diesen Weg gehen werden. Aktuell sind das immerhin so bekannte Namen wie ASML, Ericsson, ESA und DSO National Laboratories aus Singapur. Siehe dazu auch
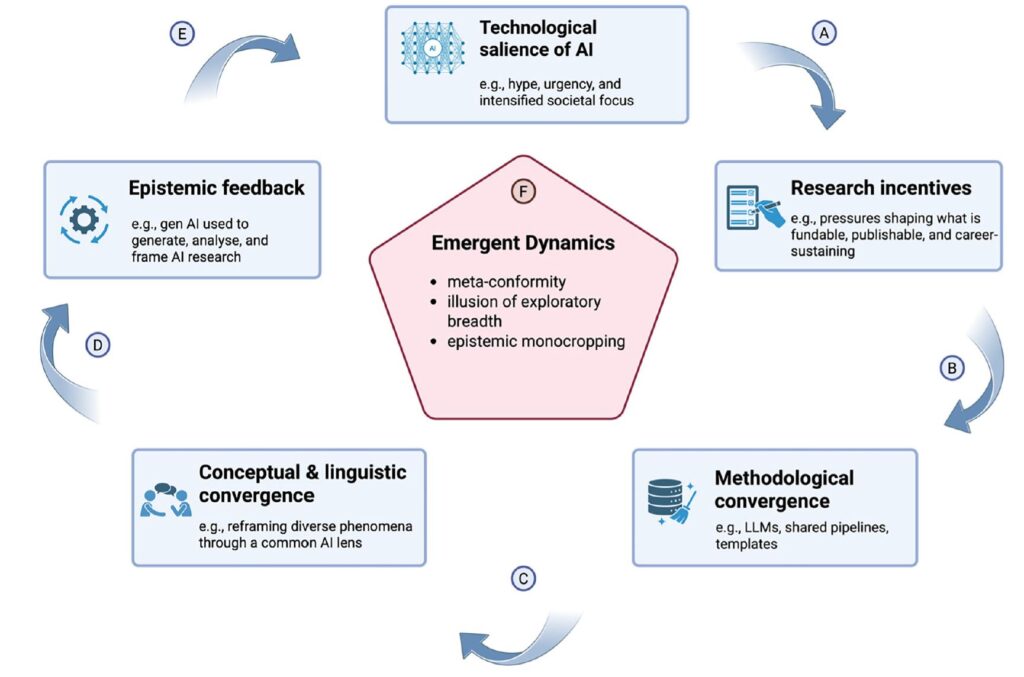
AI monoculture feedback loop (Traberg et al. 2026)
In allen möglichen Kontexten soll und wird Künstliche Intelligenz genutzt. Dabei dominieren in unserem Kulturkreis die von den amerikanischen Konzernen entwickelten GenAI-Modelle. Diese werden in allen privaten und organisatorischen Prozessen integriert. Ein Großteil der Personen und Organisationen nutzen dabei die gleichen KI-Workflows.
Das hat beispielsweise im wissenschaftlichen Kontext einen unschönen Effekt: Dadurch, dass alle Wissenschaftler mehr oder weniger stark die selben GenAI-Modelle für ihre Arbeiten nutzen, kommt es zu einer Art „wissenschaftlicher Monokultur„.
Traberg, C.S., Roozenbeek, J. & van der Linden, S. AI is turning research into a scientific monoculture. Commun Psychol4, 37 (2026). https://doi.org/10.1038/s44271-026-00428-5
In der Abbildung ist der Kreislauf mit seinen einzelnen Schritten dargestellt. Es wird deutlich, dass es sich hier um eine Art Generator handelt, also ein sich selbst verstärkender Wirkungskreislauf.
Auch hier wird deutlich, dass es gut ist, verschiedene KI-Modelle für wissenschaftliche Arbeiten zu nutzen, und die jeweiligen Ergebnisse zu bewerten.
Es stellt sich natürlich auch gleich die Frage, ob diese „wissenschaftliche Monokultur“ auch bei Innovationsprozessen vorkommt. Auch hier nutzen viele Personen und Unternehmen oftmals die gleichen KI-Modelle.
Die dort oftmals hinterlegten Daten, die natürlich zum überwiegenden Teil in Englisch (oder Chinesisch) vorliegen, spiegeln nicht die vielfältige europäische Kultur mit ihren vielen Nuancen wieder. Kulturelle Bereiche, definieren sich oftmals über die jeweilige Sprache.
Es ist daher nicht verwunderlich, dass es in den jeweiligen europäischen Ländern einen Trend gibt, KI-Modelle zu entwickeln, die die jeweilige sprachlichen Besonderheiten beachten – wie z.B. Minerva AI LLM:
Minerva AI LLM is the first family of Large Language Modelspretrained from scratch in Italian developed by Sapienza NLP in collaboration with Future Artificial Intelligence Research (FAIR) and CIN AIECA. The Minerva models are truly-open (data and model) Italian-English LLMs, with approximately half of the pretraining data composed of Italian text. You can chat with Minerva for free directly through the app — it’s easy, fast, and open to everyone.
Es handelt sich also um eine Modell-Familie, die offen für jeden nutzbar ist. Es zeigt sich auch hier wieder, dass Künstliche Intelligenz auf Vertrauen basieren muss, damit sie den gesellschaftlichen und wirtschaftlichen Anforderungen gerecht werden kann. Siehe dazu auch beispielhaft
Die verwendete Sprache, und hier speziell die verwendeten Begriffe, lassen oft Rückschlusse auf die dazugehörende Denkweise (Mindset) zu. Beispielsweise ist die Metapher „Unternehmen als Maschine“ oder „Menschen sind Zahnräder“ sinnbildlich für eine sehr mechanistische Denkweise, die heute in vielen Bereichen nicht mehr angemessen erscheint.
Der Begriff „Verbraucher“ hat eine ähnliche Wirkung. In vielen Meldungen, Statistiken usw. wird immer noch der Begriff verwendet, gerade so, als ob alle Produkte und Dienstleistungen verzehrt werden, also einer Abnutzung unterliegen.
„Verbrauch ist in der Wirtschaftstheorie der Verzehr von Gütern und Dienstleistungen zur direkten oder indirekten Bedürfnisbefriedigung. Ein Synonym für Verbrauch ist Konsum“ (Quelle: Wikipedia) Bei einem Acker ist das so, da hier die Fläche begrenzt, und nicht so einfach erweiterbar ist. Es leuchtet daher ein, dass versucht wird, das „maximale aus dem Boden herauszuholen“.
Bei digitalen Produkten ist das etwas anders. Auf das eben beschriebene Beispiel angewendet bedeutet das: „Der digitale Acker ist ein Zauberhut, aus dem sich ein Kaninchen nach dem anderen ziehen lässt, ohne dass er jemals leer würde. Die »Verbraucher« von Informationsgütern »verbrauchen« ja eben gerade nichts“ (Grassmuck 2004, Bundeszentrale für politische Bildung (bpb), 2., korrigierte Auflage).
In einer immer stärker digitalisierten Welt, werden digitale Produkte und Dienstleistungen durch deren Nutzung nicht „verbraucht“, sondern ganz im Gegenteil: Durch die Nutzung von Daten und Informationen entstehen wieder viele neue Daten, die dann oftmals von Unternehmen wertschöpfend genutzt werden. Daten sind für diese Unternehmen das neue Öl.
Im Zusammenhang mit digitalen Produkten (Daten, Informationen, Wissen) sollten wir daher nicht mehr von „Verbraucher“ sprechen, da der Begriff einfach nicht mehr passt.
Large Language Models (LLMs) benötigen eine Unmenge an Daten. Bei den Closed Source KI-Modellen von OpenAI, Meta, etc. ist manchmal nicht so klar (Black Box), woher diese ihre Trainingsdaten nehmen. Eine Quelle scheint Common Crawl zu sein.
„Common Crawl maintains a free, open repository of web crawl data that can be used by anyone. The Common Crawl corpus contains petabytes of data, regularly collected since 2008“ (ebd.)
Die Daten werden von Amazon gehostet, können allerdings auch ohne Amazon-Konto genutzt werden. Eine Datensammlung, die für jeden frei nutzbar und transparent ist, und sogar rechtlichen und Datenschutz-Anforderungen genügt, wäre schon toll.
Es ist also Vorsicht geboten, wenn man Common Crawl nutzen möchte. Dennoch kann diese Entwicklung interessant für diejenigen sein, die ihr eigenes, auf den Werten von Open Source AI basierendes KI-Modell nutzen wollen. Siehe dazu auch
Digitale Souveränität wird oftmals mit Daten-Souveränität in Organisationen verwechselt. Es ist daher wichtig zu verstehen, was Organisationale Daten-Souveränität ausmachen kann. Dazu habe ich folgenden Vorschlag in einem Paper gefunden:
„We define organizational data sovereignty as the self-determined and deliberate exercise of control over an organization’s data assets, which includes the recognition of their value, the proactive management of data activities (collection, storage, sharing, analysis, and interpretation), and the ability to assimilate and apply these data to drive value creation through interorganizational collaboration“ (Moschko et al. 2024).
In dem Paper geht es den Autoren um Organisationale Daten-Souveränität in Bezug auf Open Value Creation (OVC) in offenen Innovationsprozessen (Open Innovation).
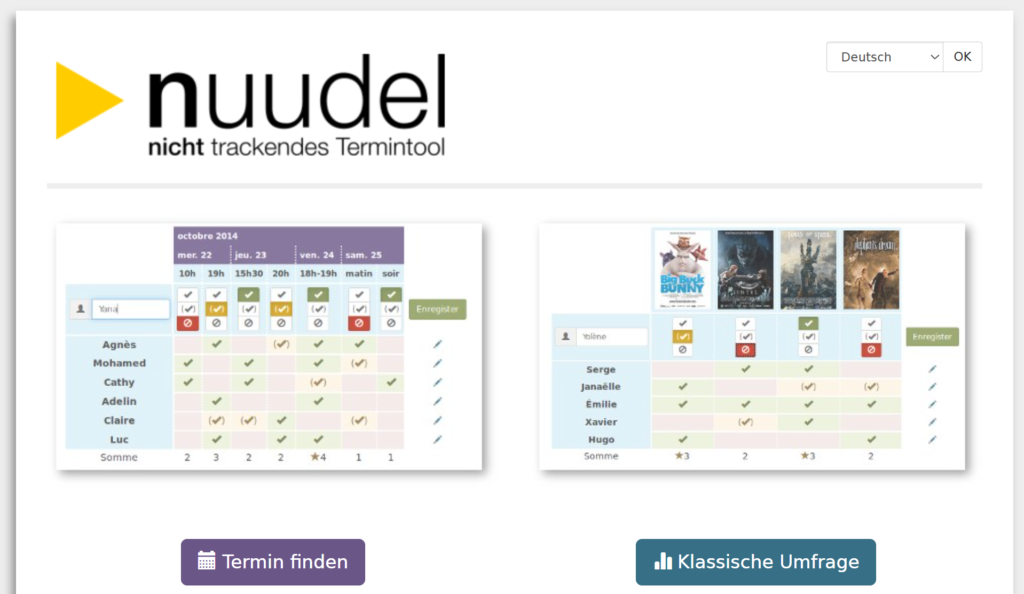
Viele Menschen nutzen Doodle für die einfache Terminabstimmung. Im Sinne einer Digitalen Souveränität kann alternativ Nuudle genutzt werden. Wie die Abbildung zeigt, können über Termine hinaus auch noch klassische Umfragen erstellt werden.
Nuudle ist ein datensparsames Termintool und unterstützt daher Personen und Organisationen, die ihre Daten schützen möchten.
Das Tool ist auf der Website von digitalcourage zu finden, auf der es viele Hinweise dazu gibt, wie man seine eigenen Daten schützen kann. Manches finde ich gut, manches etwas überzogen – wie immer…
Screenshot von der Startseite https://www.opennewswire.org/
In der heutigen Daten- und Informationsflut ist es gut zu wissen, welchen Informationen man trauen kann. Viele Quellen wollen manipulieren, aufhetzen, oder einfach nur Klicks generieren. In diesem Umfeld ist Vertrauen ein wichtiges Gut.
Professionelle Journalisten traut man zu, Inhalte zu sammeln, aufzuarbeiten und ohne Wertung an den Leser zu bringen. Wertungen können ja in separaten Kommentaren geschrieben werden. Solche Artikel stehen auf der Plattform Open Newswire „frei“ zur Verfügung.
Über die Plattform Open Newswire ist das in über 90 Sprachen möglich. Es handelt sich um ein Non Profit Projekt, das 2020 von einem australischen Journalisten gestartet wurde. Die Artikel unterliegen den hier gelisteten Creative Commons Licences.
Wenn aber der erste Schritt zur Nutzung von Künstlicher Intelligenz Vertrauen sein sollte (Thomas et al. 2025), sollte man sich als Privatperson, als Organisation, bzw. als Verwaltung nach Alternativen umsehen.
Wie Sie als Leser unseres Blogs wissen, tendieren wir zu (wirklichen) Open Source AI Modellen, doch in dem Buch von Thomas et al. (2025) ist mir auch der Hinweis auf das von IBM veröffentlichte KI-Modell Granite aufgefallen. Die quelloffene Modell-Familie kann über Hugging Face, Watsonx.ai oder auch Ollama genutzt werden.
Das hat mich neugierig gemacht, da wir ja in unserer LocalAI Modelle dieser Art einbinden und testen können. Weiterhin haben wir ja auch Ollama auf unserem Server installiert, um mit Langflow KI-Agenten zu erstellen und zu testen.
Im Fokus der Granite-Modellreihe stehen Unternehmensanwendungen, wobei die kompakte Struktur der Granite-Modelle zu einer erhöhten Effizienz beitragen soll. Unternehmen können das jeweilige Modell auch anpassen, da alles über eine Apache 2.0-Lizenz zur Verfügung gestellt wird.
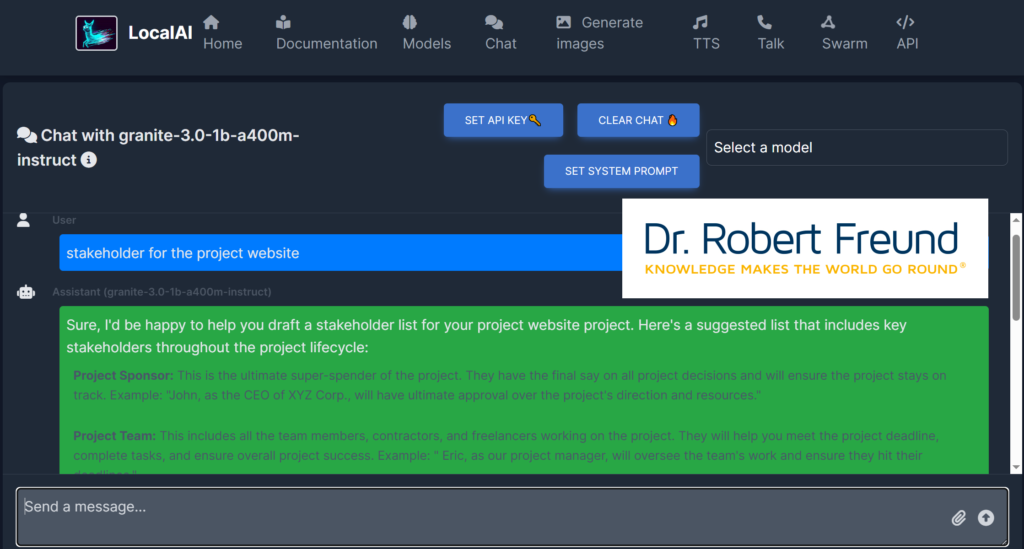
Wie Sie der Abbildung entnehmen können, haben wir Granite 3.0 -1b-a400m in unsere lokale KI (LocalAI) eingebunden. Das geht relativ einfach: Wir wählen aus den aktuell mehr als 1.000 Modellen das gewünschte Modell zunächst aus. Anschließend brauchen wir nur auf „Installieren“ zu klicken, und das Modell steht in der Auswahl „Select a model“ zur Verfügung.
Im unteren Fenster (Send a message) habe ich testweise „Stakeholder for the project Website“ eingegeben. Dieser Text erscheint dann blau hinterlegt, und nach einer kurzen Zeit kommen dann schon die Ergebnisse, die in der Abbildung grün hinterlegt sind. Wie Sie am Balken am rechten Rand der Grafik sehen können, gibt es noch mehrere Stakeholder, die man sieht, wenn man nach unten scrollt.
Ich bin zwar gegenüber Granite etwas skeptisch, da es von IBM propagiert wird, und möglicherweise eher zu den Open Weighted Models zählt, doch scheint es interessant zu sein, wie sich Granite im Vergleich zu anderen Modellen auf unserer LocalAI-Installation schlägt.
Bei allen Tests, die wir mit den hinterlegten Modellen durchführen, bleiben die generierten Daten alle auf unserem Server.
Kultur ist ein häufig verwendeter Begriff, der oftmals auf Länder bezogen ist (Französische Kultur, Italienische Kultur, Westliche Kultur, Chinesische Kultur etc.) und doch nicht so einfach an irgendwann einmal gezogenen Ländergrenzen halt macht. Dabei sollte auch die Diskussion über Kultur und Werte kritisch gesehen werden. Entsteht Kultur top-down oder bottom-uo, bzw. sowohl-als-auch? Siehe dazu beispielsweise Kritische Anmerkungen zum Wertansatz von Kultur.
Kann es in dieser vielschichtigen Betrachtung überhaupt EINE Kultur geben (Kultur ist statisch), oder ist Kultur ein sich permanent wandelnder Begriff mit über die Zeit immer wieder neuen Anpassungen an die Wirklichkeit?
Eine weitere Frage ist:Welche Zusammenhänge gibt es zwischen Kultur und Daten?
Einerseits kann eine Kultur natürlich Daten beeinflussen, indem Werte und damit Grenzen und Bewertungen vorgegeben werden. Darüber hinaus entscheidet Kultur auch, ob Daten frei oder eher verschlossen zur Verfügung stehen.
Andererseits können generierte Daten, gerade Big Data, Open Data usw., eine Kultur beeinflussen, indem neue Erkenntnisse und damit oft verbunden neue Möglichkeiten/Innovationen entstehen. Aktuell sehen wir an den Entwicklungen bei der Künstlichen Intelligenz, wie große Trainingsdaten (Large Language Models) starken Einfluss auf eine Gesellschaft und die jeweilige(n) Kultur(en) nehmen.
Es bleibt abzuwarten, in welchen Bereichen positiv, und in welchen negativ. Aktuell sieht es für mich so aus, als ob die Tech-Unternehmen die Gewinne aus der Nutzung Künstlicher Intelligenz für sich beanspruchen, und sich um die sozialen Konsequenzen für eine Gesellschaft nicht kümmern.
Wer etwas tiefer einsteigen möchte, kann sich folgendes Buch (Open Access) ansehen:
Schäfer, M. T.; van Els, K. (Eds.) (2017): The Datafied Society. Studying Culture through Data | PDF.
Diese Website benutzt Cookies. Wenn du die Website weiter nutzt, gehen wir von deinem Einverständnis aus.