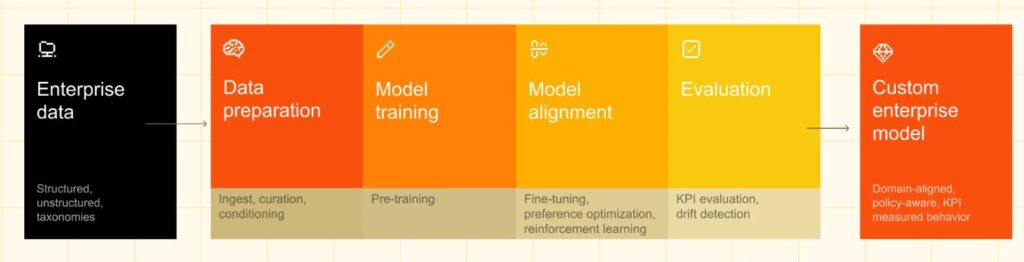
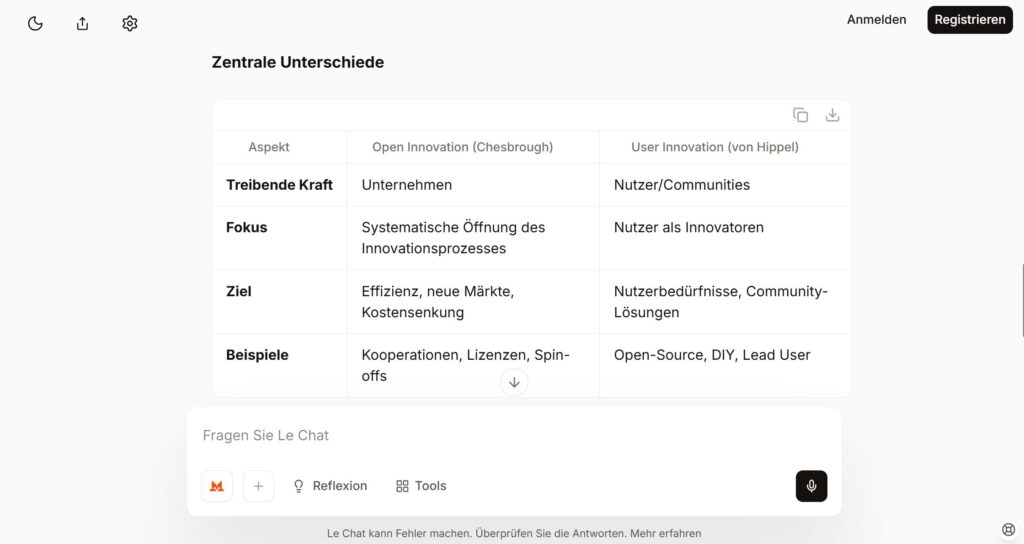
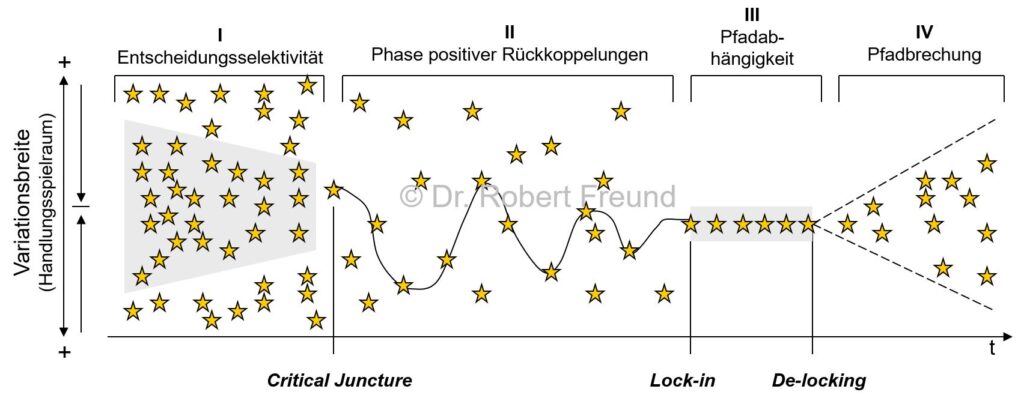
Alle KI-Anwendungen basieren darauf, dass Daten zur Verfügung stehen. Bei den bekannten proprietären Anbietern ist die Herkunft der Daten, und der Umgang mit den Daten oft nicht transparent. Diese KI-Modelle werden daher auch Closed AI Models genannt.
Demgegenüber gibt es die (wirklichen) Open Source KI-Modelle, die sich an der Definition von Open Source AI orientieren, somit transparent sind, wie Mistral AI auch in Europe gehostet werden, und der DSGVO entsprechen.
Solche Modelle können auf viele frei verfügbaren Daten (Open Data) in Europa, Deutschland, ja sogar aus Ihrer Region zurückgreifen. Für Einzelpersonen und für Kleine und Mittlere Unternehmen (KMU) ist das wichtig, um keine rechtlichen Probleme bei der KI-Anwendung zu bekommen.
Ein guter Einstieg ist European Data – Das offizielle Portal für Daten zu Europa.
Dort kann man für jedes Land analysieren, welche Datensätze zur Verfügung stehen. In der folgenden Abbildung ist zu erkennen, dass für Deutschland 855.325 Datensätze (Stand: 05.04.2026) vorliegen..
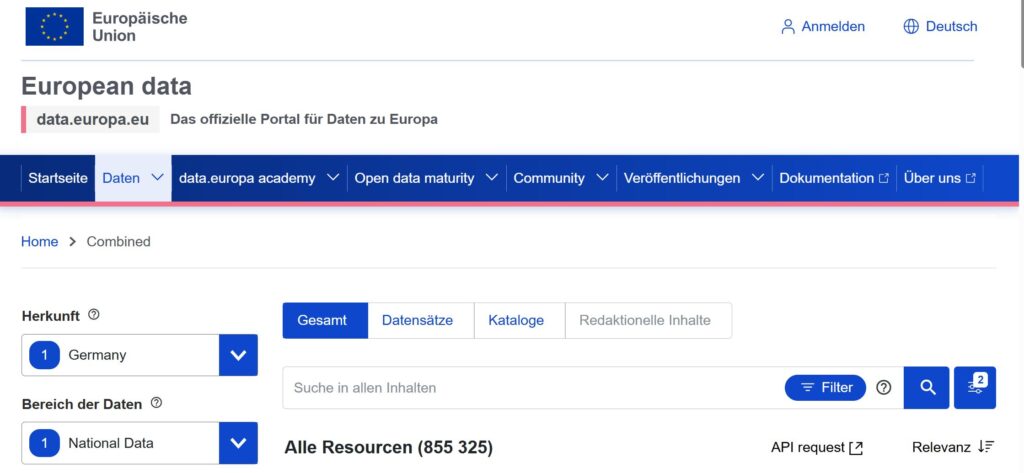
Auf der Seite können Sie weiter auswählen und so die Datensätze (Open Data) recherchieren, die Sie für Ihre Anwendungen (Innovationen) im Unternehmen oder auch für sich selbst nutzen wollen.
Die Datensätze können dann in KI-Modelle eingebunden werden. Wir schlagen natürlich vor, Open Source KI zu verwenden, beispielsweise Mistral 3 Modellfamilie. Siehe dazu auch meine verschiedenen Blogbeiträge zu Mistral AI.
Open Data and Open Source AI – a perfect match. Ganz im Sinne einer Digitalen Souveränität.