deployment environment (Thomas et al. 2025)
In verschiedenen Beiträgen hatte ich beschrieben, was eine Organisation machen kann, um KI-Modelle sinnvoll einzusetzen. An dieser Stelle möchte ich nur einige wenige Punkte beispielhaft dazu aufzählen.
Zunächst können LLM (Large Language Models) oder SLM (Small Language Models) eingesetzt werden – Closed Sourced , Open Weighted oder Open Source. Weiterhin können KI-Modelle mit Hilfe eines AI-Routers sinnvoll kombiniert, bzw. mit Hilfe von InstructLab mit eigenen Daten trainiert werden. Hinzu kommen noch die KI-Agenten – aus meiner Sicht natürlich auch Open Source AI.
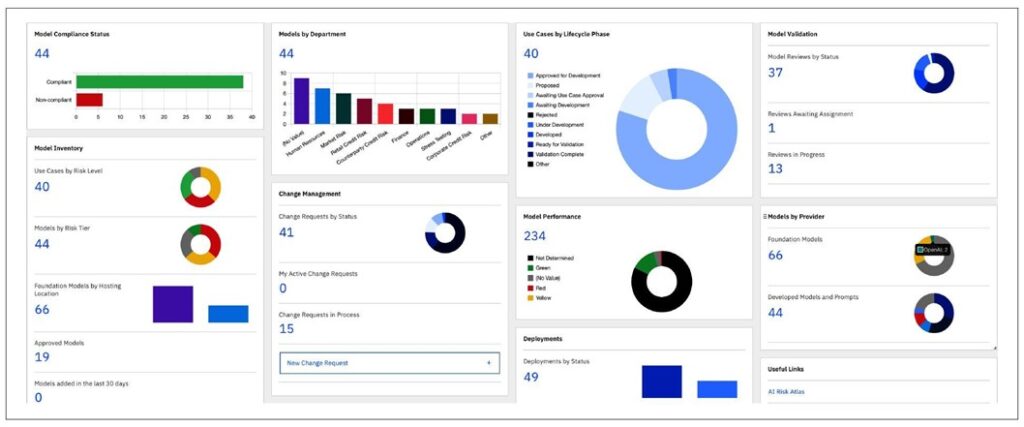
Das sind nur einige Beispiele dafür, dass eine Organisation aufpassen muss, dass die vielen Aktivitäten sinnvoll und wirtschaftlich bleiben. Doch: Wie können Sie das ganze KI-System verfolgen und verbessern? In der Abbildung sehen Sie ein Dashboard, dass den Stand eines KI-Frameworks abbildet. Die Autoren haben dafür IBM watsonx Governance genutzt.
„Our dashboard gives us a quick view of our environment. There are LLMs from OpenAI, IBM, Meta, and other models that are in a review state. In our example, we have five noncompliant models that need our attention. Other widgets define use cases, risk tiers, hosting locations (on premises or at a hyper scaler), departmental use (great idea for chargebacks), position in the approval lifecycle, and more“ (Thomas et al. 2025).
Die Entwicklungen im Bereich der Künstlichen Intelligenz sind vielversprechend und in ihrer Dynamik teilweise auch etwas unübersichtlich. Das geeignete KI-Framework zu finden, es zu entwickeln, zu tracken und zu verbessern wird in Zukunft eine wichtige Aufgabe sein.
