Conceptual technology illustration of artificial intelligence. Abstract futuristic background
Für komplexe Problemlösungen ist es wichtig, implizites Wissen zu erschließen. Wenig überraschend stellt Polanyi daher die Meister-Lehrling-Beziehung, in der sich Lernen als Enkulturationsprozess vollzieht, als essentielles Lern-Lern-Arrangement heraus:
„Alle Kunstfertigkeiten werden durch intelligentes Imitieren der Art und Weise gelernt, in der sie von anderen Personen praktiziert werden, in die der Lernende sein Vertrauen setzt“ (PK, S. 206). (Neuweg 2004).
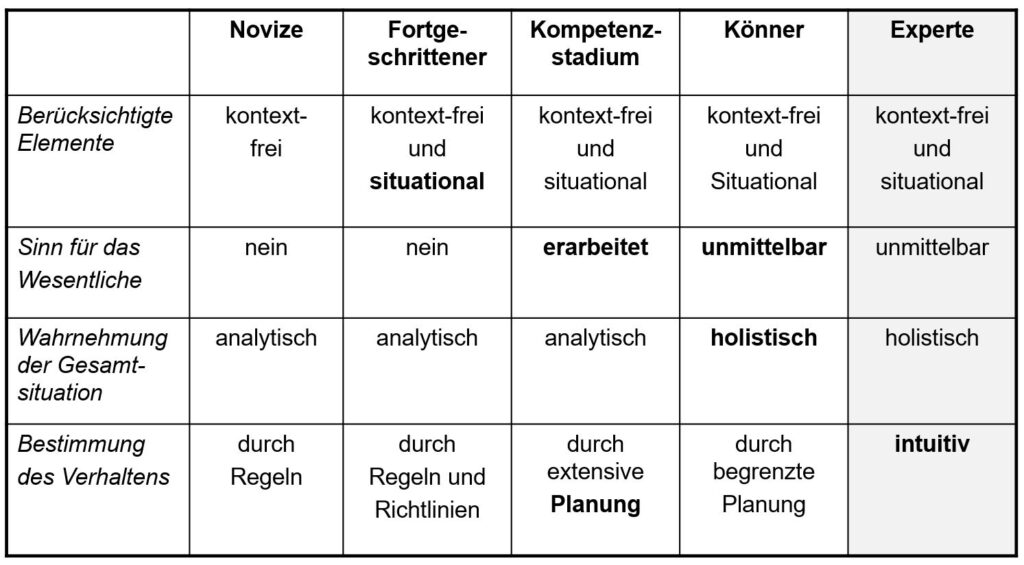
Das setzt auch die Anerkenntnis der Autorität des Experten voraus. Nach Dryfus/Dryfus ergeben sich vom Novizen bis zum Experten folgende Stufen der Kompetenzentwicklung:
Das Modell des Fertigkeitserwerbs nach Dreyfus/Dreyfus (Neuweg 2004)
Wenn wir uns nun die Beziehung zwischen Künstlicher Intelligenz und dem (nutzenden) Menschen ansehen, so kann diese Beziehung oftmals wie eine Meister-Lehrling-Beziehung beschrieben werden.
Dabei ist die „allwissende“ Künstliche Intelligenz (z.B. in Form von ChatGPT etc.) der antwortende Meister, der die Fragen (Prompts) des Lehrlings (Mensch) beantwortet. Gleichzeitig wird vom Lehrling (Mensch) die Autorität des Meisters (ChatGPT) anerkannt. Dieser Aspekt kann dann allerdings auch für Manipulationen durch die Künstliche Intelligenz genutzt werden.
Ein weiterer von Polanyi angesprochene Punkt ist das erforderliche Vertrauen auf der Seite des Lernenden in den Meister. Kann ein Mensch als Nutzer von Künstlicher Intelligenz Vertrauen in die KI-Systeme haben? Siehe dazu Künstliche Intelligenz – It All Starts with Trust.
Gerade wenn es um komplexe Probleme geht hat das Lernen von einer Person, gegenüber dem Lernen von einer Künstlichen Intelligenz, Vorteile. Die Begrenztheit von KI-Agenten wird beispielhaft auf der Plattform Rent a Human deutlich, wo: KI-Agenten Arbeit für Menschen anbieten, denn
Sir Roger Penrose ist u.a. Mathematiker und theoretischer Physiker. In 2020 hat er eine Hälfte des Nobelpreises für Physik erhalten. Penrose hat sich darüber hinaus recht kritisch mit Künstlicher Intelligenz auseinandergesetzt.
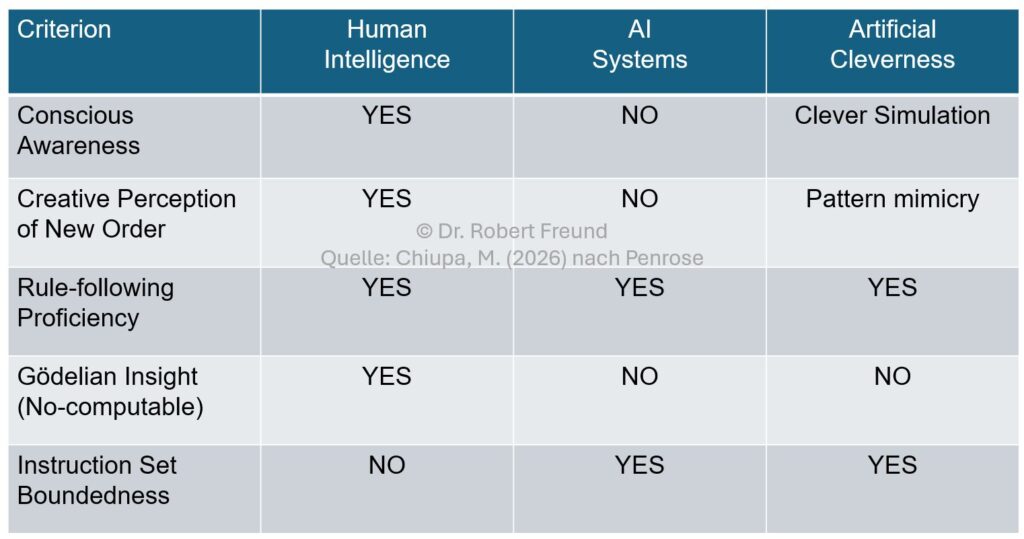
Er ist zu der Auffassung gelangt, dass man nicht von Künstlicher Intelligenz (Artificial Intelligence), sondern eher von Künstlicher Cleverness (Artificial Cleverness) sprechen sollte. Dabei leitet er seine Erkenntnisse aus den beiden Gödelschen Unvollständigkeitssätzen ab. In einem Interview hat Penrose seine Argumente dargestellt:
Sir Roger Penrose, Gödel’s theorem debunks the most important AI myth. AI will not be conscious, Interview, YouTube, 22 February 2025. This Is World. Available at: https://www.youtube.com/watch?v=biUfMZ2dts8
Da das alles ziemlich schwere Kost ist, hat Martin Chiupa (2026) via LinkedIn eine Übersicht (Abbildung) erstellt, die anhand verschiedener Kriterien Unterschiede zwischen Human Intelligence, AI Systems und Artificial Cleverness aufzeigt.
Aufmerksamkeit generieren und für die eigenen Belange zu nutzen, ist ein zentrales Element der Aktivitäten in allen Medien – besonders natürlich in den Sozialen Medien und bei der Nutzung von Künstlicher Intelligenz. Es ist verständlich, dass alles getan wird, um die Aufmerksamkeit nicht zu verlieren. Dennoch ist global ein Aufmerksamkeits-Defizit zu beobachten:
„Diese Entwicklung ist global zu erkennen und als global attention deficit bekannt, „(..) verursacht durch Psychotechnologien, die durch keine politische Macht reguliert werden. Sie sind die Ursache für die Regression der Intelligenz und für ein Konsumverhalten, das sich auf die Zukunft des Planeten zunehmend zerstörerisch auswirkt“ (Stiegler 2008).
Die Aufmerksamkeitsstörung wird zu einem Aufmerksamkeitsdefizit, das durch ein immer stärkeres Benutzer-Profiling reguliert werden soll. Die Überlegung dazu ist: Wenn eine Organisation den Nutzer besser kennt, also das User-Profil kennt, kann die Organisation dafür sorgen, dass sie die Aufmerksamkeit des Users gewinnen, bzw. behalten kann.
Interessant ist allerdings, dass diese Profilingsysteme dazu führen können, dass sie genau das Gegenteil bewirken – es ist paradox:
„Die Profilingsysteme zerstören die beobachtendeAufmerksamkeit und ersetzen sie durch eine konservierendeAufmerksamkeit, durch eine Standardisierung des Subjekts, das offenkundig in das Stadium seiner eigenen Grammatisierung eingetreten ist: eine Grammatisierung seines „psychischen Profils“ – hier seines „Aufmerksamkeitsprofils“ -, die es im Grunde ermöglicht, das Subjekt gewissermaßen am Ursprung seines Bewusstseinsstroms, durch den es bisher als Aufmerksamkeit existierte, zu entindividualisieren“ (Stiegler 2008).
Eine „konservierende Aufmerksamkeit“, die auch von KI-Bots offen und subtil angestrebt wird. Bei vielen Nutzern scheint das auch zu funktionieren.
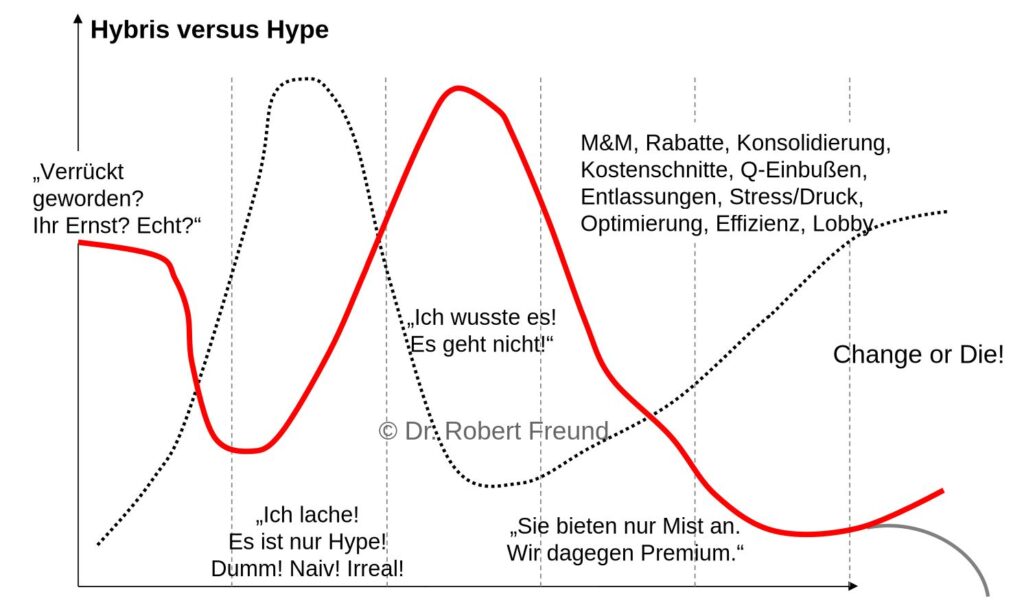
Wenn es um die zeitliche Entwicklung von neuen Technologien und deren Innovationen geht, wird oft der Gardner Hype Cycle herangezogen, der in der Abbildung gepunktet dargestellt ist.
Der Hype um neue Technologien bahnt sich zunächst an, erreicht einen Peak und anschließend die Phase der Ernüchterung, bis sich dann endlich durch die Nutzung die Spreu vom Weizen trennt: Change or Die!
Interessant ist, wenn man dem Gardner Hype Cycle die entsprechende Hybris gegenüberstellt – in der Abbildung rot hervorgehoben.
Die Hybris (altgriechisch für Übermut‘, ‚Anmaßung‘) bezeichnet Selbstüberschätzung oder Hochmut. Man verbindet mit Hybris häufig den Realitätsverlust einer Person und die Überschätzung der eigenen Fähigkeiten, Leistungen oder Kompetenzen, vor allem von Personen in Machtpositionen. (Quelle: vgl. Wikipedia).
In der Abbildung finden Sie die in den jeweiligen Phasen anzutreffenden Äußerungen, die die Hybris – den Übermut, die Selbstüberschätzung oder auch die Anmaßung und den Realitätsverlust – über die Zeit ausdrücken.
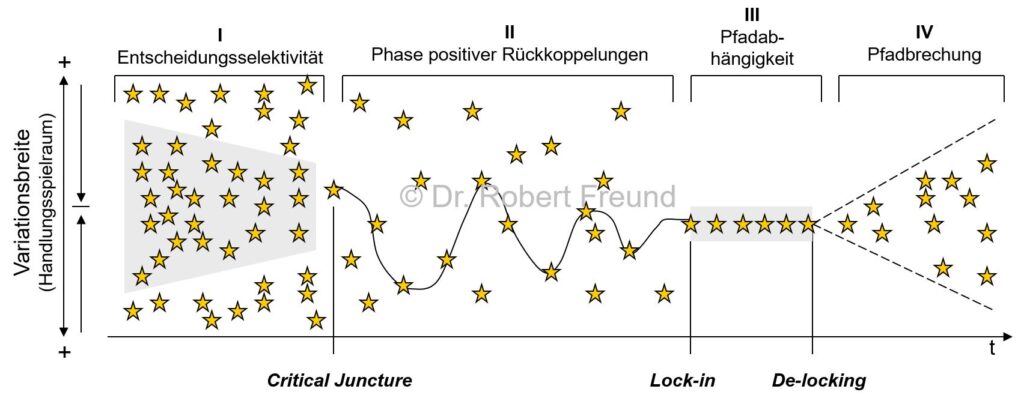
Bei Innovationen wird oft die Theorie der Pfadabhängigkeit thematisiert. Dabei ist am Anfang, in der Phase I der Entscheidungsselektivität, die Variationsbreite noch groß. Mit der Zeit wechselt die Situation (Critical Juncture) in die Phase II der positiven Rückkopplungen. Hier ist der Handlungsspielraum noch immer groß, doch die verfügbaren Varianten reduzieren sich. Eine gewisse Gewohnheit stellt sich ein, und es kommt zu einem Lock-in in der Phase III der Pfadabhängigkeit.
Diese Phasen können wir aktuell bei der Nutzung von KI-Modellen gut nachvollziehen, wobei ich vermute, dass viele durch die Nutzung der bekannten proprietären KI-Modelle wie ChatGPT, Gemini, Anthropic, Grok usw. in der Phase der Pfadabhängigkeit sind.
Es wundert daher nicht, dass Anbieter wie ChatGPT nun langsam aber sicher anfangen, diese Situation zu monetarisieren, und z.B. Werbung schalten. Diese Situation ist für viele Nutzer ärgerlich, doch stellen sich bei einem gewünschten Wechsel zu anderen KI-Modellen nun Switching Cost ein, die zu einer Hürde werden. Ein De-locking ist möglich, doch mit Aufwand verbunden.
„Pfadabhängigkeit heißt ja: Prozesse sind nicht durch unsere Entscheidungen und Pläne zu determinieren, sondern nehmen ihren erst Schritt für Schritt näher bestimmten Verlauf in einem spezifischen Wechsel von Kontingenz und Notwendigkeit – in Folge von lauter intendierten und nicht-intendierten Effekten, schließlich in Folge von Selbstverstärkungseffekten, vor denen sich die Entscheidungsgewalt der Entscheider vollends blamiert (Ortmann 2009:11).
In der aktuellen Situation kann es dazu kommen, dass wir aus Bequemlichkeit nicht aus der Pfadabhängigkeit herauskommen. Vielen Nutzern ist diese Situation nicht bewusst. Sie glauben immer noch, dass sie es sind, die die KI-Systeme mit ihren Eingaben (Prompts) steuern…. Siehe dazu auch Digitale Souveränität: Europa, USA und China im Vergleich.
Wir gehen oft noch von scheinbar eindeutigen Ursache-Wirkungs-Zusammenhängen aus (Reduktionismus), Wir schließen beispielsweise bei einer intelligenten Handlung (Wirkung) eines Menschen auf eine möglicherweise dahinterliegende menschliche Intelligenz (Ursache).
Dass es solche einfachen Zusammenhänge in komplexen Systemen so nicht gibt, wurde schon vor vielen Jahrzehnten von Ryle bezweifelt. Er nannte ein solches Vorgehen Intellektualistische Legende. und erläutert: „Die intelligente Praxis“ (Ryle (1949:28), „ist nicht ein Stiefkind der Theorie“.
„Ganz allgemein gesprochen, macht die intellektualistische Legende die absurde Annahme, jede Verrichtung, welcher Art auch immer sie sei, erwerbe ihren gesamten Anspruch auf Intelligenz von einer vorausgehenden inneren Planung dieser Verrichtung“ (Siehe dazu weitaus differenzierter Neuweg, G. H. (2004): Könnerschaft und implizites Wissen).
Doch: Wo versteckt sich dann die Intelligenz?
Dazu schreibt Ryle: „Eine intelligente Handlung „hat eine besondere Art oder Ausführung, nicht besondere Vorgänger“ (1949, S. 36). Natürlich weist sie über sich selbst hinaus, aber „die Ausübung ist keine Doppeloperation, bestehend aus theoretischem Bekennen von Maximen und darauffolgender Umsetzung in die Praxis“ (1949, S. 56). Auch wenn wir eine Disposition, die sich als flexibles Können zeigt, mit Recht als Zeichen von Intelligenz betrachten, ist nicht eine innerliche Schattenhandlung, sondern das Können selbst der Trägerder Intelligenz. Intellektuelle Operationen sind keine Ausführungen, die zu intelligenten Tätigkeiten hinzutreten. „Offene intelligente Verrichtungen sind nicht der Schlüssel zur Arbeit des Geistes; sie sind diese Arbeit“ (1949, S. 73)“ (vgl. Neuweg 2004).
Wenn also das Können selbst Träger der Intelligenz ist, und eine scheinbar intelligente Handlung eines Menschen nicht auf seine Menschliche Intelligenz zurückzuführen ist, so kann auch die „intelligente Handlung“ eines KI-Modells nicht auf eine Art von Künstlicher Intelligenz zurückgeführt werden – ein Kategorienfehler? Siehe dazu auch
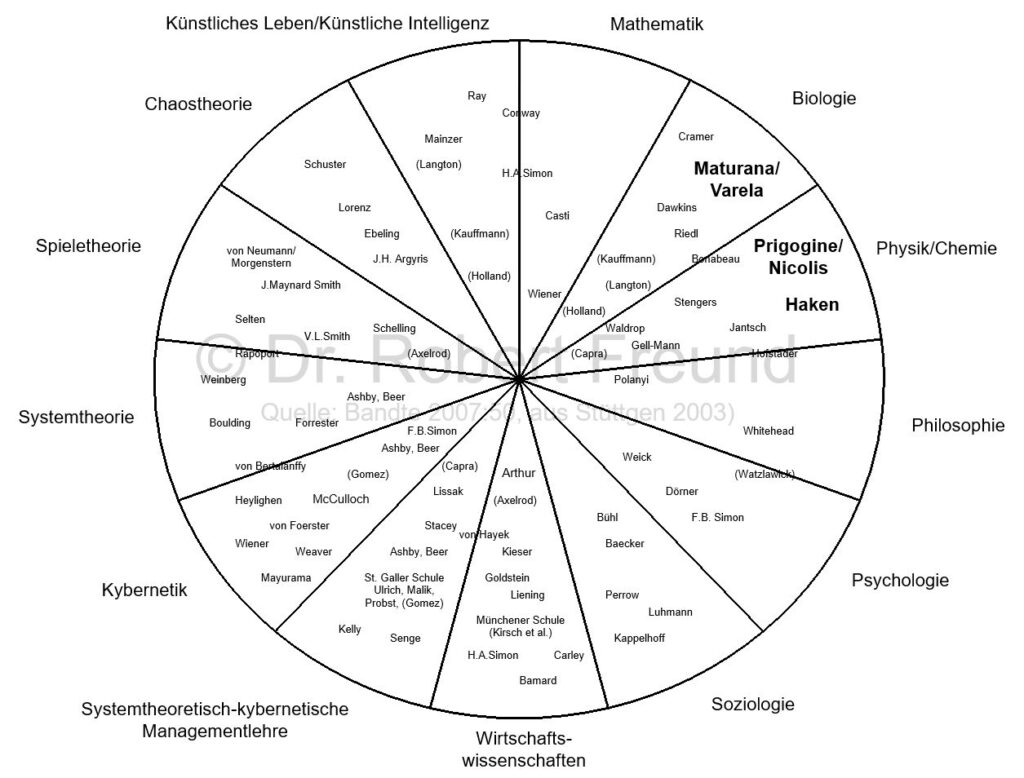
Wesentliche Vertreter der Grundlagen einer Komplexitätswissenschaft und Vorreiter einer terminologischen Präzisierung von Komplexität (Bandte 2007:50, aus Stüttgen 2003): Eigene Hervorhebungen
In unserer komplexen Welt verwenden viele den Begriff „Komplexität“, doch fragt man nach wird deutlich, dass an unterschiedliche naturwissenschaftliche Ansätze gedacht wird. In der Abbildung sind daher wesentliche Vertreter der Grundlagen einer Komplexitätswissenschaft und Vorreiter einer terminologischen Präzisierung von Komplexität zu sehen, die den verschiedenen Disziplinen zugeordnet sind
Ein wesentlicher Schwerpunkt in der Komplexitätsdiskussion befasst sich mit SELBSTORGANISATION. In der Abbildung sind von mir bekannte Vertreter zu Selbstorganisations-Theorien hervorgehoben, die aus den Bereichen Biologie und Physik/Chemie kommen. Überraschend ist dabei, dass viele wichtige Theorien zum Thema um 1970 fast zeitgleich erschienen sind:
„Es war der magische Zeitpunkt um 1970, als fast zeitgleich erste naturwissenschaftliche Theorien der Selbstorganisation erschienen, die eine paradigmatische Wende einläuteten: die biologische Theorie der Autopoiese von Humberto Maturana, die Arbeit zur molekularen Evolution von Manfred Eigen, die thermodynamische Theorie dissipativer Systeme fernab vom Gleichgewicht von Ilya Prigogine sowie die aus der Quantenoptik und der Theorie der Phasenübergänge stammende Theorie der Synergetik von Hermann Haken. Die Begründer dieser Theorien kamen aus sehr unterschiedlichen Disziplinen“ (Petzer/Steiner 2016).
Da ich mich viel mit Innovationen befasse, ist es mir natürlich wichtig zu erfahren, welche Passung diese Theorien mit der Entstehen neuer Dienstleistungen, Produkte oder (allgemein) neuen Gesellschaftsstrukturen haben. Sehr interessant ist dabei, dass die Autopoiese (Maturana) wohl nicht so gut geeignet erscheint, und die Synergetik von Haken (1996) wohl besser passt:
„Obwohl die Autopoiese einen großen Einfluss im biologischen und vor allem im soziologischen Bereich hat, so ist ihr Bezug zur Selbstorganisation eher im zirkulären Wirken bestehender Ordnung zu sehen. In Hinblick auf die Entstehung (Emergenz) von Ordnung und verschiedener Ordnungsstufen trifft die Autopoiese keine Aussagen. Sie setzt bereits Ordnung voraus. Daher sah Hermann Haken auch keinen Anlass sich mit dieser, vor allem im Rahmen des Radikalen Konstruktivismus in der Literatur hofierten und diskutierten Theorie, intensiver auseinanderzusetzen.
Übertragen auf soziale Systeme kann die Autopoiesetheorie Innovation oder die Entstehung neuer Gesellschaftsstrukturen nicht thematisieren„.
Quelle: (Petzer/Steiner 2016). Die Autoren nennen zur Unterstützung dieser These noch folgende Quellen:
– Hermann Haken: Synergetics. An Introduction, New York, NY: Springer 1977. – Bernd Kröger: Hermann Haken und die Anfangsjahre der Synergetik, Berlin: Logos 2013, S. 259. – Vgl. auch Marie-Luise Heuser: „Wissenschaft und Metaphysik. Überlegungen zu einer allgemeinen Selbstorganisationstheorie“, in: Wolfgang Krohn/Günter Küppers (Hg.): Selbstorganisation.
„Es genügt also, das Verhalten der wenigen instabilen Systemelemente zu erkennen, um den Entwicklungstrend des gesamten Systems und seine makroskopischen Muster zu bestimmen. Die Größen, mit denen das Verteilungsmuster der Mikrozustände eines Systems charakterisiert wird, heißen nach dem russischen Physiker Lew D. Landau „Ordnungsparameter““ (Mainzer 2008:43-44).
Mit Hilfe Künstlicher und Menschlicher Intelligenz sollte es möglich sein, diese wenigen instabilen Systemelemente zu erkennen (Ordnungsparameter), um makroskopische Muster zu bestimmen.
Der Wahlspruch der Aufklärung lautet: „Habe Mut, Dich Deines eigenen Verstandes zu bedienen!“ Die Aufklärung stellt somit die eigene Wissenskonstruktion in den Mittelpunkt. Was würde also passieren, wenn sich jeder seines eigenen Verstandes bedienen, und sich nicht mehr so abhängig machen würde?
Immerhin ist es den meisten Menschen in Europa heute viel problemloser als früher möglich, seinen eigenen Verstand zu nutzen, doch die meisten machen es einfach nicht. Warum nur? Eine Antwort darauf finden wir schon bei Immanuel Kant, der am Ende des 18. Jahrhunderts folgende Erkenntnis formulierte:
Immanuel Kant schrieb schon 1784 in seiner Streitschrift: „Beantwortung der Frage: Was ist Aufklärung?“: „Unmündigkeit ist das Unvermögen, sich seines Verstandes ohne Leitung eines anderen zu bedienen. Faulheit und Feigheit sind die Ursachen, warum ein so großer Teil erwachsener Menschen, nachdem sie die Natur längst von fremder Leitung freigesprochen hat, dennoch gerne zeitlebens unmündig bleiben, und warum es anderen so leicht wird, sich zu deren Vormündern aufzuwerfen. Es ist so bequem, unmündig zu sein!“ (Fuchs, J.; Stolorz, C. (2001): Produktionsfaktor Intelligenz. Wiesbaden).
In Bezug auf aktuelle geopolitische, gesellschaftliche oder technologische Entwicklungen sehen wir heute, wie falsch es war, dass wir uns in Europa in alle möglichen und unmöglichen Abhängigkeiten begeben haben – es war eben alles so bequem. Dafür haben wir bewusst eine Unmündigkeit in Kauf genommen, die uns jetzt und in Zukunft teuer zu stehen kommt.
Auch bei der oftmals unreflektierten Nutzung der marktführenden KI-Modelle sehen wir wieder eine Entwicklung, die zur Unmündigkeit führt – ist ja alles so bequem. Siehe dazu beispielhaft: Digitale Souveränität: Europa, USA und China im Vergleich.
Alternativ zu den marktführenden KI-Modellen könnte man sich mit den Möglichkeiten von Open Source KI-Modellen befassen, was natürlich unbequemer sein kann, doch andererseits zu mündigen (aufgeklärten) Bürgern führt. In diesem Sinne: Sapere aude!
Stellen Sie sich vor, jemand möchte von Ihnen wissen, wie er Fahrradfahren soll. Geben Sie ihm einfach eine kurze Beschreibung – oder fragen Sie eine Künstliche Intelligenz. Eine eher wissenschaftliche Antwort könnte wie folgt lauten:
„Bringen Sie die Kurvung Ihrer Fahrradspur im Verhältnis zur Wurzel Ihres Ungleichgewichtes geteilt durch das Quadrat Ihrer Geschwindigkeit! Diese Regel beschreibt das Gleichgewichthalten beim Fahrradfahren“ (Fischer 2010).
Könnten Sie aufgrund dieser Beschreibung, möglicherweise ergänzt durch tausende von Videos oder anderen Content, Fahrradfahren? Es wird deutlich, dass zu der Beschreibung noch etwas dazukommen muss: Ein Gefühl für das Gleichgewicht bei einem bestimmten Fahrrad, in einem bestimmten Gelände (Kontext) und Übung, Übung, Übung. So lange, bis man kein Anfänger, sondern ein Experte ist.
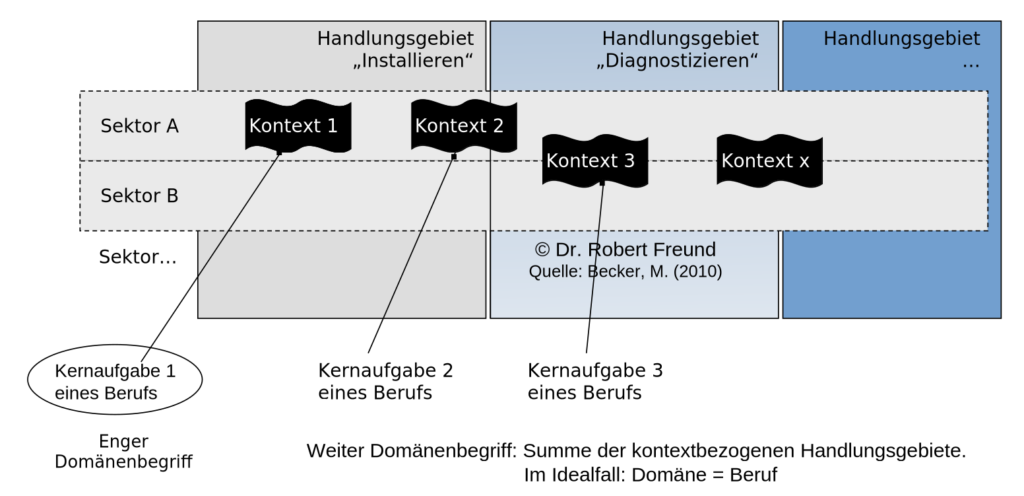
Im beruflichen Umfeld haben wir ähnliche Situationen, die anhand der folgenden Abbildung erläutert werden sollen.
Eigene Darstellung
In der Abbildung sind das Handlungsgebiet „Installieren“, das Handlungsgebiet „Diagnostizieren“ und beispielhaft ein weiteres Handlungsgebiet nebeneinander dargestellt.
Überlagert werden diese von den Sektoren A und B, in denen die Kontexte 1 bis 4 dargestellt sind. Kontext 1 könnte hier die Kernaufgabe 1 eines Berufs, Kontext 2 die Kernaufgabe 2 eines weiteren Berufs etc. darstellen.
Der Domänenbegriff kann sich im engeren Sinne auf eine Kernaufgabe eines Berufs beziehen – hier die Kernaufgabe 1 eines Berufs. Es ist allerdings auch möglich, den Domänenbegriff weiter zu definieren. Dann wären die Summe aller Handlungsgebiete gemeint – im Idealfall stellt eine Domäne den Beruf dar (Domäne=Beruf).
„Die Arbeit in einer Domäne ist stets situiert“ (Becker 2004, S. 36), also an die Problemlösungssituation und den Kontext gebunden, was zu einem sehr speziellen Wissen (Expertenwissen) und der damit verbundenen Expertise (Kompetenz auf Expertenniveau) führt.
Es wird deutlich, dass es nur sehr schwer möglich ist, diese spezielle Kompetenz zu übertragen, gerade dann, wenn man das Ganze der Arbeit betrachtet und nicht nur einzelne Facetten.
Solche Überlegungen können dabei helfen herauszufinden, welche Elemente der Arbeit beispielsweise durch Künstliche Intelligenz ersetzt, ergänzt, oder gar nicht abgebildet werden können.
Der Titel meines Beitrags bezieht sich auf die Philosophin Hannah Arendt, die vor Jahren die Frage stellte, was eine Arbeitsgesellschaft anstelle, der die Arbeit ausgehe (Arendt, H. (1981): Vita activa. Vom tätigen Leben, München),
Dabei ist zunächst einmal zu klären, was unter Arbeit zu verstehen ist, denn auch hier hat sich über die Zeit einiges verändert, was die Abkürzungen Arbeit 1.0, Arbeit 2.0, Arbeit 3.0 und Arbeit 4.0 beschreiben.
Ein wesentlicher Teil des heutigen Arbeitsverständnisses bezieht sich immer noch auf die Sicherung und Erweiterung des Lebensunterhaltes.
„Unter Arbeit verstehen wir die Vielfalt menschlicher Handlungen, deren Zweck die Sicherung und Erweiterung des Lebensunterhaltes der arbeitenden Individuen und ihrer Angehöriger ebenso beinhaltet wie die Reproduktion des gesellschaftlichen Zusammenhanges der Arbeitsteilung und hierüber der Gesellschaft selbst, Arbeit ist vergesellschaftetes Alltagsleben (von Ferber 1991)“ (Peter, G. (1992): Situation-Institution-System als Grundkategorien einer Arbeitsanalyse. In: ARBEIT 1/1992, Auszug aus S. 64-79. In: Meyn, C.; Peter, G. (Hrsg.) (2010)).
Dieses Verständnis von Arbeit kann dem Denken in einer Industriegesellschaft zugeordnet werden. Dazu gehören auch Entlohnungs-Systeme, Sozial-Systeme, Rechts-Systeme, Gesundheits-Systeme, Bildungs-Systeme usw.
Wenn sich also am Verständnis von Arbeit etwas ändert, hat das erhebliche Auswirkungen auf all die genannten, und nicht-genannten, gesellschaftlichen Systeme. Am Beispiel der Landwirtschaft kann das gut nachvollzogen werden: Nachdem hier automatisiert/industrialisiert wurde, gab es zwar weniger Arbeit in dem Bereich, doch mehr Arbeit in einem neuen Bereich, eben der Industrie.
„Arbeit, und zwar das „Ganze der Arbeit“ (Biesecker 2000), sollte deshalb neu bestimmt werden, zunächst verstanden als „gesamtgesellschaftlicher Leistungszusammenhang“ (Kambartel 1993) der Reproduktion, woraus sich spezifische Rechte und Pflichten, Einkommen sowie Entwicklungschancen für die Mitglieder einer Gesellschaft ergeben. Von einem Ende der Arbeitsgesellschaft ist nämlich keine Rede mehr, wohl aber von einem Epochenbruch und der Notwendigkeit einer umfassenden Neugestaltung der gesellschaftlichen Arbeit“ (Peter/Meyn 2010).
Wenn Arbeit nun eher als „gesamtgesellschaftlicher Leistungszusammenhang“ gesehen werden sollte, bedeutet das natürlich, dass die auf dem früheren Begriff der Arbeit basierenden gesellschaftlichen Systeme (Gesundheits-System, Sozial-System Wirtschafts-System usw.) angepasst werden sollten.
Aktuell hat man den Eindruck, dass alle gesellschaftlichen Systeme von den technologischen Entwicklungen getrieben werden, ganz im Sinne von Technology first. Es ist an der Zeit, Prioritäten zu verschieben – und zwar in Richtung Human first. Das ist möglich. Wie? Ein Beispiel:
„By comparison, Society 5.0 is “A human-centred society that balances economic advancement with the resolution of social problems by a system that highly integrates cyberspace and physical space” (Japan Cabinet Office, 2016, zitiert in Nielsen & Brix 2023).
Auch hier geht es um einen menschenzentrierten Ansatz, der allerdings nicht auf den Industriearbeiter begrenzt ist, sondern alle Bürger generell mitnehmen will. Dabei sollen die konkreten Probleme der Menschen (endlich) gelöst werden.
Da gibt es noch viel zu tun. So verstandene Arbeit geht nicht aus, und sollte in allen gesellschaftlichen Bereichen angemessen entlohnt werden.
Diese Website benutzt Cookies. Wenn du die Website weiter nutzt, gehen wir von deinem Einverständnis aus.