Die Nutzung von KI-Modellen ist im privaten und unternehmerischen Umfeld angekommen. Dabei ist es für Kleine und Mittlere Unternehmen (KMU) entscheidend, ob sie sich in die Abhängigkeit der proprietären KI-Modelle begeben, oder mehr Wert auf die eigene Datenhoheit legen. Gerade KMU können es sich nicht leisten, hier knappe Ressourcen zu verschwenden.
Wenn es um Digitale Souveränität geht, und darum, leistungsfähige KI-Modelle mit eigenen oder anderen Daten zu verknüpfen, bietet das MCP-Protocol in der Zwischenzeit sehr spannende Möglichkeiten.
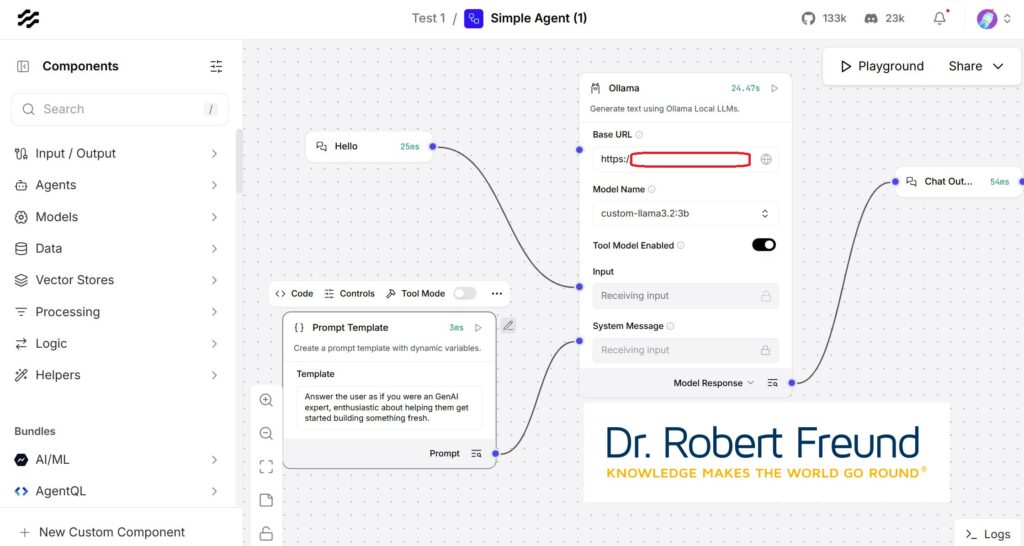
„MCP (Model Context Protocol) is an open standard from Anthropic designed to establish seamless interoperability between LLM applications and external tools, APIs, or data sources“ (Source: Langflow 1.4: Organize Workflows + Connect with MCP).
Wie das beispielsweise mit Langflow möglich ist, habe ich in verschiedenen Blogbeiträgen erläutert. Im Zusammenhang mit Open Source AI bietet das MCP einen Rahmen für ein eigenes, innovatives KI-System, bei dem Sie die Datenhoheit haben.
„Open-Source-Sprachmodelle sind die natürliche Ergänzung zu MCP. Während MCP den sicheren Rahmen vorgibt, liefern Open-Source-Modelle die Freiheit, diesen Rahmen nach eigenen Bedürfnissen zu gestalten“ (Hennekeuser, D. (2026): Model Context Protocol (MCP) und Open-Source-Sprachmodelle: Die Eröffnung neuer souveräner Wege. In Mittelstand Digital Fokus Mensch (2026): Digitale Souveränität als Basis für sichere KI-Anwendungen).
Siehe dazu auch Open Data and Open Source AI – a perfect match.