Ollama ist eine Open Source Software, mit der man kleine und größere Sprachmodelle (Small Language Models und Large Language Models testen kann.
(1) Zunächst natürlich auf Ollama selbst nach einem entsprechenden Login.
(2) Da Ollama Open Source ist, kann es auch auf dem eigenen Server installiert werden. Wie Sie wissen, haben wir das auch schon ausprobiert. Informationen dazu finden Sie in unseren verschiedenen Blogbeiträgen dazu.
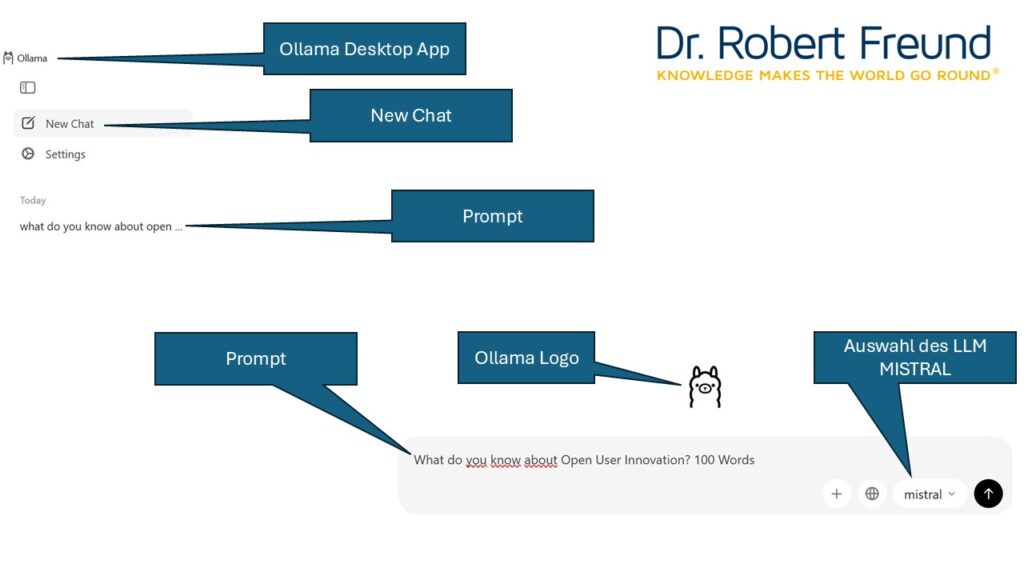
(3) Es ist möglich, Ollama auf dem eigenen Desktop zu installieren und geeignete Modelle zu testen. In den Settings ist der Login bei Ollama zu hinterlegen.
Die Abbildung zeigt den Screenshot mit der Startseite auf meinem Desktop. Wie gewohnt kann ein geeigneter Prompt eingegeben werden.
Spannend ist, dass wir bei jedem neuen Chat aus verschiedenen installierten Modellen auswählen können. Bei dem Beispiel haben wir MISTRAL ausgewählt. Über das „+“-Zeichen können sogar Dateien mit hochgeladen werden.
Auch an der Stelle wird wieder deutlich, wie wichtig es ist, Künstliche Intelligenz mit transparenten Open Source Modellen auf der eigenen Infrastruktur zu betreiben. Ganz im Sinne einer Digitalen Souveränität.
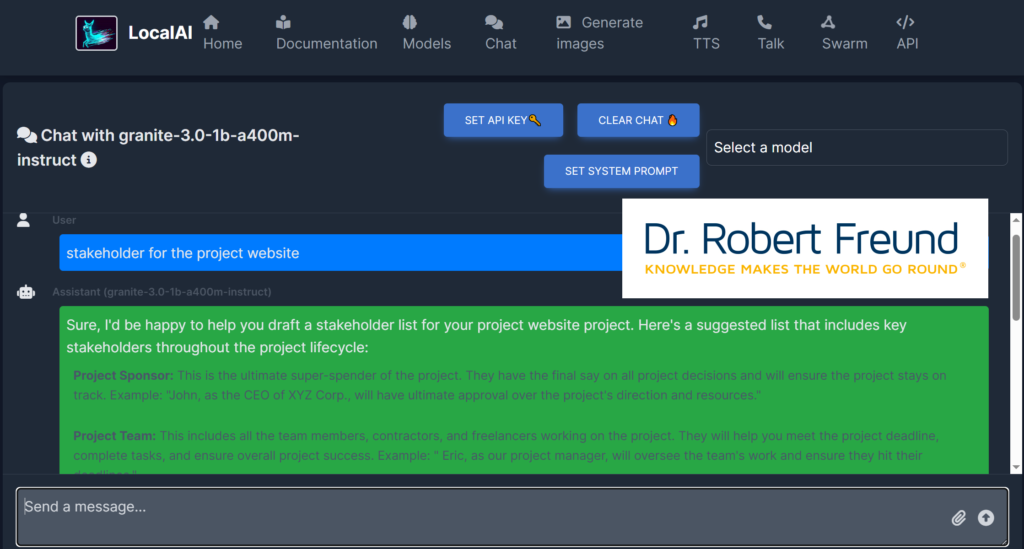
Es war anschließend interessant zu sehen, wie schnell die Antwort über Ollama und MISTRAL erstellt wurde. Auch die Qualität der Antwort war gut. Hier der entsprechende Screenshot: