Ein wichtiges Element, worin sich Künstliche Intelligenz und Menschliche Intelligenz unterscheiden, soll das Bewusstsein sein (Penrose 2025). Schauen wir uns zunächst einmal an, was das menschliche Bewusstsein ausmacht. In einem Artikel von Bahnsen und Schnabel (2012) wird u.a. der Entwicklungspsychologe Tomasello wie folgt zitiert:
„Das menschliche Selbstbewusstsein existiert nicht für sich allein, behauptet Michael Tomasello, Leiter der Abteilung Entwicklungspsychologie. Es ist wesentlich ein Produkt der Interaktion mit anderen“ (ebd.).
Es geht hier um die Interaktion mit und zwischen Menschen – unter weiter:
„Ihr Bewusstsein entsteht durch spezielle und hoch entwickelte Formen sozialer Fähigkeiten bei der Interaktion mit anderen – etwas was Tomasello „kulturelle Intelligenz“ nennt“ (ebd.).
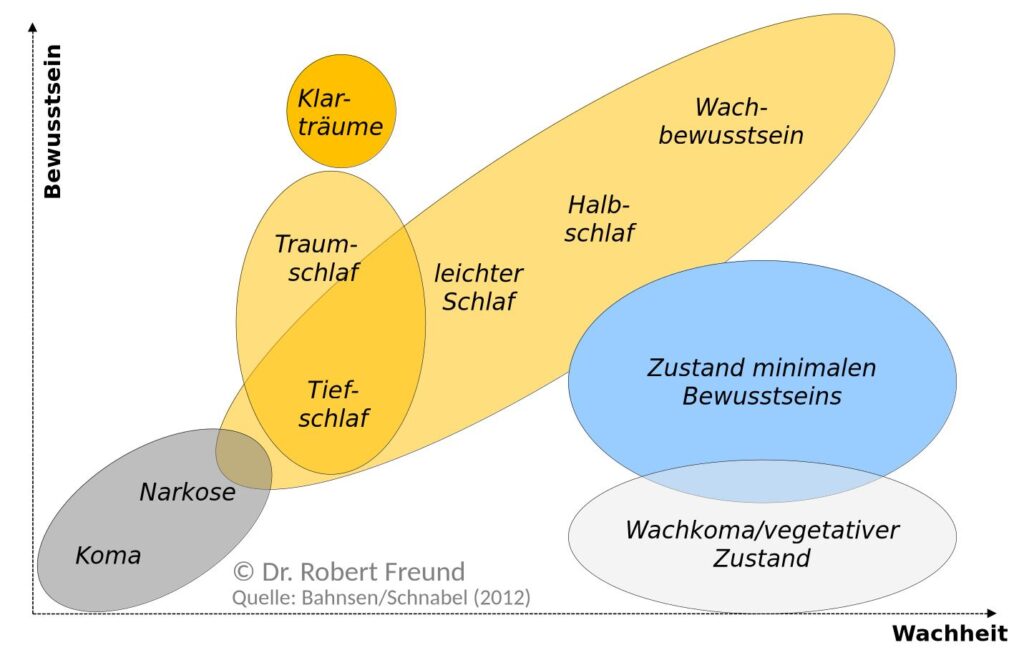
Die vernetzten Interaktionsformen bei Menschen weisen auf eine Dynamik bei dem Bewusstsein hin, die in der Abbildung beispielhaft in Bezug zu Wachheit zu erkennen ist. Da diese Argumente sehr stark auf Menschen bezogen sind, ergibt sich in der Zwischenzeit die Frage, ob auch Künstliche Intelligenz so eine Art von Bewusstsein haben kann.
Nobelpreisträger Sir Roger Penrose hat hier eine deutliche und klare Meinung. Da Künstliche Intelligenz nach seiner Auffassung kein Bewusstsein haben wird, sollten wir nicht von Künstlicher Intelligenz, sondern eher von Künstlicher Cleverness sprechen. Sie dazu Künstliche Cleverness statt Künstliche Intelligenz?
Sir Roger Penrose, Gödel’s theorem debunks the most important AI myth. AI will not be conscious, Interview, YouTube, 22 February 2025. This Is World.
Available at: https://www.youtube.com/watch?v=biUfMZ2dts8
AI will not have conscious – Künstliche Intelligenz wird kein Bewusstsein haben.
In seiner Argumentation verwendet Penrose Gödels Theorem, was als Penrose-Lucas Argument (englisch) durchaus auf Kritik in der Wissenschaftswelt gestoßen ist. Was erwartbar war – so ist eben spannende, lebendige Wissenschaft.