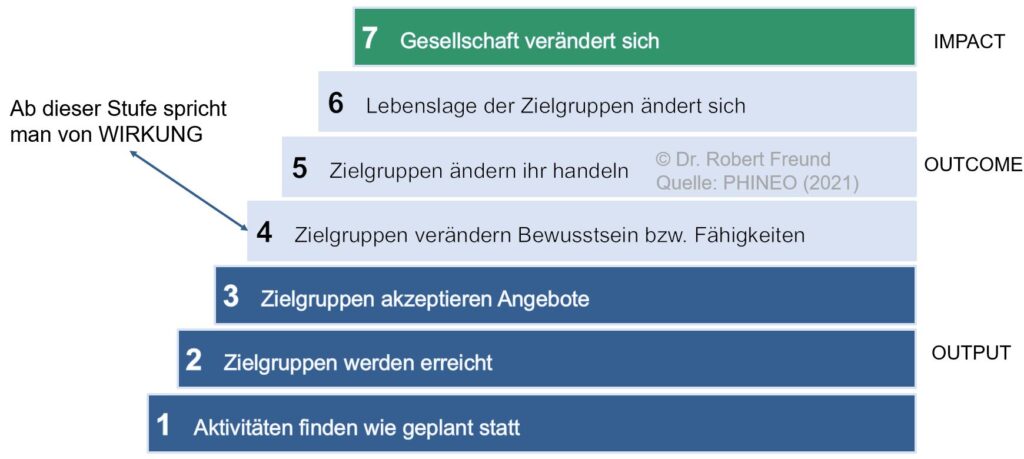
Die Abbildung zeigt zwar die Wirkungstreppe bei Not-for-Profit-Projekten, doch möchte ich daran verschiedene Aspekte der heutigen KI-Diskussion aufzeigen. Wie zu erkennen ist, geht es bei der Entwicklung und Anwendung der verschiedenen KI-Modelle meistens darum, dass sich Künstliche Intelligenz rechnet – die Kosten also niedriger sind als der Nutzen. In den Anfängen der KI-Nutzung sind dazu sehr viele Beispiel veröffentlicht worden die zeigen, wie wirtschaftliche der KI-Einsatz sein kann. In der Zwischenzeit wird allerdings immer öfter auch darüber diskutiert, welche immensen Kosten entstehen können. Siehe dazu auch Wirtschaftlichkeit von KI-Agenten: Warum kommt es bei den Token-Kosten oft zu regelrechten Abrechnungsschocks? Diese Zusammenhänge gehören in die Kategorie Output oder Outcome.
Entscheidender für mich ist allerdings die Frage: Welchen Impact generiert Künstliche Intelligenz? Die großen US amerikanischen Tech-Konzerne wollen die Gesellschaft nach ihren wirtschaftlichen Vorstellungen ändern. Chinesische Modelle wollen das auch, doch haben diese einen anderen, eher politischen Ansatz. Siehe dazu Digitale Souveränität: Europa, USA und China im Vergleich.
Wenn es um Künstliche Intelligenz geht, sollten wir uns zunächst die Frage nach dem Impact stellen, da die KI-Modelle gravierende Auswirkungen auf unsere Gesellschaft haben. Es sollte nicht so sein, dass KI-Unternehmen unsere Daten für ihre Geschäfte nutzen und auch noch bestimmen, welche Werte in der Gesellschaft vertreten werden sollen.
In Europa wird nach und nach erkannt, dass es Zeit ist, europäische Werte als Rahmen für die Nutzung von Künstlicher Intelligenz zu setzen. Solche Grenzen werden die Tech-Konzerne nicht akzeptieren. Sie werden politischen Druck und ihre Lobbyarbeit nutzen, diesen europäischen Ansatz zu verwässern. Ich hoffe, dass die Europäische Union den eingeschlagenen Weg der sinnvollen Regulierung von Künstlicher Intelligenz weitergeht – zum Wohle der Menschen. Siehe dazu auch SuperEurope: The Unexpected Hero of the 21st Century.