Meine Veröffentlichungen sind zum größten Teil auch auf ResearchGate zu finden. Darunter sind eigene Paper/Chapter und auch gemeinsame Veröffentlichungen mit Kollegen.
Thanks to my colleagues and co-authors!
Im Vergleich zum Januar 2023 haben sich die „reads“ bis zum Januar 2025 auf 19.803 erhöht – ein sattes Plus von 4.777.
Nachdem viele europäische und nationale Institutionen erkannt haben, wie abhängig wir in der Europäischen Union von US-amerikanischen und chinesischen Tech-Konzernen geworden sind, gibt es einen starken Trend zur Digitalen Souveränität
Das Zentrum für Digitale Souveränität der Öffentlichen Verwaltung (ZenDiS GmbH) stellt dazu fest, dass der Begriff der Digitalen Souveränität oftmals irreführend verwendet wird, und es sich oftmals eher ein Souveränitäts-Washing handelt.
In einem Whitepaper wurden dazu verschiedene Beispiele genannt, die das illustrieren. Weiterhin wurde auch noch einmal klargestellt, was unter Digitale Souveränität zu verstehen ist.
„Ein Höchstmaß an Digitaler Souveränität bietet eine digitale Lösung dann, wenn sie:
rechtssicher/DSGVO-konform betrieben werden kann (bspw. ohne Zugriff durch ausländische Behörden auf Daten),
Wechselfähigkeit ermöglicht (d. h. kein Vendor-Lock-in besteht),
Kontrolle sichert (auch bei Ausfall, Sperrung oder Wechsel von Dienstleistern),
Transparenz bietet (z. B. durch einsehbaren Quellcode)
und anpassbar und gestaltbar ist (z. B. durch Weiterentwicklung in der Community oder durch Dienstleister).“
Quelle: Zentrum für Digitale Souveränität der Öffentlichen Verwaltung (ZenDiS) GmbH (2025): Souveränitäts-Washing bei Cloud-Diensten erkennen. Warum Digitale Souveränität mehr ist als ein Standortversprechen | Whitepaper (PDF).
Anhand dieser Kriterien kann nun jeder Einzelne, jedes Unternehmen und jede Öffentliche Verwaltung prüfen, ob es sich bei einem Angebot um Digitale Souveränität oder doch eher um Souveränitäts-Washing handelt. Ähnliche Entwicklungen gibt es ja auch beim Green-Washing.
Krieg/Groß/Bauernhansl (2024) (Hrsg.): Einstieg in die Mass Personalization. Perspektiven für Entscheider
Wenn es um den Nutzen, oder den Wert, eines Produktes oder einer Dienstleistung geht, sollten grundsätzlich zwei Punkte beachtet werden.
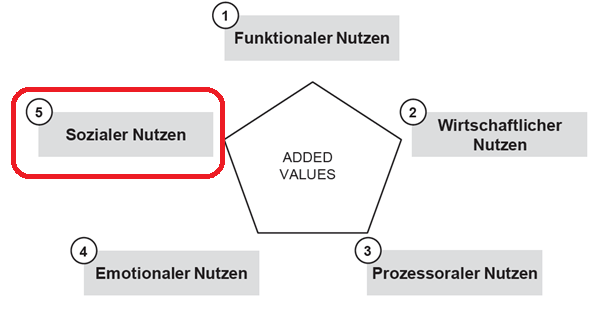
(1) Die verschiedenen Dimensionen von Nutzen (Added Values) In der Abbildung ist zu erkennen, dass Added Values fünf Dimensionen beinhalten. Neben dem funktionalen Nutzen, sind das natürlich der wirtschaftliche Nutzen, ein prozessoraler Nutzen und ein emotionaler Nutzen, Die Dimension, die stärker in den Fokus rücken sollte, ist der soziale Nutzen (eigene Hervorhebung in der Abbildung). Am Beispiel der Anwendung von Künstlichen Intelligenz wird deutlich, dass der Fokus in der aktuellen Diskussion zu sehr auf dem wirtschaftlichen Nutzen liegt, und zu wenig den sozialen Nutzen thematisiert.
(2) Nutzen, Wert und Werte Bei einer ausgewogenen Betrachtung zur Nutzung Künstlicher Intelligenz auf der persönlichen Ebene, auf der Team-Ebene, auf der organisationalen Ebene oder auf gesellschaftlicher Ebene können Werte als Ordner dienen. „Der Begriff »Werte« unterscheidet sich vom Begriff »Wert« dadurch, dass der erste Begriff die Gründe beschreibt, warum etwas für jemanden wichtig ist. Werte repräsentieren normative Grundlagen, die als Leitprinzipien für individuelles Verhalten und gesellschaftliche Strukturen dienen. Sie bilden die Basis für die Bewertung von Wert und beeinflussen die Art und Weise, wie Individuen und Gesellschaften Güter, Dienstleistungen oder Handlungen priorisieren“ (Hämmerle et al. 2025, Fraunhofer HNFIZ).
Darüber hinaus gibt es auch immer mehr leistungsfähige Open Source KI-Modelle, die jedem zur Verfügung stehen, und beispielsweise eher europäischen Werten entsprechen. Siehe dazu auch Das Kontinuum zwischen Closed Source AI und Open Source AI
Wenn also in Zukunft mehr als 1 Milliarde Menschen Künstliche Intelligenz nutzen, stellt sich gleich die Frage, wie Unternehmen damit umgehen. Immerhin war es üblich, dass so eine Art der intelligenten komplexen Problemlösung bisher nur spärlich – und dazu auch noch teuer – zur Verfügung stand.
Nun werden Milliarden von einzelnen Personen die Möglichkeit haben, mit geringen Mitteln komplexe Problemlösungen selbst durchzuführen. Prof. Ethan Mollick nennt dieses Phänomen in einem Blogbeitrag Mass Intelligence.
„The AI companies (whether you believe their commitments to safety or not) seem to be as unable to absorb all of this as the rest of us are. When a billion people have access to advanced AI, we’ve entered what we might call the era of Mass Intelligence. Every institution we have — schools, hospitals, courts, companies, governments — was built for a world where intelligence was scarce and expensive. Now every profession, every institution, every community has to figure out how to thrive with Mass Intelligence“ (Mollick, E. (2025): Mass Intelligence, 25.08.2025).
Ich bin sehr gespannt, ob sich die meisten Menschen an den proprietären großen KI-Modellen der Tech-Konzerne orientieren werden, oder ob es auch einen größeren Trend gibt, sich mit KI-Modellen weniger abhängig zu machen – ganz im Sinne einer Digitalen Souveränität.
Die Lernzieltaxonomie von Bloom et al. aus dem Jahr 1956 wird heute noch in ihrer ursprünglichen Fassung benutzt, obwohl es schon zeitgemäßere Weiterentwicklungen gibt.
Zunächst einmal ist der Vorschlag von Anderson und Krathwohl aus dem Jahr 2001 zu nennen, bei dem die oberste Ebene in Evaluieren umbenannt wurde, und eine weitere Ebene „Erschaffen“ hinzugekommen ist.
Auf Basis dieser Weiterentwicklung hat die Oregon State University 2024 eine englischsprachige Darstellung unter der Lizenz CC BY-NC 4.0 veröffentlicht, die die jeweiligen Ebenen mit den Möglichkeiten der Künstlicher Intelligenz ergänzt.
Das Trendscouting-Team der PHBern hat die gesamte Übersicht ins Deutsche übersetzt (Abbildung).
Alles ist heute mit allem irgendwie vernetzt, sodass auf allen Ebenen Entgrenzung stattfindet, die wiederum zu Komplexität in allen Bereichen einer Gesellschaft führt. Dabei sollten wir die eher „technische“ Komplexität von der sozialen Komplexität unterscheiden.
Es ist in dem Zusammenhang interessant, dass „Geistes- und Sozialwissenschaften besonders gut geeignet sind, (1) die Entwicklung sozialer Komplexität zu beschreiben und (2) das gesellschaftliche Schema, innerhalb dessen die Sinngebung erfolgt, neu zu gestalten“ (Blogbeitrag).
Dabei stellt sich sofort die Frage: Wie kann soziale Komplexität bewältigt werden? Dazu habe ich bei bei John Erpenbeck folgendes gefunden:
„Ein besonderer Anstoß für mich war Hermann Hakens Artikel „Synergetik und Sozialwissenschaften“ in der Zeitschrift Ethik und Sozialwissenschaften (Haken / Wunderlin 2014). Er legte nahe, Werte als – von ihm so genannte – „Ordner“ sozialer Komplexität zu verstehen. Ohne solche Ordner wird Komplexität nicht beherrschbar. Sie sind zugleich zufällig und notwendig. Sie haben ihre Wirklichkeit jedoch nur, wenn sie durch Einzelne verinnerlicht und gelebt werden. Werte sind damit stets Ordner individueller oder kollektiver, physischer oder geistiger menschlicher Selbstorganisation. Kurz: Werte sind Ordner menschlicher Selbstorganisation (Haken 1996). Nicht alle Ordner sind Werte, aber alle Werte sind Ordner im Sinne von Haken (1983)“ (Erpenbeck, J. (2024): Werte als Inseln zeitlicher Stabilität im Fluss selbstorganisierter sozialer Entwicklungen, in Störl (Hrsg.) (2024): Zeit als Existenzform der Materie).
Es wundert daher nicht, dass Werte in allen möglichen Zusammenhängen thematisiert werden. Aktuell geht es beispielsweise bei der Nutzung der Künstlicher Intelligenz darum zu klären, ob wir die Werte der amerikanischen Tech-Konzerne, die Werte der chinesischen Politik oder unsere europäischen Werte als Ordner für soziale Komplexität nutzen wollen.
Klassische Kompetenzentwicklung versteht Kompetenz nach Erpenbeck und Heyse als Selbstorganisationsdisposition, die entwickelt werden kann und sollte. Mit dem Aufkommen von Künstlicher Intelligenz kommt auch immer stärker der Ruf nach einer entsprechenden Kompetenz auf – einer Digitalen Kompetenz oder auch KI-Kompetenz. Dabei sollte unter Künstlicher Intelligenz und Generativer Künstlicher Intelligenz unterschieden werden.
„Der Begriff generativ bedeutet bei künstlicher Intelligenz (KI), dass KI-Systeme aus Eingaben mittels generativer Modelle und gespeicherter Lerndaten neue Ergebnisse/Ausgaben wie Texte, Sprachaussagen, Vertonungen, Bilder oder Videos erzeugen“ (Quelle: Wikipedia).
Es handelt sich bei Generativer Intelligenz (GenAI) also auch um eine Art von Kreativität, die entsteht und die beispielsweise von Menschen bewertet werden kann, bzw. sollte. Es wundert daher nicht, dass vorgeschlagen wird, so eine „evaluative Kreativität“ – und in dem Zusammenhang auch generative Kompetenzen – zu entwickeln:
„Entwickle Deine evaluative Kreativität, entwickle Deine generativen Kompetenzen. (…) Generative Kompetenzen: die Fähigkeit, sich in neuen Technologien kreativ und selbstorganisiert mit einer klaren Wertorientierung zu bewegen“ (Erpenbeck und Sauter 2025).
Bemerkenswert ist hier, dass es nicht nur darum geht, mit KI-Modellen sebstorganisiert umgehen zu können, sondern auch wichtig ist, dass das mit einer klaren Wertorientierung erfolgen soll.
Bei Künstlicher Intelligenz denken aktuell die meisten an die KI-Modelle der großen Tech-Konzerne. ChatGPT, Gemini, Grok etc sind in aller Munde und werden immer stärker auch in Agilen Organisationen eingesetzt. Wie in einem anderen Blogbeitrag erläutert, sind in Agilen Organisationen Werte und Prinzipien mit ihren Hebelwirkungen die Basis für Praktiken, Methoden und Werkzeuge. Dabei beziehen sich viele, wenn es um Werte und Prinzipien geht, auf das Agile Manifest, und auf verschiedene Vorgehensmodelle wie Scrum und Kanban. Schauen wir uns einmal kurz an, was hier jeweils zum Thema genannt wird:
Agiles Manifest:Individuen und Interaktionen mehr als Prozesse und Werkzeuge In der aktuellen Diskussion über die Möglichkeiten von Künstlicher Intelligenz werden die Individuen eher von den technischen Möglichkeiten (Prozesse und Werkzeuge) getrieben, wobei die Interaktion weniger zwischen den Individuen, sondern zwischen Individuum und KI-Modell stattfindet. Siehe dazu auch Mensch und Künstliche Intelligenz: Engineering bottlenecks und die fehlende Mitte.
SCRUM: Die Werte Selbstverpflichtung, Fokus, Offenheit, Respekt und Mut sollen durch das Scrum Team gelebt werden Im Scrum-Guide 2020 wird erläutert, was die Basis des Scrum Frameworks ist. Dazu sind die Werte genannt, die u.a. auch die Offenheit thematisieren, Ich frage mich allerdings, wie das möglich sein soll, wenn das Scrum Team proprietäre KI-Modelle wie ChatGPT, Gemini, Grok etc. nutzt, die sich ja gerade durch ihr geschlossenes System auszeichnen? Siehe dazu auch Das Kontinuum zwischen Closed Source AI und Open Source AI.
KANBANbasiert auf folgenden Werten: Transparenz, Balance, Kooperation, Kundenfokus, Arbeitsfluss, Führung, Verständnis, Vereinbarung und Respekt. Bei den proprietären KI-Modellen ist die hier angesprochene Transparenz kaum vorhanden. Nutzer wissen im Detail nicht, mit welchen Daten das Modell trainiert wurde, oder wie mit eingegebenen Daten umgegangen wird, etc.
Um agile Arbeitsweisen mit Künstlicher Intelligenz zu unterstützen, sollte das KI-Modell den genannten Werten entsprechen. Bei entsprechender Konsequenz, bieten sich also KI-Modelle an, die transparent und offen sind. Genau an dieser Stelle wird deutlich, dass das gerade die KI-Modelle sind, die der Definition einer Open Source AI entsprechen – und davon gibt es in der Zwischenzeit viele. Es wundert mich daher nicht, dass die Open Source Community und die United Nations die gleichen Werte teilen.
In Europa, und gerade in Deutschland, möchten wir, dass der Rechtsstaat weiter existiert und die Gesellschaft nicht nur als Business Case gesehen wird. Der immer größer werdende Einfluss von aktuell Künstlicher Intelligenz auf eine Gesellschaft kann diese überfordern, denn mit jeder Software geht auch eine bestimmte Denkhaltung einher.
Auf solche Entwicklungen macht ein aktueller Kommentar im Handelsblatt aufmerksam. Hier geht es um die Denkwelt des Firmenchefs von Palantir, die man sich mit der Software mit einkauft:
„Palantir passt nicht zum deutschen Rechtsstaat. Das US-Unternehmen mag für Sicherheitsbehörden eine Hilfe sein. Doch die Haltung des Firmenchefs macht die Software zu einem Risiko für die politische Stabilität in Deutschland“ (Kommentar von Dieter Neuerer im Handelsblatt vom 12.12.2025).
Es stellen sich natürlich gleich weitere Fragen, wie z.B.: Stellen die Karten von Google Maps die Realität dar, oder sind „unliebsame“ Gebiete nicht verzeichnet? Enthalten die bekannten proprietäten KI-Modelle (Closed Models) Einschränkungen, die Ergebnisse tendenziell beeinflussen? Siehe dazu auch Künstliche Intelligenz: Würden Sie aus diesem Glas trinken?
Digitale Souveränität fängt damit an, sich von propritärer Software unabhängiger zu machen. Proprietäre Software ist Software, deren Quellcode nicht öffentlich ist, und die Unternehmen gehört (Closed Software). Dazu zählen einerseits die verschiedenen Anwendungen von Microsoft, aber auch die von Google oder ZOHO usw.
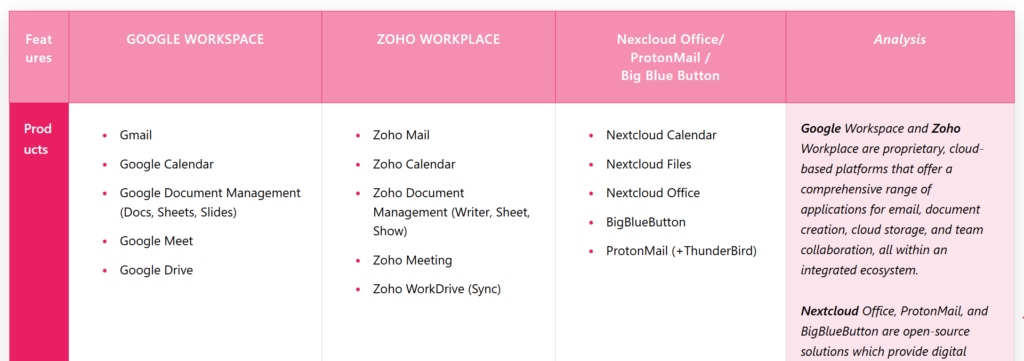
Demgegenüber gibt es in der Zwischenzeit leistungsfähige Open Source Software. Die indische Organisation SFLC hat am 11. November eine Übersicht veröffentlicht, die Google Workplace, ZOHO Workplace und Nextcloud Office/ProtonMail/BigBlueButton gegenüberstellt – die Abbildung zeigt einen Ausschnitt aus der Tabelle, die in diesem Beitrag zu finden ist.
„The purpose of this comparison is to assess the different approaches, features, and trade-offs each solution presents and to help organizations make informed decisions based on their operational requirements, technical capabilities, and priorities around privacy, flexibility, and cost“ (ebd.).
Wir nutzen seit einiger Zeit Nextcloud mit seinen verschiedenen Möglichkeiten, inkl. Nextcloud Talk (Videokonferenzen), sodass BigBlueButton nicht separat erforderlich ist.
Darüber hinaus nutzen wir LocalAI über den Nextcloud Assistenten, haben OpenProject integriert und erweitern diese Möglichkeiten mit Langflow und Ollama, um KI-Agenten zu entwickeln.
Alles basiert auf Open Source Software, die auf unseren Servern laufen, sodass auch alle Daten auf unseren Servern bleiben – ganz im Sinne einer stärkeren Digitalen Souveränität.
Diese Website benutzt Cookies. Wenn du die Website weiter nutzt, gehen wir von deinem Einverständnis aus.