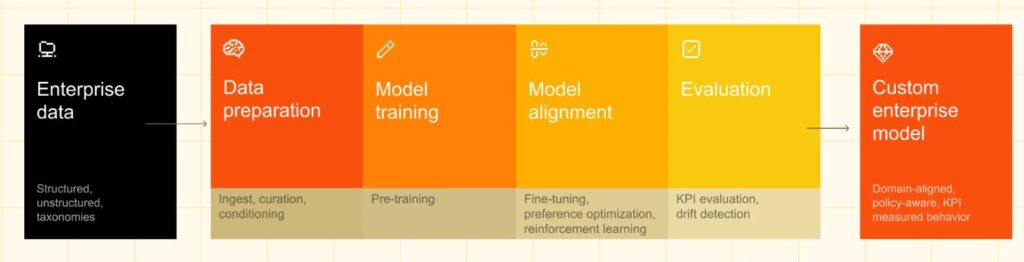
Generative Künstliche Intelligenz (GenKI) ist gerade bei Kleinen und Mittleren Unternehmen (KMU) ein spezielles Thema, da KMU oftmals undermanaged und underfinanced sind. KMU müssen daher beim Einsatz von Künstlicher Intelligenz darauf achten, dass nicht unnötig Ressourcen verschwendet werden. Dazu gehört auch, von Anfang an einen angemessenen Weg zur Nutzung Künstlicher Intelligenz einzuschlagen.
Damit meine ich nicht zu entscheiden, ob man ChatGPT, Gemini, Grok, Anthropic usw. einsetzen möchte, denn diese KI-Modelle (LLM: Large Language Models) sind eher proprietäre LLM, also herstellergebundene KI-Modelle mit Vor- und Nachteilen.
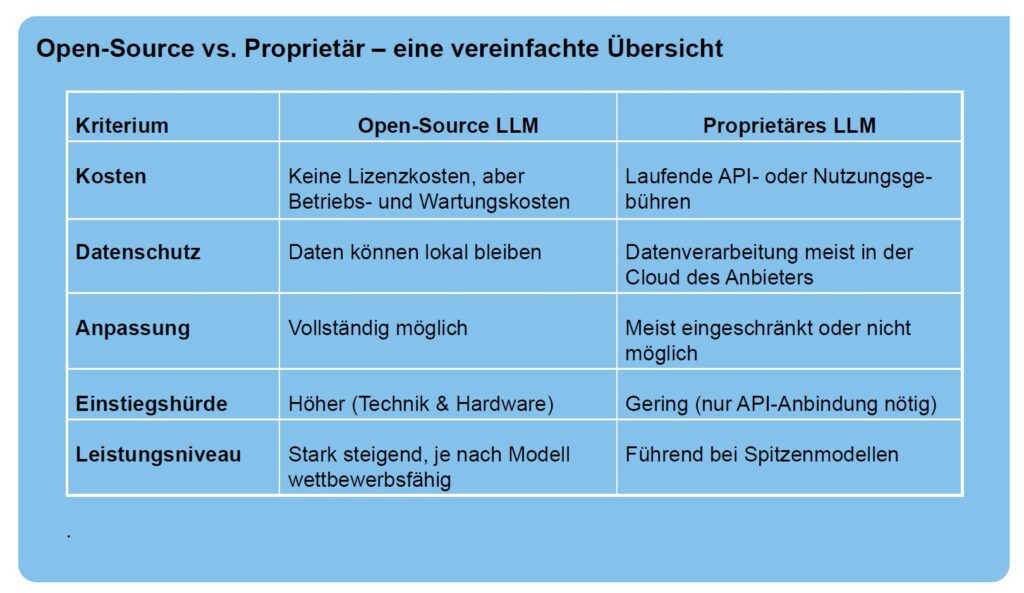
Die Abbildung zeigt dazu eine einfache Gegenüberstellung von Open Source LLM und proprietärer LLM. Es wird deutlich, dass die Einstiegshürden bei Open Source LLM zwar höher sind, doch die Open Source LLM bei Kosten, Datenschutz und Anpassung besser abschneiden. Was noch beobachtet werden muss, ist das jeweilige Leistungsniveau, das sich bei den Open Source LLM in den letzten Jahren stark verbessert hat.
Vor zwei Jahren dominierten proprietäre Modelle den Markt. Inzwischen hat sich viel getan. Beispiele sind Meta LLaMA 3, Mistral & Mixtral, Falcon, Gemma, OpenHermes und Ökosystem-Tools (Plattformen wie HuggingFace).
Kurz gesagt: Open-Source LLMs sind nicht mehr nur Forschungsprojekte, sondern in vielen Szenarien produktionsreif.
Quelle: vgl. Mittelstand Digital Fokus Mensch (2026): Digitale Souveränität als Basis für sichere KI-Anwendungen. EIN KURZLEHRBUCH | PDF
Gerade für Kleine und Mittlere Unternehmen (KMU) ist es an der Zeit, auf Basis von Open Source AI ihre eigene Digitale Souveränität aufzubauen. Mit dem genannte Handbuch können Sie sich ausführlicher darüber informieren und anfangen, entsprechende Kompetenzen aufzubauen.