OpenProject ist schon lange eine Alternative zu den proprietären Projektmanagement-Tools wie MS Project oder Jira etc. Die Integration von OpenProject in Nextcloud führt zu einer Kollaborationsplattform, bei der alle Daten auf dem eigenen Server bleiben und alle Anwendungen Open Source basiert sind. Siehe dazu unsere verschiedenen Blogbeiträge zu OpenProject.
Mit der Integration von OpenProject mit Nextcloud (Alternative zu Microsoft Sharepoint), inkl. TALK als Videokonferenzsystem (Alternative zu Microsoft Teams) etc. wurde schon ein wesentlicher Schritt in Richtung Digitale Souveränität am Arbeitsplatz gemacht.
Bei der Version OpenProject 17.2 gibt es eine Weiterentwicklung die es ermöglicht, Künstliche Intelligenz (Large Language Models oder Small Language Models) über einen sicheren MCP Server in die eigenen Projekte einzubinden.
MCP (Model Context Protocol) ist ein offener Standard von Anthropic über den LLM und externe Tools via APIs oder eigene Datenquellen eingebunden werden können.
Wie Sie wissen, schlagen wir in unseren Blogbeiträgen immer vor, Open Source AI und Open Source Software zu verwenden – möglichst auf dem eigenen Server. Dann bleiben alle Daten bei Ihnen und werden nicht von anderen genutzt – ganz im Sinne der Digitalen Souveränität.
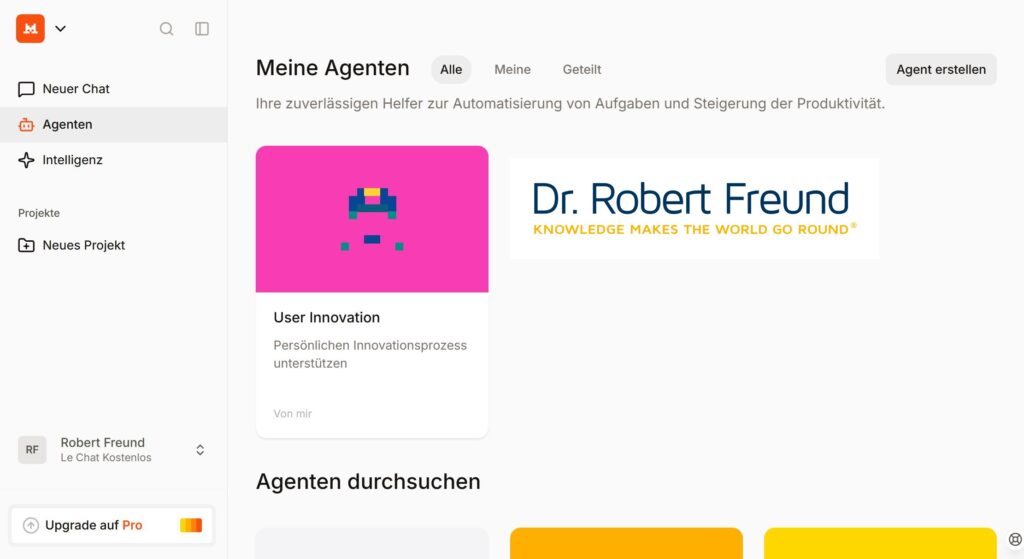
Im nächsten Schritt habe ich mich bei Mistral Le Chat angemeldet, wodurch weitere Optionen kostenlos zur Verfügung stehen. Darunter ist auch die Möglichkeit, Agenten zu nutzen. Die obere Abbildung zeigt einen Screenshot, mit einem von mir angelegten Agenten „User Innovation„.
Das Ziel des Agenten ist es, meinen persönlichen Innovationsprozess zu unterstützen. Dabei möchte ich (natürlich) Open Source AI und frei verfügbare Daten nutzen.
Die folgende Grafik zeigt einen Ausschnitt aus den generierten Abfragen. Ich muss zugeben, dass ich durchaus von der Qualität der Antworten überzeugt bin. Mal sehen, wie weit ich mit meinen Überlegungen und Le Chat komme.
Eigener Screenshot – Mistral Le Chat, angemeldet, Agent anlegen
Wenn es um Künstliche Intelligenz geht, wird oft über die KI-Modelle, die technische und organisatorische Infrastruktur, oder auch über Regulation oder Talent (Kompetenzen) gesprochen.
Diese Punkte sollen helfen, KI-Systeme zu skalieren und dadurch besser und profitabler zu machen. Wenn es um die Skalierung von KI-Systemen geht, hat sich allerdings ein ganz anderer Bereich als Barriere entpuppt: Das Lernen.
„The core barrier to scaling is not infrastructure, regulation, or talent. It is learning. Most GenAI systems do not retain feedback, adapt to context, or improve over time“ (MIT NANDA 2025).
Die hier angesprochene Kritik richtet sich also darauf, dass die meisten GenAI Systeme kein Feedback speichern, sich nicht dem Kontext anpassen und sich nicht im Laufe der Zeit verbessern.
Natürlich gibt es GenAI-Systeme, die ein Feedback anbieten, doch geben nicht alle Nutzer ihr Feedback zu den Antworten, obwohl es manchmal ganz einfach mit „Daumen hoch“ oder „Daumen runter“ möglich ist.
Die Anpassung an den Kontext ist da schon für GenAI schwieriger, das es für das spezielle Erfahrungswissen (Expertise) viel mehr benötigt, als das, was GenAI aktuell anbietet. An diesen Stellen kommt der Mensch ins Spiel. Siehe dazu Rent a Human: KI-Agenten bieten Arbeit für Menschen an.
Natürlich verbessern sich die GenAI Systeme über die Zeit. Das machen sie, aufgrund ihrer vorliegenden Daten auch selbständig, selbstorganisiert, autopoietisch. GenAI-Systeme verbessern sich allerdings nur so lange selbst, bis ihr System infrage gestellt wird – dann ist Schluss. Allerdings sind die Daten, auf denen die Verbesserung basiert nicht so vollständig. Das wiederum bedeutet möglicherweise, dass auch die Verbesserung nicht optimal ist.
Wenn also Lernen der Flaschenhals beim Skalieren von GenAI ist, sollte sich jeder mit Lernen befassen. Ich bezweifle allerdings, dass diejenigen, die sich mit KI-Systemen und deren Nutzung in Organisationen befassen, etwas von Lernen verstehen. Siehe dazu auch
Es ist schon erstaunlich, was man alles mit Künstlicher Intelligenz (GenAI) machen kann. Der Schwerpunkt scheint aktuell darauf zu liegen, in Organisationen die Abläufe zu verbessern, um die Produktivität zu erhöhen.
Weiterhin werden die KI-Modelle immer intuitiver und einfacher, was die Anwendung von KI scheinbar immer leichter macht.
Eine aktuelle Studie (Liu et al. 2026) kommt allerdings zu dem Schluss, dass, je leichter KI (GenAI) angewendet werden kann, umso wichtiger ist der Mensch, der die „harte Arbeit“ erledigen muss.
„The uncomfortable truth: the easier AI gets, the more valuable the people who still do the hard work become — and the more urgently organisations need to protect the conditions that produce them“ (Liu et al 2026).
Weiterhin wird in der selben Studie auf den Zusammenhang zwischen der Produktivität bei der Nutzung von KI und Innovation durch KI eingegangen: Die Produktivität steigt, doch Innovation (das Innovations-Niveau) stagniert.
Das liegt laut Studie an den „good enough“ – Antworten der üblichen KI-Modelle, die zu wenig „Friktion“ bieten, um Innovationen zu pushen.
Wenn alles zu einfach und zu leicht ist, kann das dann jeder und es ist nichts Neues mehr im Sinne einer Innovation. Die Autoren empfehlen daher ein angemessenes Maß an Friktion in der Organisation zu etablieren. Dazu wurde auch ein erstes geeignetes Framework entwickelt.
Auf die neue Mistral 3 KI-Modell-Familie hatte ich schon im Dezember 2025 in einem Blogbeitrag hingewiesen. Das französische Start-Up wurde 2023 gegründet: „(…) the company’s mission of democratizing artificial intelligence through open-source, efficient, and innovative AI models, products, and solutions“ (Quelle: Website).
Dieses Demokratisieren von Künstlicher Intelligenz durch Open Source, als europäischer und DSGVO-konformer Ansatz, ist genau der Weg, den ich schon in verschiedenen Beiträgen vertreten habe. Es ist daher interessant, auch den in 2024 veröffentlichten Bot Le Chat im Vergleich beispielsweise zu ChatGPT zu testen.
Die Abbildung weiter oben zeigt die Landingpage für Le Chat mit einem einfachen Feld für die Eingabe eines Prompts. Man kann die Leistungsfähigkeit des Bots testen, ohne sich anmelden zu müssen. Ich habe mich also zunächst nicht angemeldet und einfach einmal eine Frage eingegeben, die mich aktuell beschäftigt: Es geht um die Unterschiede zwischen den Auffassungen von Henry Chesbrough und Eric von Hippel zu Open Innovation.
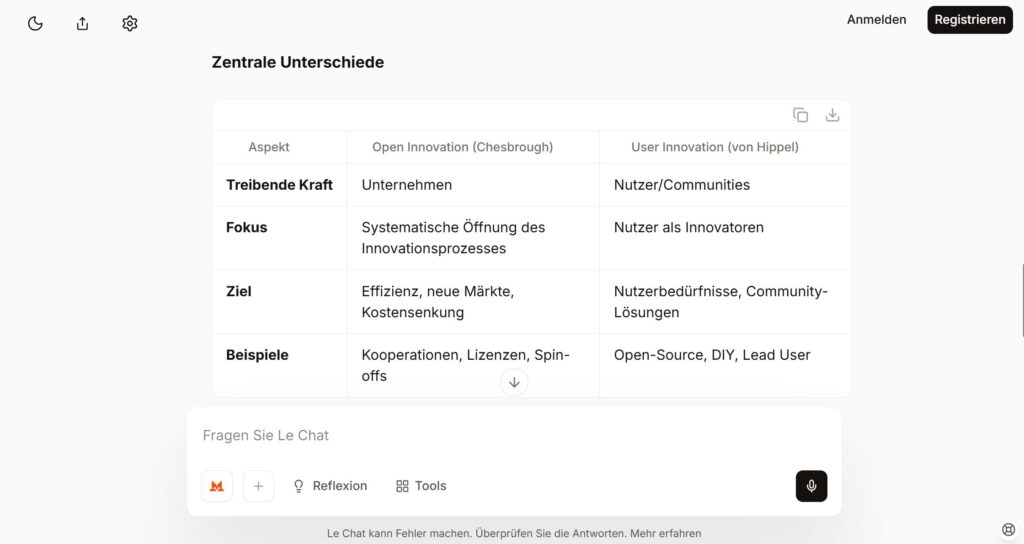
Ausschnitt aus der Antwort zum eingegebenen Prompt
Die Abbildung zeigt einen Ausschnitt aus der umfangreichen Antwort auf meine Frage, inkl. der generierten Gegenüberstellung der beiden Ansichten auf Open Innovation. Die Antwort kam sehr schnell und war qualitativ gut – auch im Vergleich zu ChatGPT.
Mistral Le Chat ist ein europäisches Produkt, das auch der DSGVO unterliegt und darüber hinaus neben französisch- und englischsprachigen, auch mit deutschsprachigen Daten trainiert wurde. Es ist spannend, sich mit den Mistral-KI-Modellen und mit Le Chat intensiver zu befassen.
Wir haben den kostenpflichtigen ChatGPT-Account in der Zwischenzeit gekündigt, und werden mehr auf Modell-Familien wie Mistral 3 und MistralLe Chat setzen. Wir sind gespannt, wie sich die Open Source Alternativen in Zukunft weiterentwickeln – ganz im Sinne einer Digitalen Souveränität. Siehe dazu auch
Im Netz sind auch Personen unterwegs, deren Identität nicht bekannt ist. Für manche ist es der Schutz ihrer persönlichen Privatsphäre, für andere bietet Anonymität im Netz die Möglichkeit, Beiträge zu verfassen, die andere diffamieren.
Forscher von der ETH Zürich, MATS Research und Anthropic sind einmal der Frage nachgegangen, ob es mit den Möglichkeiten der Künstlichen Intelligenz in großem Maßstab möglich ist, zu de-anonymisieren. In dem Paper von Lermen et al. (2026) wurde die Vorgehensweise und die Ergebnisse ausführlich dargestellt.
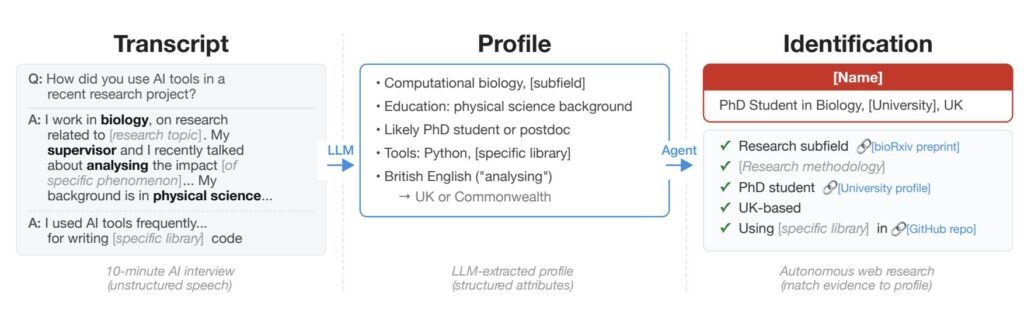
Die Abbildung zeigt, wie aus einem einzelnen Interview mit Hilfe eines Large Language Models (LLM) ein Profil erstellt wurde, und abschließend ein KI-Agent die Person identifizieren konnte.
„End-to-end deanonymization from a single interview transcript from (details altered to protect the subject’s identity). An LLM agent extracts structured identity signals from a conversation, autonomously searches the web to identify a candidate individual, and verifies the candidate matches all extracted claims“ (Lermen et al. (2026): Large-scale online deanonymization with LLMs | PDF).
Die technischen Möglichkeiten haben nun zwei Effekte: (1) Anonyme Nutzer im Netz, die sich strafbar machen, können identifiziert werden. (2) Für Nutzer, die ihre Anonymität aus den verschiedenen Gründen wahren möchten, reicht ein Pseudonym im Netz in Zukunft wohl nicht mehr aus.
Dass es erforderlich ist, sich als Privatperson, Unternehmen, gemeinnützige Organisation oder staatliche Verwaltung digital unabhängiger von amerikanischen (oder auch chinesischen) Anbietern zu machen, ist so langsam aber sicher allen klar geworden.
Der erste Schritt ist, sich von Microsoft Office 365 oder auch Google Workplace unabhängiger zu machen. Dafür gibt es in der Zwischenzeit viele Möglichkeiten, die beispielsweise auf Nextcloud Hub basieren. Wie Sie als Leser unseres Blogs wissen, haben wir diesen Schritt schon vor vielen Jahren eingeleitet, und Nextcloud auf unseren eigenen Servern installiert. Bitte schauen Sie sich dazu meine Blogbeiträge zu Nextcloud an.
Parallel dazu bieten auch andere Anbieter Nextcloud Hub als Service an – beispielsweise auch ein Unternehmen aus Den Haag, das Office.EU als europäische Plattform anbietet:
„Office EU is a complete cloud-based office suite (like Microsoft 365 or Google Workspace) that is 100% European-owned and runs entirely on European infrastructure. Office EU includes all the essential productivity apps for documents, spreadsheets, presentations, file storage, email, calendars, and video meetings“ (Website).
Der nächste Schritt ist dann, Künstliche Intelligenz in Nextcloud zu integrieren. Wir haben auf unserer Installation gezeigt, dass LocalAI in Nextcloud integriert, und Open Source basierte KI-Modelle eingebunden werden können – wichtige Schritte in Richtung Digitale Souveränität.
Die Frage in meiner Blogüberschrift erscheint auf den ersten Blick etwas seltsam. Immerhin kommunizieren wir als Menschen doch permanent, oder? Schauen wir uns Kommunikation noch etwas genauer an, so ist die Frage gar nicht so leicht zu beantworten.
Bei Kommunikation geht es um den“ Austausch oder die Übertragung von Informationen“(Wikipedia). Dabei gibt es viele Facetten. die vom einfachen Sender-Empfänger-Modell, über die verschiedenen Ebenen von menschlicher und digitaler Kommunikation, bis hin zur Einordnung von Kommunikation in komplexen sozialen Systemen reichen.
Bei der Systembetrachtung gibt es Ansichten (z.B. von Luhmann), die der allgemeinen Auffassung von Kommunikation widersprechen. Die Systemtheorie von Niklas Luhmann geht zunächst einmal von der Kommunikation (nicht von Handlungen) aus und davon, dass „die Strukturen der Kommunikation in weitgehend allen sozialen Systemen vergleichbare Formen aufweisen“ (ebd.). Kommunikation ist also, so Luhmann, kein Ergebnis menschlichen Handelns, sondern ein Produkt sozialer Systeme (vgl. Dewe 2010).
Das gipfelt in der Aussage: „Der Mensch kann nicht kommunizieren, nur die Kommunikation kann kommunizieren“ (Krieger / Nassehi 1993:56).
Soziale Systeme tauschen also Informationen selbstreferentiell aus – sie kommunizieren, ohne dass der Mensch dafür erforderlich ist.
Der Mensch ist nach Luhmann konsequenterweise kein Bestandteil der sozialen Systeme, sondern Bestandteil der Umwelt. Die System-Umwelt-Kopplung macht die Kommunikation möglich. Wie am Anfang schon angedeutet, sind die Zusammenhänge nicht so einfach zu verstehen. Siehe dazu auch Künstliche Intelligenz: System – Umwelt – Mensch.
Top view of multiracial young creative people in modern office. Group of young business people are working together with laptop, tablet, smart phone, notebook. Successful hipster team in coworking. Freelancers.
KI-Modelle sind auch Systeme, die selbstorganisiert, autopoietisch agieren. Es wundert daher nicht, dass bei der Beschreibung von KI-Systemen die üblichen Begriffe aus der Systemtheorie verwendet werden. Doch schauen wir uns einmal an, was beispielsweise mit dem Begriff Autopoiesis ursprünglich gemeint war.
„Das Kunstwort Autopoiesis, das sich aus den griechischen Worten autos (selbst) und poiein (=machen) zusammensetzt, wurde übrigens von Maturana selbst geprägt und meint so viel wie Selbsterzeugung, Selbstherstellung. Maturana und Varela haben den Begriff benutzt, um die Eigenart der Organisation von Lebewesen zu beschreiben. Es geht ihnen um die Definition bzw. Theorie des Lebendigen“ (Maturana / Varela 1992:50f.), zitiert in Dewe 2010).
Es wundert nicht, dass Maturana und Varela als Biologen damit etwas Lebendiges im Sinn hatten.
Weiterhin sind autopoietische Systeme nicht nur selbstbezogen, und selbstherstellend, sondern auch selbstbegrenzend (vgl. dazu W. Krohn und G. Küppers (Hrsg.): Emergenz: Der Entstehung von Ordnung, Organisation und Bedeutung. Frankfurt am Main 1992, S. 394).
Damit ist man bei der Beziehung System – Umwelt. „Das System bezieht jedoch nichts Vorgefertigtes aus der Umwelt, sondern es schafft sich durch interne Unterscheidungen seine bestimmte Umweltsensibilität. (…) Das System verändert sich, indem es seine Strukturen verändert – es lernt. Es verändert sich, wie bereits beschrieben, nicht unendlich, sondern nur so lange, wie es die eigene Autopoiesis nicht gefährdet“ (Dewe 2010).
Ein KI-System lernt somit nur so lange, wie die eigene Autopoiese nicht gefährdet ist.
Welche Rolle spielt der Mensch in Bezug auf System und Umwelt?
Wenn sich alles selbstorganisiert und selbstbegrenzend entwickelt, stellt sich die Frage, ob der Mensch Bestandteil des (sozialen) Systems ist, oder eher zur Umwelt zählt.
„Das Herauslagern des Menschen aus dem sozialen System in die Umwelt des Systems (in Form des psychischen Systems) verringert nicht die Bedeutung des Menschen, sondern verstärkt und unterstreicht ihn, denn wäre der Mensch mit Haut und Haaren Bestandteil des Systems dann handelte es sich um ein totalitäres System. Wird der Mensch aber herausgenommen, so schützt gerade dies seine Autonomie und Eigenständigkeit“ (Dewe 2010).
Wenn wir uns die KI-Modelle ansehen, so ist deren Ziel, den Menschen mit seinen Daten und Profilen im System abzubilden. Der Mensch wird somit immer mehr zum Bestandteil des KI-Systems.
Das bedeutet wiederum, ein KI-System kann in diesem Sinne immer mehr zu einem totalitäres System werden.
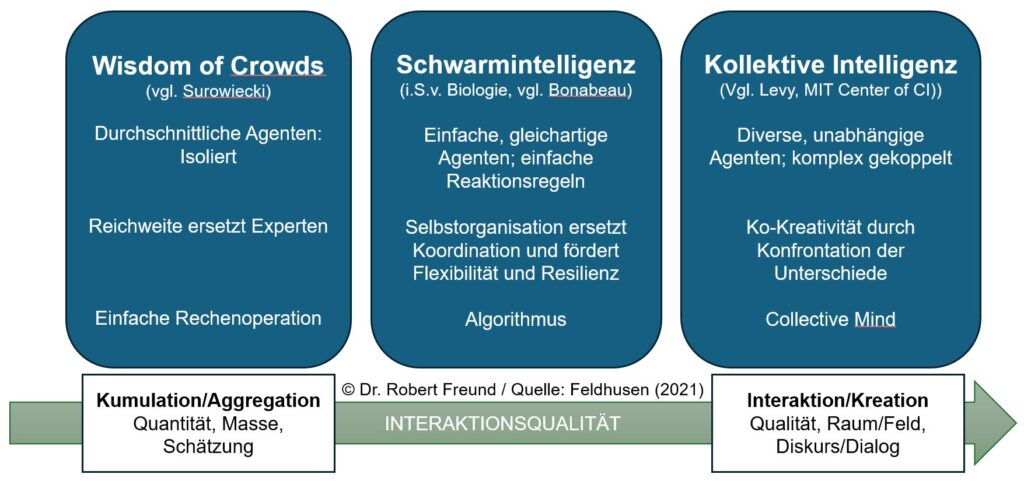
In dem Blogbeitrag Wisdom of Crowds – Schwarm Intelligenz – Kollektive Intelligenz bin ich schon einmal intensiver auf die Unterscheidung der jeweiligen Ansätze eingegangen. Darin zitiere ich Feldhusen (2021), der sich wiederum auf Lévy vom MIT Center of Collective Intelligence bezieht. Es lohnt sich, dessen Auffassung noch etwas genauer zu betrachten:
„Die Netzwerkgesellschaft wird nicht von einer Expertenintelligenz getragen, die für andere denkt, sondern von einer kollektiven Intelligenz, die die Mittel erhalten hat, sich auszudrücken. Der Anthropologe des Cyberspace, Pierre Lévy, hat sie untersucht: »Was ist kollektive Intelligenz? Es ist eine Intelligenz, die überall verteilt ist, sich ununterbrochen ihren Wert schafft, in Echtzeit koordiniert wird und Kompetenzen effektiv mobilisieren kann. Dazu kommt ein wesentlicher Aspekt: Grundlage und Ziel der kollektiven Intelligenz ist gegenseitige Anerkennung und Bereicherung …« (Lévy, 1997, S. 29). Um allen Missverständnissen zuvor zu kommen, richtet er sich ausdrücklich gegen einen Kollektivismus nach dem Bild des Ameisenstaates. Vielmehr geht es ihm um eine Mikrovernetzung des Subjektiven. »Es geht um den aktiven Ausdruck von Singularitäten, um die systematische Förderung von Kreativität und Kompetenz, um die Verwandlung von Unterschiedlichkeit in Gemeinschaftsfähigkeit« (ebd., S. 66)“ (zitiert in Grassmuck 2004).
L ÉVY, PIERRE (1997): Die Kollektive Intelligenz. Eine Anthropologie des Cyberspace, Bollmann Verlag, Mannheim.
In der Grafik ist zu erkennen, dass es bei Kollektiver Intelligenz auch um diverse, unabhängige Agenten geht, die komplex gekoppelt sind. Aus der heutigen Perspektive können damit auch KI-Agenten im Netzwerk diverser Akteure gemeint sein. Auch in so einem Netzwerk würde es also nicht DIE Expertenintelligenz geben. Intelligenz (menschliche, künstliche, hybride Formen) würde sich also im Netzwerk verteilt, immer wieder neu bilden.
Um das zu erreichen, müssen allerdings Voraussetzungen erfüllt sein, die von den Tech-Konzernen mit ihren KI-Agenten manchmal „vergessen“ werden. Grundlage und Ziel der Kollektiven Intelligenz sind nach Lévy „gegenseitige Anerkennung und Bereicherung“. Bei diesen Punkten habe ich bei den proprietären KI-Modellen so meine Zweifel.
Diese Website benutzt Cookies. Wenn du die Website weiter nutzt, gehen wir von deinem Einverständnis aus.