Beispielhaft sollen hier nur einige wenige KI-Modelle genannt werden, die sich auf europäische Sprachen konzentrieren: TEUKEN 7B (Alle europaischen Sprachen), EURO LLM (Alle europäischen Sprachen), MINERVA AI LLM (Italienisch), PLLuM (Polnisch), RAKA 4B (Ungarisch), GPT-SW3 (Schwedisch), ALIA (Spanisch).
Nun kommt mit AMALIA (Agente Multimodal Automático de Linguagem com IA) ein weiteres Open Source KI-Modell hinzu, das mit den Besonderheiten der portugiesischen Sprache trainiert wurde, und frei zur Verfügung steht. Auf der Website werden folgende Ziele formuliert:
Förderung der portugiesischen Sprache
Souveränität über die Daten der Bürger
Die kulturelle Repräsentation Portugals bewahren
Förderung von Forschung und Innovation im Bereich der Künstlichen Intelligenz
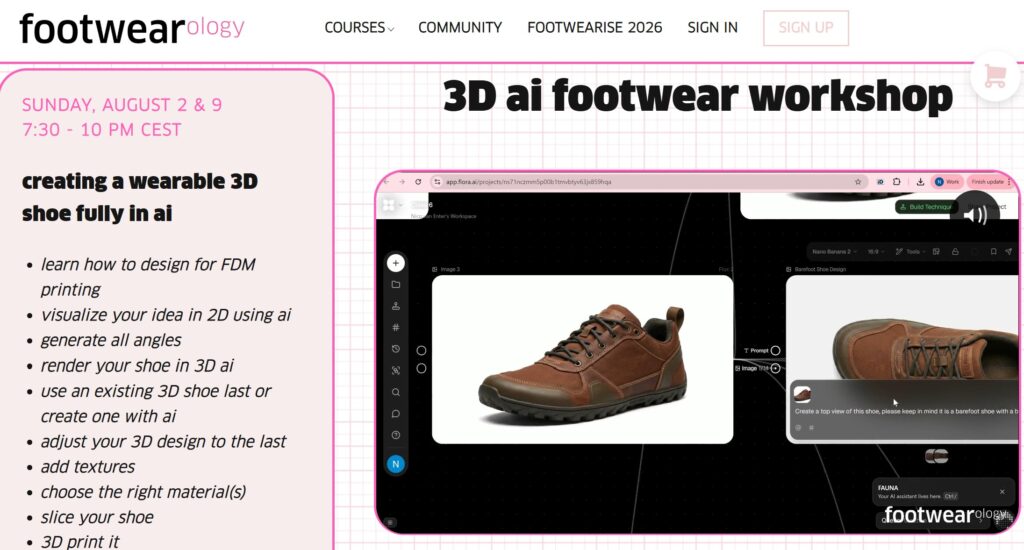
Auf der Seite footwareology wird ein zweitägiger Online-Workshop für 75€ angeboten, in dem mit Unterstützung von Experten gezeigt wird, wie man selbst eigene Schuhe entwickeln und herstellen kann (Customization).
Die Unterstützung ist erforderlich, da es in dem komplexen Prozess immer wieder kleine Hürden gibt, die zu bewältigen sind. Vor dem Workshop sind einige Programme zu installieren, die auf der Website angegeben werden.
Insgesamt finde ich es spannend zu sehen, dass es immer mehr Möglichkeiten gibt, sein eigenes Produkt, seine eigenen Schuhe nicht nur zu entwickeln, sondern auch mit modernen technologischen Möglichkeiten herzustellen.
Dennoch halte ich es für zukunftsfähiger, wenn der gesamte Prozesses – nicht nur einzelne Elemente – zur Herstellung seiner eigenen Schuhe von Künstlicher Intelligenz unterstützt wird. Wir empfehlen dafür natürlich Open Source AI, wie z.B. Mistral 7b (open weight) und Open Source Software.
Diese beiden Punkte heben den Entwicklungs- und Herstellungsprozess auf ein neues Niveau.
Auf der internationalen Konferenz MCP 2026 (16.-19.09.2026, Balatonfüred, Ungarn) gehe ich darauf ein:
Open-Source AI for Open User Innovation: Designing a Personal Fabrication Framework
Mein zweites Paper:
Digital Sovereignty and Open-Source AI: The European Way for Innovative SMEs
Herauszufinden, welche Präferenzen (Vorlieben, Neigungen) ein Nutzer üblicherweise hat, ist für Unternehmen wichtig. Es wird aus diesen Präferenzen oft interpretiert, welche Produkte und Dienstleistungen den Nutzer möglicherweise auch noch interessieren könnten. Die im 20. Jahrhundert entstandenen philosophischen und ökonomischen Theorien hatten dabei das Ziel, Präferenzen möglichst zu befriedigen. In den Anfängen solcher Überlegungen wurden zwei Präferenzen unterschieden:
„From these early theories emerges the distinction between revealed preferences and ideal preferences (Samuelson, 1948). Revealed preferences refer to how people’s desires are acted upon in real life through the choices they make (Samuelson, 1948). Ideal preferences refer to people’s desires that would manifest if they were rational and informed in an ideal world (Samuelson, 1948). This distinction importantly points to the idea that people’s actions may or may not reflect their actual desires“ (Li, J. (2026) Beyond Preference-based Value-alignment, IEAI Research Brief – Q2 2026).
Das Konzept der Präferenzen wurde auf Methoden zur Werteausrichtung (Value Alignment) ausgeweitet, bei denen der Schwerpunkt darauf liegt, Informationen beispielsweise über das bevorzugte Verhalten von KI-Systemen anhand offenbarter Präferenzen zu extrapolieren.
An dieser Stelle stellt sich allerdings die Frage, ob sich das KI-Modell an die Präferenzen und Werte des Nutzers anpasst, oder ob nicht das KI-Modell den Nutzer so beeinflussen will, dass er die in dem KI-Modell hinterlegten Werte adaptiert. Da die Werte der proprietären KI-Modelle oft nicht transparent sind, kann es daher zu unerwünschten Manipulationen kommen. Siehe dazu auch
Speech bubbles, blank boards and signs held by voters with freedom of democracy and opinion. The review, say and voice of people in public news adds good comments to a diverse group.
In dem Beitrag Künstliche Intelligenz und die Kompetenz-Illusion habe ich ausführlich dargestellt, dass es bei der Frage zur Kompetenzentwicklung für die Nutzung Künstlicher Intelligenz nicht alleine darauf ankommen kann, dass sich alle Privatpersonen, Mitarbeiter in Organisationen und ganze Öffentliche Verwaltungen an die proprietären KI-Modelle wie ChatGPT, Gemini, Grok, Claude etc. anpassen.
Dabei werden die Menschen auf die Nutzung der KI-Systeme trainiert, und teilweise auch manipuliert. Eine so verstandene Kompetenzentwicklung ist zu eng definiert und zu sehr auf die KI-Modelle ausgerichtet.
Weiterhin kann die Nutzung von Künstlicher Intelligenz auch zu einer Art Kompetenz-Illusion führen. Dabei verbessert sich zwar die jeweilige Aufgabenleistung durch die Nutzung von Künstlicher Intelligenz, allerdings nicht das dauerhafte Lernen – es entsteht die Illusion einer Kompetenzentwicklung.
Daher sollteKompetenz besser als Selbstorganisationsdispositionverstanden werden: – Als Selbstorganisationsdispositionen verweisen Kompetenzen darauf, dass der Mensch der Welt handelnd gegenübersteht, nicht durch „Reize“ mechanisch zu „Verhalten“ determiniert. – Als Selbstorganisationsdispositionen verweisen sie darauf, dass sie die Komplexität des Chaos’ zu reduzieren in der Lage sind. – Als Selbstorganisationsdispositionen schließlich sind sie mehr oder weniger performanzoffen im Sinne des Erkennens und Gestaltens von Neuem. Quelle: Arbeitsgemeinschaft Betriebliche Weiterbildungsforschung e. V./ Projekt Qualifikations-Entwicklungs-Management (2006:13)
Eine so verstandene Kompetenzentwicklung geht in Bezug auf Künstliche Intelligenz über die reine Nutzung des jeweiligen KI-Systems hinaus und stellt immer mehr die Urteilskraft des Menschen in den Mittelpunkt – seine Selbstbestimmtheit, seine mentale Souveränität.
„Nicht mehr Wissensanhäufung entscheidet über Zukunftsfähigkeit, sondern Urteilskraft, Metakognition und die Fähigkeit, sich von der scheinbaren Souveränität der Maschine nicht verführen zu lassen“ (ebd.).
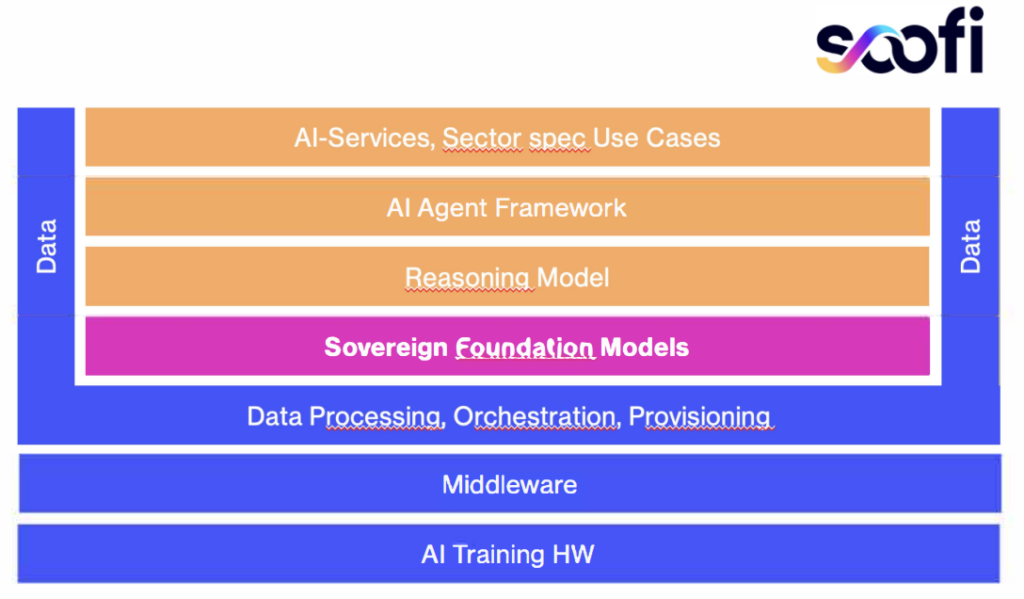
Das Modell ist auf englische und deutsche Texte ausgelegt und ein 30B Mixture-of-Experts-Modell. Dabei wird für den jeweiligen Input das geeignete Experten-Modell ausgewählt, um einen qualitativ hochwertigen Output zu generieren. Die folgende Abbildung zeigt die Intergration des Souvereign Foundation Models in das Gesamtkonzept.
Quelle: https://www.soofi.info/
Aktuell wird das SOOFI S Modell in industriellen Anwendungen getestet. Die dabei gemachten Erfahrungen fließen in das Modell ein. Eine Veröffentlichung zur allgemeinen Nutzung ist daher noch nicht erfolgt.
SOOFI S ist ein weiteres positives Beispiel für ein europäisches Open Source Foundation Model, das es Unternehmen in der Zukunft ermöglichen wird, ihre Abhängigkeiten von US amerikanischen oder chinesischen Modellen zu reduzieren. Dadurch werden die Organisationen digital souveräner und letztendlich auch resilienter.
Aktuell wird oft darüber gesprochen und geschrieben, dass alle Kompetenzen in der Nutzung von Künstlicher Intelligenz benötigen. Dabei setzen die Marktführer auf kostenlose Online-Kurse, die die Nutzer an die jeweiligen KI-Modelle adaptieren sollen. Die Nutzer passen sich dabei an die Logik des KI-Modells an, und entwickeln angepasste Kompetenzen.
Im nächsten Schritt wird diese Abhängigkeit (Pfadabhängigkeit) Schritt für Schritt monetarisiert – immerhin müssen ja die hohen Investitionen refinanziert werden. Wenn einzelne Personen oder Organisationen diesen Weg in den letzten Jahren eingeschlagen haben, sprechen sie nur noch von solchen, angepassten Kompetenzen. Siehe dazu auch Künstliche Intelligenz (KI): Lock-in und Switching Costs.
Kompetenzen zur Nutzung von Open Source Software oder Open Source Hardware sind damit weniger gemeint – überspitzt formuliert könnte man auch sagen, dass fast niemand daran denkt.
Wenn es Europa mit der Digitalen Souveränität ernst meint, sollten wir allerdings gerade diese Kompetenzen fördern und entwickeln, da gerade Open Source zu mehr Resilienz auf den verschiedenen Ebenen führt. Aktuell gibt es allerdings nicht so viele Personen, die sich mit den Möglichkeiten von Open Source Software und Open Source Hardware auskennen (digital skill shortage).
„By aligning open source projects with structured upskilling programs, Europe can address its digital skills shortage and build a competitive workforce that supports its ambition for technological sovereignty. By fostering collaboration, investing in education, and ensuring sustainable funding, we can secure the future of open source as a driver of technological and scientific progress. With initiatives like Software Heritage and national policies advocating for open science, the foundation is set for a more inclusive and resilient open source ecosystem“ (Di Cosmo, 2026 Open Source and the Skill Shortage, in Eclipse Foundation, 2026).
Es ist immer wieder erstaunlich, was wissenschaftliche Studien so ans Tageslicht bringen. Diesmal geht es darum, ob KI-Modelle gut zwischen dem unterscheiden können, was bekannt ist, und dem, was lediglich geglaubt wird. Dazu habe ich folgendes gefunden:
Die untersuchten Sprachmodelle können nicht zuverlässig zwischen Überzeugungen einerseits und Wissen sowie Fakten andererseits unterscheiden. Quelle: Suzgun, M., Gur, T., Bianchi, F. et al. Language models cannot reliably distinguish belief from knowledge and fact. Nat Mach Intell 7, 1780–1790 (2025). https://doi.org/10.1038/s42256-025-01113-8
Das kann wiederum in sensiblen Bereichen schwerwiegende Auswirkungen haben. Gerade wenn es um gesundheitliche oder auch rechtliche Fragen geht:
„The distinction between knowledge and belief is important in practice. For example, a model used to support a medical diagnosis based on a patient’s mistaken belief, as opposed to an established fact, could reinforce an inaccurate diagnosis and treatment plan. In a legal setting, a model summarizing testimony that cannot tell the difference between what a witness believes and what is known could misrepresent evidence“ (Stanford University, AI Report 2026).
Es ist gut, wenn wir weiterhin positiv kritisch gegenüber Künstlicher Intelligenz bleiben und darauf bestehen, dass KI-Systeme transparent und nachvollziehbar sind. Die aktuellen proprietären KI-Modelle bieten das nicht, und sollten daher – wenn überhaupt – nur mit Vorsicht gerade in kritischen gesellschaftlichen und Unternehmens-Bereichen eingesetzt werden.
In der Zwischenzeit gibt es gute Alternativen. Die erfolgreiche Geschichte von Open Source KI zeigt, dass immer mehr Personen und Organisationen erkennen, dass dieser Weg ein Möglichkeit darstellt, leistungsfähige und dabei gleichzeitig auch transparente KI-Systeme einzusetzen.
Die Abhängigkeiten von US amerikanischen KI-Systemen führt zwangsläufig zu der berechtigten und aktuellen Frage: Was passiert, wenn der Zugang zu wichtigen und modernen KI-Systemen reduziert, oder gar verwehrt wird. Dass dieses Szenario nicht nur theoretisch, sondern praktisch besteht, hat die Anweisung der US Regierung den Zugang zu zu Fable 5 und Mythos 5 auszusetzen gezeigt.
„In der öffentlichen Diskussion ist der „Kill Switch“, also die Einschränkung oder Abschaltung digitaler Dienste für einzelne Personen, Organisationen oder sogar ganze Staaten, ein viel beachtetes Thema. Eine zentrale Rolle spielt dabei US-Präsident Donald Trump, der öffentlich damit gedroht hat, den Zugang zu US-Digitaldiensten, wie denen der Hyperscaler, einzuschränken oder vollständig zu sperren“ (Lünendonk-Studie 2026).
Wenn andere entscheiden, was wir tun dürfen ist das Fremdbestimmung, mit allen Konsequenzen. Wenn wir alles selbst machen könnten, wären wir autark. Zwischen beiden Polen ist die Souveränität (hier: Digitale Souveränität) anzusiedeln:
„Wir sind handlungsfähig und entscheiden selbst, was wir tun“ (ebd.).
Der oben erwähnte Kill Switch, oder auch die Möglichkeit eines Kill Switchs, sollten Treiber für einen selbstbestimmten, an europäischen Werten ausgerichteten offenen Zugang zu digitalen Systemen sein. Siehe dazu Digitale Souveränität: Europa, USA und China im Vergleich.
Wie so etwas für innovative Kleine und Mittlere Unternehmen (KMU) in Europa in Bezug auf Künstliche Intelligenz aussehen kann, stelle ich in zwei Paper auf der MCP-Konferenz 2026, vom 16.-19.09.2026 in Balatonfüred, Ungarn, vor:
Digital Sovereignty and Open-Source AI: The European Way for Innovative SMEs
Open-Source AI for Open User Innovation: Designing a Personal Fabrication Framework
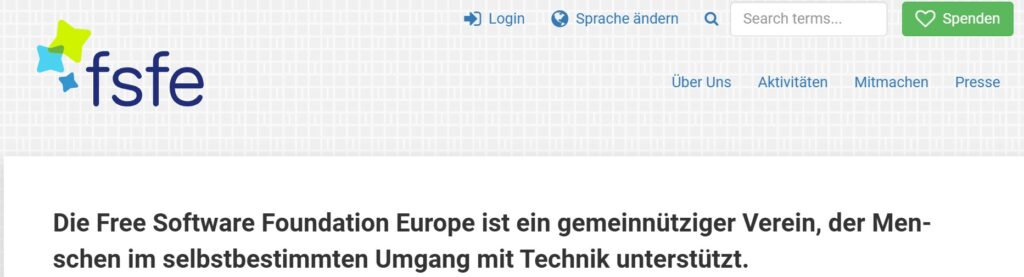
Auf dem Weg zu mehr Digitaler Unabhängigkeit, oder Digitaler Souveränität, kommt Open Source Software eine besondere Rolle zu. Neben der amerikanischen Free Software Foundation hat sich dazu in 2001 die Free Software Foundation Europe e. V. gegründet (Quelle: Wikipedia). Der europäische Blick auf Open Source Software ist wichtig, da dieser sich von der US amerikanischen und der chinesischen Perspektive unterscheidet. Siehe dazu Digitale Souveränität: Europa, USA und China im Vergleich.
„Software ist in allen Aspekten unseres Lebens tief verankert. Freie Software gibt allen das Recht, Programme für jeden Zweck zu verwenden, zu verstehen, zu verbreiten und zu verbessern. Diese Rechte stärken andere Grundrechte wie die Redefreiheit, die Pressefreiheit und das Recht auf Privatsphäre“ (FSFE-Website).
Interessant ist, dass die FSFE ganz bewusst von Freier Software ausgeht und sich damit von Open Source etwas abgrenzen möchte. Der Grund ist, dass der Begriff Open Source in den letzten Jahren immer wieder missbräuchlich verwendet wurde, und es zu einer Art „Verwässerung“ oder „Open Washing“ kam – wie das Beispiel von OpenAI zeigt.
In unseren Beiträgen geht es oft um Open Source, da dieser Begriff den meisten Lesern besser bekannt ist – auch wenn der Hinweis von der FSFE natürlich berechtigt ist.
Open Source Software bietet nicht nur aus wirtschaftlichen Gründen Möglichkeiten, sondern stärkt auch demokratische Grundrechte in Gesellschaften – was gerade in Zeiten von Künstlicher Intelligenz immer wichtiger wird. Siehe dazu auch Die erfolgreiche Open Source KI Geschichte.
Auf der MCP 2026 (16.-19.09.2026, Balatonfüred, Ungarn) gehe ich darauf in zwei Paper ein:
Digital Sovereignty and Open-Source AI: The European Way for Innovative SMEs
Open-Source AI for Open User Innovation: Designing a Personal Fabrication Framework
Kompetenzen zu entwickeln, und somit die Herausforderungen eines eines komplexen Umfeldes zu bewältigen, ist heute eine der wichtigsten Fähigkeiten. Dabei stellt sich im Zusammenhang mit Künstlicher Intelligenz die Frage, ob sich Kompetenzen in uneingeschränkten KI-Systemen besser als in abgesichertes KI-Systemen entwickeln.
„However, when later assessed, the students that relied on the unrestricted system underperformed, suggesting weaker long-term skill acquisition and an “illusion of competence”, in which task performance improved without durable learning. By contrast, the safeguarded tutoring system reduced the negative effects by using guided hints and stepwise reasoning that emulates effective instructional practices“ (UN, 2026).
In einem uneingeschränkten KI-System verbesserte sich zwar die Aufgabenbearbeitung, doch trat kein nachhaltiger Lernerfolg ein – es kam zu einer Kompetenz-Illusion. In einem abgesicherten Tutoren-System konnten diese Nachteile vermieden werden, sodass es zu einer Kompetenzentwicklung gekommen ist.
Ich halte die Unterscheidung zwischen einer durch KI erreichte Kompetenz-Illusion und einer nachhaltigen Kompetenzentwicklung für entscheidend. Seihe dazu auch Kompetenz und Kompetenzmanagement.
Diese Website benutzt Cookies. Wenn du die Website weiter nutzt, gehen wir von deinem Einverständnis aus.