Im Netz sind auch Personen unterwegs, deren Identität nicht bekannt ist. Für manche ist es der Schutz ihrer persönlichen Privatsphäre, für andere bietet Anonymität im Netz die Möglichkeit, Beiträge zu verfassen, die andere diffamieren.
Forscher von der ETH Zürich, MATS Research und Anthropic sind einmal der Frage nachgegangen, ob es mit den Möglichkeiten der Künstlichen Intelligenz in großem Maßstab möglich ist, zu de-anonymisieren. In dem Paper von Lermen et al. (2026) wurde die Vorgehensweise und die Ergebnisse ausführlich dargestellt.
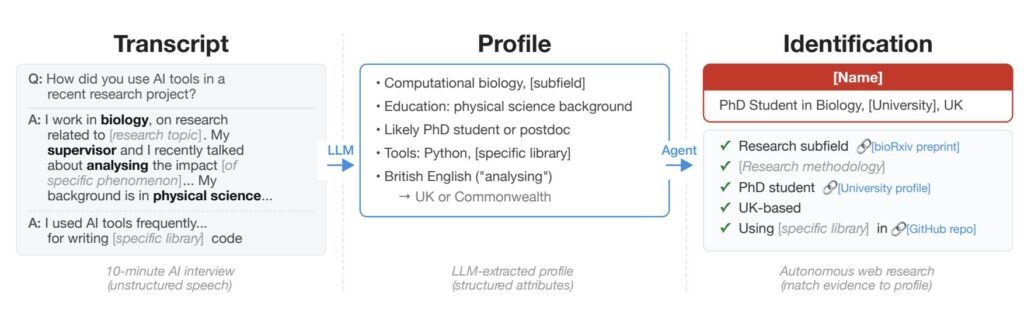
Die Abbildung zeigt, wie aus einem einzelnen Interview mit Hilfe eines Large Language Models (LLM) ein Profil erstellt wurde, und abschließend ein KI-Agent die Person identifizieren konnte.
„End-to-end deanonymization from a single interview transcript from (details altered to protect the subject’s identity). An LLM agent extracts structured identity signals from a conversation, autonomously searches the web to identify a candidate individual, and verifies the candidate matches all extracted claims“ (Lermen et al. (2026): Large-scale online deanonymization with LLMs | PDF).
Die technischen Möglichkeiten haben nun zwei Effekte: (1) Anonyme Nutzer im Netz, die sich strafbar machen, können identifiziert werden. (2) Für Nutzer, die ihre Anonymität aus den verschiedenen Gründen wahren möchten, reicht ein Pseudonym im Netz in Zukunft wohl nicht mehr aus.
Eigener Screenshot von unserer Nextcloud mit der App „Collective“
Unsere Nextcloud (Open Source) ist ein zentrales Element auf dem Weg zur Digitalen Souveränität. Dazu gehören nicht nur Möglichkeiten, LocalAI oder auch KI-Agenten zu nutzen, sondern auch Anwendungen (Apps), die wir im Tagesgeschäft benötigen.
Zum Beispiel haben wir die App Collective installiert und aktiviert. In der Abbildung ist ein Screenshot von einer angelegten Startseite zum Thema „Agentic AI Company“ zu sehen.
Zu diesem Bereich kann ich nun verschiedene Teilnehmer zuordnen/einladen. Dabei können alle die jeweiligen Seiten wie in einem Wiki kollaborativ bearbeiten. Diese Möglichkeit geht über die reine Bereitstellung eines gemeinsamen Ordners hinaus und unterstützt die gemeinsame Entwicklung von (expliziten) Wissen.
Wichtig dabei ist, dass alle Daten, die hier gemeinsam geteilt und bearbeitet werden, auf unserem Server bleiben.
Natürlich können auch andere Wiki-Apps (Open Source) in die Nextcloud eingebunden werden. Jeder kann somit seine Nextcloud so konfigurieren, wie er möchte.
In den letzten Jahren haben die bekannten KI-Tech-Unternehmen viel Geld damit verdient, Daten aus dem Internet zu sammeln und als Trainingsdaten für Large Language Models (LLMs) zu nutzen. Dabei sind diese Unternehmen nicht gerade zimperlich mit Datenschutz oder auch mit Urheberrechten umgegangen.
Es war abzusehen, dass es gegen dieses Vorgehen Widerstände geben wird. Neben den verschiedenen Klagen von Content-Erstellern wie Verlagen, Filmindustrie usw. gibt es nun immer mehr technische Möglichkeiten, das unberechtigte Scraping und Verwenden von Originalinhalten zu stoppen. Ein kommerzielles Beispiel dafür ist Cloudfare. In einer Pressemitteilung vom 01.07.2025 heißt es:
„San Francisco (Kalifornien), 1. Juli 2025 –Cloudflare, Inc. (NYSE: NET), das führende Unternehmen im Bereich Connectivity Cloud, gibt heute bekannt, dass es nun als erster Anbieter von Internetinfrastruktur standardmäßig KI-Crawler blockiert, die ohne Erlaubnis oder finanziellen Ausgleich auf Inhalte zugreifen. Ab sofort können Eigentümerinnen und Eigentümer von Websites bestimmen, ob KI-Crawler überhaupt auf ihre Inhalte zugreifen können, und wie dieses Material von KI-Unternehmen verwertet werden darf“ (Source: Cloudfare).
Siehe dazu auch Cloudflare blockiert KI-Crawler automatisch (golem vom 01.07.2025). Ich kann mir gut vorstellen, dass es in Zukunft viele weitere kommerzielle technische Möglichkeiten geben wird, Content freizugeben, oder auch zu schützen.
Das ist zunächst einmal gut, doch sollte es auch Lösungen für einzelne Personen geben, die sich teure kommerzielle Technologie nicht leisten können oder wollen. Beispielsweise möchten wir auch nicht, dass unsere Blogbeiträge einfach so für Trainingsdaten genutzt werden. Obwohl wir ein Copyright bei jedem Beitrag vermerkt haben, wissen wir nicht, ob diese Daten als Trainingsdaten der LLMs genutzt werden, da die KI-Tech-Konzerne hier keine Transparenz zulassen. Siehe dazu auch Open Source AI: Besser für einzelne Personen, Organisationen und demokratische Gesellschaften.
In dem Blogbeitrag Was unterscheidet Künstliche Intelligenz von Suchmaschinen? hatte ich dargestellt, wie sich Suchmaschinen von Künstlicher Intelligenz unterscheiden. Content-Anbieter können dabei nur bedingt auf Datenschutz, Urheberrecht, EU AI Act usw. vertrauen. In der folgenden Veröffentlichung sind die verschiedenen Punkte noch einmal strukturiert zusammengefasst, inkl. einer möglichen Lösung für die skizzierten Probleme:
Creative Commons (2025): From Human Content to Machine Data. Introducing CC Signals | PDF
Creative Commons (CC) kennen dabei viele von uns als eine Möglichkeit, anderen unter bestimmten Bedingungen das Recht zur Nutzung des eigenen Contents einzuräumen. Creative Commons erläutert, dass KI-Modelle die üblichen gesellschaftlichen Vereinbarungen mehr oder weniger ignoriert, und somit den „social contract“ aufkündigt. Diesen Hinweis finde ich bemerkenswert, da hier das Vorgehen der KI-Tech-Unternehmen mit den möglichen gesellschaftlichen Auswirkungen verknüpft wird.
Mit CC Signalshat Creative Commons ein erstes Framework veröffentlich, das es ermöglichen soll, Content mit Berechtigungsstufen für KI-Systeme zu versehen.
„CC signals are a proposed framework to help content stewards express how they want their works used in AI training—emphasizing reciprocity, recognition, and sustainability in machine reuse. They aim to preserve open knowledge by encouraging responsible AI behavior without limiting innovation“ (ebd.)
Machen Sie bei der Weiterentwicklung dieses Ansatzes mit:
Digitale Abhängigkeit kann für Personen, Organisationen oder ganze Gesellschaften kritisch sein. In Zeiten der Trump-Administration und der massiven Marktbeherrschung bei Software, Cloud-Anwendungen und Künstlicher Intelligenz durch US-amerikanische Tech-Konzerne wird es Zeit, auf allen Ebenen über Digitale Souveränität nachzudenken, und entsprechend zu handeln.
In der Zwischenzeit gibt es viele Open Source Anwendungen die als Alternativen zur Verfügung stehen. Das dänische Digitalministerium ersetzt beispielsweise Microsoft Office durch Libre Office, Schleswig-Holstein setzt in der Verwaltung auf Nextcloud usw. usw.
Wir haben diese Entwicklung schon vor Jahren kommen sehen, und uns langsam aber sicher ein eigenes Open-Source-Ökosystem zusammengestellt, das wir immer stärker nutzen und ausbauen – Schritt für Schritt.
(1) Zunächst haben wir Nextcloud auf unseren Servern installiert. Damit konnten wir die bekannten Microsoft-Anwendungen, inkl. MS-Teams (jetzt mit Nextcloud Talk), Whiteboard, usw. ersetzen. Dateien können auch kollaborativ, also gemeinsam, bearbeitet werden. Siehe dazu beispielsweise auch Google Drive im Vergleich zu Nextcloud. Alle Möglichkeiten der Nextcloud finden Sie unter https://nextcloud.com/.
(3) Danach haben wir den Nextcloud-Assistenten integriert, sodass wir in jeder Nextcloud-Anwendung den Assistenten mit seinen verschiedenen Funktionen nutzen können; inkl. eines Chats mit hinterlegter lokaler Künstlichen Intelligenz – LocalAI (Siehe Punkt 5).
(4) Mit Nextcloud Flow können wir Abläufe automatisieren. Zunächst natürlich Routineabläufe, und wenn es komplexer wird mit KI-Agenten (Siehe Punkt 6).
(5) Eine weitere wichtige Ergänzung war dann LocalAI, das uns lokale KI-Anwendungen auf unserem Server ermöglicht – eingebunden in den Nextcloud-Assistenten (Siehe Punkt 3) Alle Daten bleiben auch hier auf unseren Servern.
(6) Aktuell arbeiten und testen wir KI-Agenten auf Open-Source-Basis. Dabei verknüpfen wir über Ollama eine ausgewählte Trainingsdatenbank (Large Language Model oder Small Language Model – alles natürlich Open Source AI) mit unseren eigenen Daten, die in unserer Nextcloud zur Verfügung stehen. Dafür verwenden wir aktuell Langflow, das auch auf unserem Servern installiert ist – auch diese Daten bleiben alle bei uns.
(…..) und das ist noch lange nicht das Ende der Möglichkeiten. Sprechen Sie uns gerne an, wenn Sie zu den genannten Punkten Fragen haben.
Conceptual technology illustration of artificial intelligence. Abstract futuristic background
Man könnte meinen, dass Künstliche Intelligenz (GenAI) doch nur eine Weiterentwicklung bekannter Suchmaschinen ist, doch dem ist nicht so. In einem Paper wird alles noch ausführlicher beschrieben. Hier nur ein Auszug:
“The intermediation role played by AI systems is altogether new: where the role of search engines has traditionally been to surface the most relevant links to answers of the user’s query, AI systems typically expose directly an answer… For the large number of content producers whose sustainability relies on direct exposure to (or interactions with) the final end user, this lack of reliable exposure makes it unappealing to leave their content crawlable for AI-training purposes.” (Hazaël-Massieux, D. (2024): Managing exposure of Web content to AI systems | PDF.
Für viele Content-Anbieter ist die Vorgehensweise der GenAI-Modelle von großem Nachteil, da diese direkte Ergebnisse liefern, und die Interaktionen mit dem User (wie bei den bisher üblichen Suchmaschinen-Ergebnissen) entfallen können. Die bekannten GenAI-Modelle (Closed Source) nutzen einerseits die vorab antrainierten Daten und andererseits live content (summarize this page), und machen daraus ein Milliarden-Geschäft.
Demgegenüber stehen erste allgemeine Entwicklungen wie EU AI Act, Urheberrecht, Datenschutz usw., die allerdings nicht ausreichend sind, sich als Content-Anbieter (Person, Unternehmen, Organisation, Verwaltung usw.) vor der Vorgehensweise der Tech-Giganten zu schützen.
Es müssen neue, innovative Lösungen gefunden werden.
Dabei wäre es gut, wenn jeder Content-Anbieter mit Hilfe eines einfachen Verfahrens (Framework) entscheiden könnte, ob und wie sein Content für die Allgemeinheit, für Suchmaschinen, für KI-Modelle verwendet werden darf.
… und genau so etwas gibt esin ersten Versionen.
Über diese Entwicklungen schreibe ich in einem der nächsten Blog-Beiträge noch etwas ausführlicher.
Die Digitale Abhängigkeit von amerikanischen oder chinesischen Tech-Konzernen, macht viele Privatpersonen, Unternehmen und Verwaltungen nervös und nachdenklich. Dabei stellen sich Fragen wie:
Wo befinden sich eigentlich unsere Daten?
Wissen Sie, wo sich ihre Daten befinden, wenn Sie neben ihren internen ERP-Anwendungen auch Internet-Schnittstellen, oder auch Künstliche Intelligenz, wie z.B. ChatGPT etc. nutzen?
Um wieder eine gewissen Digitale Souveränität zu erlangen, setzen wir seit mehreren Jahren auf Open Source Anwendungen. Die Abbildung zeigt beispielhaft einen Screenshot aus unserer NEXTCLOUD. Es wird deutlich, dass alle unsere Daten in Deutschland liegen – und das auch bei Anwendungen zur Künstlichen Intelligenz, denn wir verwenden LocalAI.
Wie schon in mehreren Blogbeiträgen erläutert, haben wir das Ziel, einen souveränen Arbeitsplatz zu gestalten, bei dem u.a. auch Künstliche Intelligenz so genutzt werden kann, dass alle eingegebenen und generierten Daten auf unserem Server bleiben.
Dazu haben wir LocalAI (Open Source) auf unserem Server installiert. Damit können wir aktuell aus mehr als 700 frei verfügbaren KI-Modellen je nach Bedarf auswählen. Zu beachten ist hier, dass wir nur Open Source AI nutzen wollen. Siehe dazu auch AI: Was ist der Unterschied zwischen Open Source und Open Weights Models?
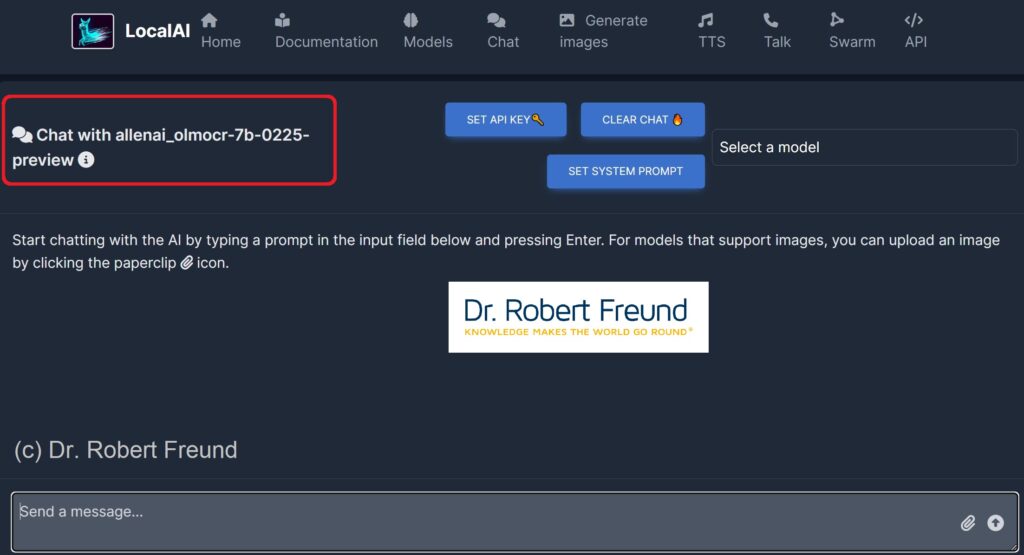
Bei den verschiedenen Recherchen sind wir auch auf OLMo gestoßen. OLMo 2 ist eine LLM-Familie (Large Language Models), die von Ai2 – einer Not for Profit Organisation – entwickelt wurde und zur Verfügung gestellt wird:
„OLMo 2 is a family of fully-open language models, developed start-to-finish with open and accessible training data, open-source training code, reproducible training recipes, transparent evaluations, intermediate checkpoints, and more“ (Source: https://allenai.org/olmo).
Unter den verschiedenen Modellen haben wir uns die sehr spezielle Version allenai_olmocr-7b-0225 in unserer LocalAI installiert – siehe Abbildung.
„olmOCR is a document recognition pipeline for efficiently converting documents into plain text“ (ebd.)
Künstliche Intelligenz (KI oder AI: Artificial Intelligence) einzusetzen ist heute in vielen Organisationen schon Standard. Dabei nutzen immer noch viele die von den kommerziellen Anbietern angebotenen KI-Systeme. Dass das kritisch sein kann, habe ich schon in vielen Blogbeiträgen erläutert.
Wir wollen einen anderen Weg, aufzeigen, der die Digitale Souveränität für Organisationen und Privatpersonen ermöglicht: Open Source AI und eine Open Source Kollaborationsplattform. Siehe dazu Von der digitalen Abhängigkeit zur digitalen Souveränität.
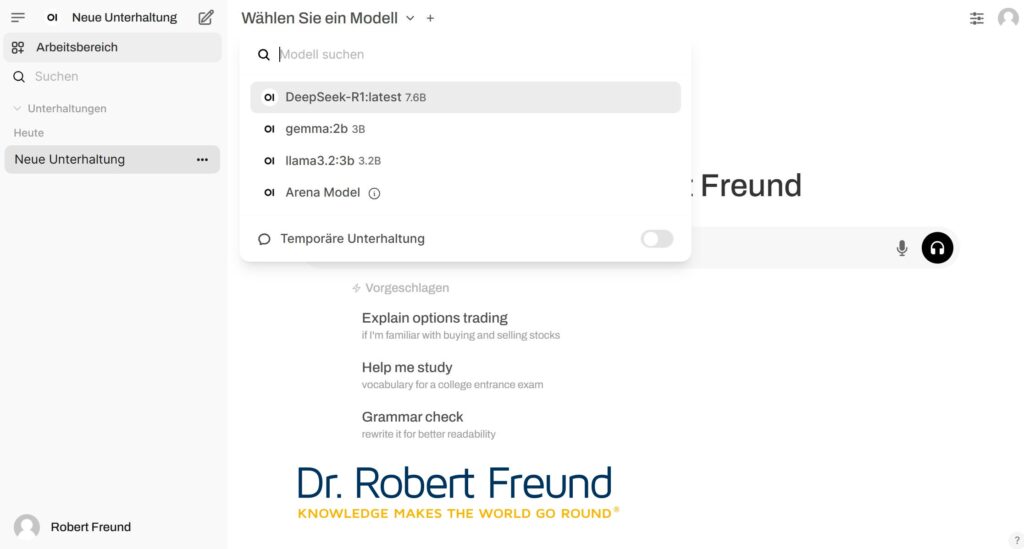
Im zweiten Schritt haben wir für die Entwicklung von AI-Agenten Langflow (Open Source) auf unserem Server installiert. Dabei ist es möglich, ChatGPT von OpenAI, oder über Ollama sehr viele unterschiedliche Open Source Modelle zu nutzen. Wir wollen natürlich den zweiten Weg gehen und haben daher Ollamaauf unserem Server installiert.
Ollama Startseite auf unserem Server: Eigener Screenshot
In der Abbildung ist zu sehen, dass wir für den ersten Test zunächst vier Modelle installiert haben, inkl. DeepSeek-R1 und LLama 3.2. Demnächst werden wir noch weitere Modelle installieren, die wir dann in Langflow integrieren, um AI-Agenten zu entwickeln. In den kommenden Wochen werden wir über die Erfahrungen berichten.
Das nächste große Ding in der KI-Entwicklung ist der Einsatz von KI-Agenten (AI Agents). Wie schon in vielen Blogbeiträgen erwähnt, gehen wir auch hier den Weg dafür Open Source zu verwenden. Bei der Suche nach entsprechenden Möglichkeiten bin ich recht schnell auf Langflow gestoßen. Die Vorteile lagen aus meiner Sicht auf der Hand:
(1) Komponenten können per Drag&Drop zusammengestellt werden. (2) Langflow ist Open Source und kann auf unserem eigenen Server installiert werden. Alle Daten bleiben somit auf unserem Server.
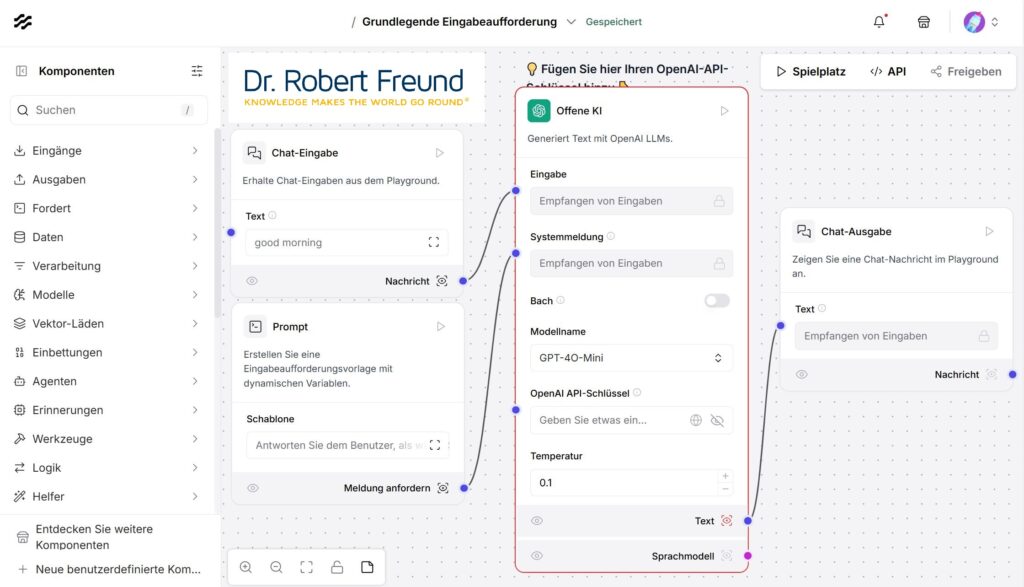
Die Abbildung zeigt einen Screenshot von Langflow – installiert auf unserem Server.
Auf der linken Seite der Abbildung sind viele verschiedene Komponenten zu sehen, die in den grau hinterlegten Bereich hineingezogen werden können. Per Drag&Drop können INPUT-Komponenten und OUTPUT-Format für ein KI-Modell zusammengestellt – konfiguriert – werden. Wie weiterhin zu erkennen, ist standardmäßig OpenAI als KI-Modell hinterlegt. Für die Nutzung wird der entsprechende API-Schlüssel eingegeben.
Mein Anspruch an KI-Agenten ist allerdings, dass ich nicht OpenAI mit ChatGPT nutzen kann, sondern auf unserem Server verfügbare Trainingsdaten von Large Language Models (LLM) oder Small Language Models (SML), die selbst auch Open Source AI sind. Genau diesen Knackpunkt haben wir auch gelöst. Weitere Informationen dazu gibt es in einem der nächsten Blogbeiträge. Siehe in der Zwischenzeit auch