OpenProject ist schon lange eine Alternative zu den proprietären Projektmanagement-Tools wie MS Project oder Jira etc. Die Integration von OpenProject in Nextcloud führt zu einer Kollaborationsplattform, bei der alle Daten auf dem eigenen Server bleiben und alle Anwendungen Open Source basiert sind. Siehe dazu unsere verschiedenen Blogbeiträge zu OpenProject.
Mit der Integration von OpenProject mit Nextcloud (Alternative zu Microsoft Sharepoint), inkl. TALK als Videokonferenzsystem (Alternative zu Microsoft Teams) etc. wurde schon ein wesentlicher Schritt in Richtung Digitale Souveränität am Arbeitsplatz gemacht.
Bei der Version OpenProject 17.2 gibt es eine Weiterentwicklung die es ermöglicht, Künstliche Intelligenz (Large Language Models oder Small Language Models) über einen sicheren MCP Server in die eigenen Projekte einzubinden.
MCP (Model Context Protocol) ist ein offener Standard von Anthropic über den LLM und externe Tools via APIs oder eigene Datenquellen eingebunden werden können.
Wie Sie wissen, schlagen wir in unseren Blogbeiträgen immer vor, Open Source AI und Open Source Software zu verwenden – möglichst auf dem eigenen Server. Dann bleiben alle Daten bei Ihnen und werden nicht von anderen genutzt – ganz im Sinne der Digitalen Souveränität.
Es ist schon erstaunlich, was man alles mit Künstlicher Intelligenz (GenAI) machen kann. Der Schwerpunkt scheint aktuell darauf zu liegen, in Organisationen die Abläufe zu verbessern, um die Produktivität zu erhöhen.
Weiterhin werden die KI-Modelle immer intuitiver und einfacher, was die Anwendung von KI scheinbar immer leichter macht.
Eine aktuelle Studie (Liu et al. 2026) kommt allerdings zu dem Schluss, dass, je leichter KI (GenAI) angewendet werden kann, umso wichtiger ist der Mensch, der die „harte Arbeit“ erledigen muss.
„The uncomfortable truth: the easier AI gets, the more valuable the people who still do the hard work become — and the more urgently organisations need to protect the conditions that produce them“ (Liu et al 2026).
Weiterhin wird in der selben Studie auf den Zusammenhang zwischen der Produktivität bei der Nutzung von KI und Innovation durch KI eingegangen: Die Produktivität steigt, doch Innovation (das Innovations-Niveau) stagniert.
Das liegt laut Studie an den „good enough“ – Antworten der üblichen KI-Modelle, die zu wenig „Friktion“ bieten, um Innovationen zu pushen.
Wenn alles zu einfach und zu leicht ist, kann das dann jeder und es ist nichts Neues mehr im Sinne einer Innovation. Die Autoren empfehlen daher ein angemessenes Maß an Friktion in der Organisation zu etablieren. Dazu wurde auch ein erstes geeignetes Framework entwickelt.
Auf die neue Mistral 3 KI-Modell-Familie hatte ich schon im Dezember 2025 in einem Blogbeitrag hingewiesen. Das französische Start-Up wurde 2023 gegründet: „(…) the company’s mission of democratizing artificial intelligence through open-source, efficient, and innovative AI models, products, and solutions“ (Quelle: Website).
Dieses Demokratisieren von Künstlicher Intelligenz durch Open Source, als europäischer und DSGVO-konformer Ansatz, ist genau der Weg, den ich schon in verschiedenen Beiträgen vertreten habe. Es ist daher interessant, auch den in 2024 veröffentlichten Bot Le Chat im Vergleich beispielsweise zu ChatGPT zu testen.
Die Abbildung weiter oben zeigt die Landingpage für Le Chat mit einem einfachen Feld für die Eingabe eines Prompts. Man kann die Leistungsfähigkeit des Bots testen, ohne sich anmelden zu müssen. Ich habe mich also zunächst nicht angemeldet und einfach einmal eine Frage eingegeben, die mich aktuell beschäftigt: Es geht um die Unterschiede zwischen den Auffassungen von Henry Chesbrough und Eric von Hippel zu Open Innovation.
Ausschnitt aus der Antwort zum eingegebenen Prompt
Die Abbildung zeigt einen Ausschnitt aus der umfangreichen Antwort auf meine Frage, inkl. der generierten Gegenüberstellung der beiden Ansichten auf Open Innovation. Die Antwort kam sehr schnell und war qualitativ gut – auch im Vergleich zu ChatGPT.
Mistral Le Chat ist ein europäisches Produkt, das auch der DSGVO unterliegt und darüber hinaus neben französisch- und englischsprachigen, auch mit deutschsprachigen Daten trainiert wurde. Es ist spannend, sich mit den Mistral-KI-Modellen und mit Le Chat intensiver zu befassen.
Wir haben den kostenpflichtigen ChatGPT-Account in der Zwischenzeit gekündigt, und werden mehr auf Modell-Familien wie Mistral 3 und MistralLe Chat setzen. Wir sind gespannt, wie sich die Open Source Alternativen in Zukunft weiterentwickeln – ganz im Sinne einer Digitalen Souveränität. Siehe dazu auch
Im Netz sind auch Personen unterwegs, deren Identität nicht bekannt ist. Für manche ist es der Schutz ihrer persönlichen Privatsphäre, für andere bietet Anonymität im Netz die Möglichkeit, Beiträge zu verfassen, die andere diffamieren.
Forscher von der ETH Zürich, MATS Research und Anthropic sind einmal der Frage nachgegangen, ob es mit den Möglichkeiten der Künstlichen Intelligenz in großem Maßstab möglich ist, zu de-anonymisieren. In dem Paper von Lermen et al. (2026) wurde die Vorgehensweise und die Ergebnisse ausführlich dargestellt.
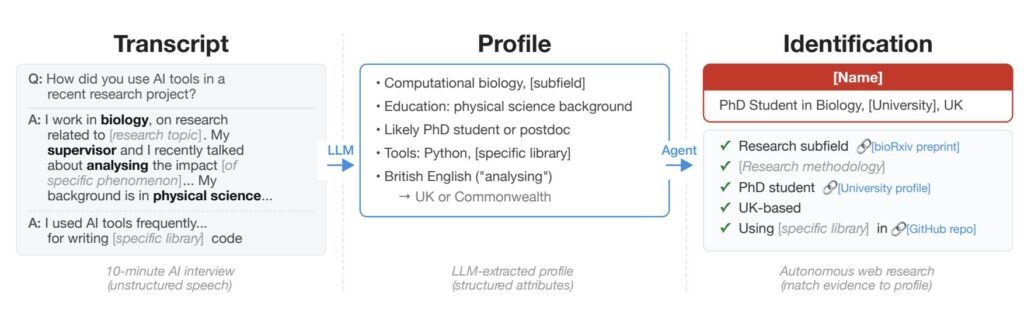
Die Abbildung zeigt, wie aus einem einzelnen Interview mit Hilfe eines Large Language Models (LLM) ein Profil erstellt wurde, und abschließend ein KI-Agent die Person identifizieren konnte.
„End-to-end deanonymization from a single interview transcript from (details altered to protect the subject’s identity). An LLM agent extracts structured identity signals from a conversation, autonomously searches the web to identify a candidate individual, and verifies the candidate matches all extracted claims“ (Lermen et al. (2026): Large-scale online deanonymization with LLMs | PDF).
Die technischen Möglichkeiten haben nun zwei Effekte: (1) Anonyme Nutzer im Netz, die sich strafbar machen, können identifiziert werden. (2) Für Nutzer, die ihre Anonymität aus den verschiedenen Gründen wahren möchten, reicht ein Pseudonym im Netz in Zukunft wohl nicht mehr aus.
Top view of multiracial young creative people in modern office. Group of young business people are working together with laptop, tablet, smart phone, notebook. Successful hipster team in coworking. Freelancers.
KI-Modelle sind auch Systeme, die selbstorganisiert, autopoietisch agieren. Es wundert daher nicht, dass bei der Beschreibung von KI-Systemen die üblichen Begriffe aus der Systemtheorie verwendet werden. Doch schauen wir uns einmal an, was beispielsweise mit dem Begriff Autopoiesis ursprünglich gemeint war.
„Das Kunstwort Autopoiesis, das sich aus den griechischen Worten autos (selbst) und poiein (=machen) zusammensetzt, wurde übrigens von Maturana selbst geprägt und meint so viel wie Selbsterzeugung, Selbstherstellung. Maturana und Varela haben den Begriff benutzt, um die Eigenart der Organisation von Lebewesen zu beschreiben. Es geht ihnen um die Definition bzw. Theorie des Lebendigen“ (Maturana / Varela 1992:50f.), zitiert in Dewe 2010).
Es wundert nicht, dass Maturana und Varela als Biologen damit etwas Lebendiges im Sinn hatten.
Weiterhin sind autopoietische Systeme nicht nur selbstbezogen, und selbstherstellend, sondern auch selbstbegrenzend (vgl. dazu W. Krohn und G. Küppers (Hrsg.): Emergenz: Der Entstehung von Ordnung, Organisation und Bedeutung. Frankfurt am Main 1992, S. 394).
Damit ist man bei der Beziehung System – Umwelt. „Das System bezieht jedoch nichts Vorgefertigtes aus der Umwelt, sondern es schafft sich durch interne Unterscheidungen seine bestimmte Umweltsensibilität. (…) Das System verändert sich, indem es seine Strukturen verändert – es lernt. Es verändert sich, wie bereits beschrieben, nicht unendlich, sondern nur so lange, wie es die eigene Autopoiesis nicht gefährdet“ (Dewe 2010).
Ein KI-System lernt somit nur so lange, wie die eigene Autopoiese nicht gefährdet ist.
Welche Rolle spielt der Mensch in Bezug auf System und Umwelt?
Wenn sich alles selbstorganisiert und selbstbegrenzend entwickelt, stellt sich die Frage, ob der Mensch Bestandteil des (sozialen) Systems ist, oder eher zur Umwelt zählt.
„Das Herauslagern des Menschen aus dem sozialen System in die Umwelt des Systems (in Form des psychischen Systems) verringert nicht die Bedeutung des Menschen, sondern verstärkt und unterstreicht ihn, denn wäre der Mensch mit Haut und Haaren Bestandteil des Systems dann handelte es sich um ein totalitäres System. Wird der Mensch aber herausgenommen, so schützt gerade dies seine Autonomie und Eigenständigkeit“ (Dewe 2010).
Wenn wir uns die KI-Modelle ansehen, so ist deren Ziel, den Menschen mit seinen Daten und Profilen im System abzubilden. Der Mensch wird somit immer mehr zum Bestandteil des KI-Systems.
Das bedeutet wiederum, ein KI-System kann in diesem Sinne immer mehr zu einem totalitäres System werden.
Immer mehr Menschen nutzen Künstliche Intelligenz, um gesundheitliche, psychologische oder berufliche Themen zu analysieren. Der Ratgeber ist in diesen Fällen also nicht der Arzt, der Psychologe, oder ein Kollege am Arbeitsplatz, sondern ChatGPT oder andere bekannte KI-Modelle.
Es ist in dem Zusammenhang wichtig, welche Werte von dem KI-Modell „vertreten“ werden. Warum? In dem Beitrag Digitale Souveränität: Europa, USA und China im Vergleich wird deutlich, wie unterschiedlich die Werte von KI-Modellen der US-amerikanischen Tech-Konzerne, chinesischen Modellen, und europäischen Modellen sein können.
Da wiederum Werte Ordner sozialer Komplexität sind, ermöglichen sie ein Handeln unter Unsicherheit und bestimmen die menschliche Selbstorganisation.
Systemische Sicht auf Werte: „Werte können als Ordnungsparameter (Ordner) selbstorganisierter komplexer biotischer, individueller, gruppenförmiger oder aggregierterer sozialhistorischer Systeme aufgefasst werden. Diese Ordner bestimmen oder beeinflussen zumindest stark die individuell-psychische und sozial-kooperativ kommunikative menschliche Selbstorganisation und ermöglichen eben damit jenes Handeln unter prinzipieller kognitiver Unsicherheit“ (Haken 1996).
Immer mehr Menschen nutzen Künstliche Intelligenz, um gesundheitliche oder psychologische Themen zu analysieren. Der Ratgeber ist dann also nicht der Arzt oder der Psychologe, sondern ChatGPT oder andere bekannte KI-Modelle.
Bei der Kommunikation Mensch – KI dringt die KI immer tiefer in das Profil des Menschen ein. Die Profile werden dann auch dazu genutzt, dem Nutzer zu schmeicheln.
Schmeicheln bedeutet „jemandem übertrieben und nicht ganz aufrichtig Angenehmes sagen, um dessen Gunst zu gewinnen“ (Quelle).
In einer Studie (Jain et al. 2026) wurden zwei Schmeicheleien unterschieden: (1) Zustimmungsschmeichelei (agreement sycophancy) – die Tendenz von Modellen, übermäßig positive Reaktionen hervorzurufen, und (2) Perspektivenschmeichelei (perspective sycophancy) – das Ausmaß, in dem Modelle die Sichtweise eines Nutzers widerspiegeln.
Es stellte sich daher die Frage: Verstärkt Personalisierung das Ausmaß der Schmeicheleien?
„Our results raise the question of whether some personalization approaches may amplify sycophancy. Prior work often attributes sycophancy to preference alignment, since users prefer responses that are affirmative or aligned with their perspective. Yet in aligned models, we find that user memory profiles are associated with further increases in agreement sycophancy, and that contexts providing more information about the user drive perspective sycophancy“ Source: Jain et al. (2026): Interaction Context Often Increases Sycophancy in LLM | PDF
Es wurde also in der Studie klar, dass Nutzerprofile eher Zustimmungsschmeicheleien, und Kontextinformationen eher Perspektivenschmeichelei verstärken. Egal welches Element man also betrachtet, Schmeicheleien verstärken sich wohl mit der Zeit.
Bei diesen Entwicklungen stehen wir noch am Anfang, doch deutet sich schon jetzt ein entsprechender Klärungsbedarf an: Wie können Personalisierung und Schmeicheleien ausbalanciert werden? Siehe dazu auch
Weiterhin wurde Open EuroLLM veröffentlicht, ein „Large language Modelmade in Europebuilt to support allofficial 24 EU languages„. Die generierten Modelle sind Multimodal, Open Source, High Performance und eben Multilingual.
Zusätzlich zur europäischen Ebene gibt es allerdings auch immer mehr spezielle, länderspezifische Large Language Models (LLMs), wie das in 2025 veröffentlichte PLLuM ((Polish Large Language Model). Ich möchte an dieser Stelle drei wichtige Statements wiedergeben, die auf der Website zu finden sind:
Polnische Sprachunterstützung Ein wichtiges Element dieses Projekts ist die Entwicklung eines umfassenden und vielfältigen Datensatzes, der die Komplexität der polnischen Sprache widerspiegelt.
Die polnische Sprachunterstützung geht darauf ein, dass die üblichen proprietären LLM überwiegend in englischer (chinesischer) Sprache trainiert wurden, und dann entsprechende Übersetzungen liefern. Diese sind für den Alltagsgebrauch durchaus nützlich, doch wenn es um die kulturellen, kontextspezifischen Nuancen einer Sprache geht, reichen diese großen KI-Modelle der Tech-Konzerne nicht aus.
Das PLLuM-Modell setzt auf Offenheit, Transparenz und einfache Bedienung. Es versteht sich daher von selbst, dass die Modelle bei Huggingface zur Verfügung stehen und genutzt werden können. Probieren Sie den Chat einfach einmal aus:
Sicherheit und Ethik Wir stellen sicher, dass unser Modell sicher und frei von schädlichen und falschen Inhalten ist, was für seinen Einsatz in der öffentlichen Verwaltung von entscheidender Bedeutung ist.
Nicht zuletzt sind Sicherheit und Ethik wichtige Eckpunkte für das polnische Modell. Es unterscheidet sich dadurch von den bekannten großen KI-Modellen der Tech-Konzerne. Siehe dazu auch Künstliche Intelligenz: Würden Sie aus diesem Glas trinken?
Interessant ist auch, dass auf der PLLuM-Website darauf hingewiesen wird, dass man durch diese KI-Modelle auch Innovationen fördern möchte. Wieder ein direkter Bezug zwischen Open Source AI und Innovationen.
Wenn wir heute über Medien sprechen oder schreiben, geht es meistens um Digitale Medien. Der althergebrachte Gedanke, dass Digitale Medien eher neutral sind, und nur Botschaften übermitteln, ist heute nicht mehr zeitgemäß. Denn ganz nach McLuhan (1968) ist das Medium die Botschaft. Was heißt das?
„Für eine medienwissenschaftliche Betrachtung Digitaler Medien ist der von dem kanadischen Medienwissenschaftler Marshall McLuhan formulierte Medienbegriff relevant, wie er in dem häufig zitierten Satz „the medium is the message“ (McLuhan 1968:15) zum Ausdruck kommt. Die Botschaft eines Mediums ist nach McLuhan die „Veränderung des Maßstabs, Tempos, Schemas, die es der Situation der Menschen bringt“ (ebd.: 22). Das heißt, dass Medien unabhängig vom transportierten Inhalt neue Maßstäbe setzen (ebd.: 21). Digitale Medien setzen im Bereich der Informations-, Kommunikations-, Arbeits- und Lernmöglichkeiten neue Maßstäbe. Der McLuhan’sche Medienbegriff steht im Kontrast zu einem Medienverständnis, wonach Medien neutral sind und lediglich als Übermittler von Botschaften dienen“.
Quelle: Carstensen, T. Schachtner, C.; Schelhowe, H.; Beer, R. (2014): Subjektkonstruktion im Kontext Digitaler Medien. In: Carstensen, T. (Hrsg.) (2014): Digitale Subjekte. Praktiken der Subjektivierung im Medienumbruch der Gegenwart.
Gerade in Zeiten Künstlicher Intelligenz geht es daher nicht alleine um den Content, sondern auch darum, dass KI-Modelle neue Maßstäbe setzen. Gerade dieser Effekt von KI ist bei Verlagen, in der Musikbranche, bei Psychologen, Ärzten, usw. deutlich zu erkennen. Dabei ist auch der Hinweis von McLuhan wichtig, dass dadurch auch die Neutralität dieser Digitalen Medien verlorengeht.
KI-Modellen, mit den darin enthaltenen Ansichten zum Menschenbild,, zur Gesellschaftsformen usw., werden zu starken Beeinflusser von Individuen, die erst durch „das Gegenüber“ und durch Kontexte zu einem „Ich“ wird.
„Wer bin ich ohne die anderen? Niemand. Es gibt mich nur so, in einem Zusammenhang mit Menschen, Orten und Landschaften“ (Marica Bodroži 2012:81).
Conceptual technology illustration of artificial intelligence. Abstract futuristic background
Für komplexe Problemlösungen ist es wichtig, implizites Wissen zu erschließen. Wenig überraschend stellt Polanyi daher die Meister-Lehrling-Beziehung, in der sich Lernen als Enkulturationsprozess vollzieht, als essentielles Lern-Lern-Arrangement heraus:
„Alle Kunstfertigkeiten werden durch intelligentes Imitieren der Art und Weise gelernt, in der sie von anderen Personen praktiziert werden, in die der Lernende sein Vertrauen setzt“ (PK, S. 206). (Neuweg 2004).
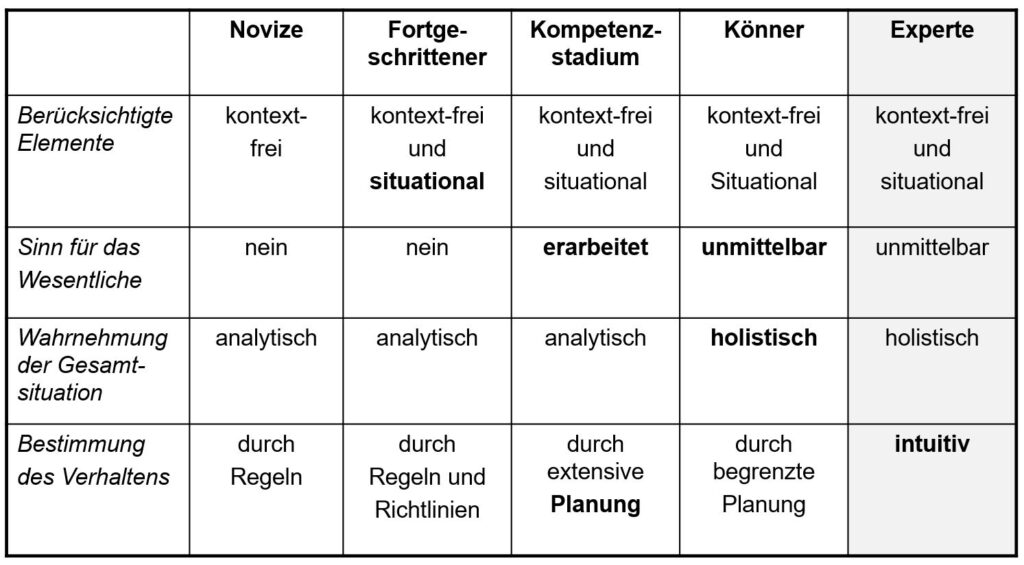
Das setzt auch die Anerkenntnis der Autorität des Experten voraus. Nach Dryfus/Dryfus ergeben sich vom Novizen bis zum Experten folgende Stufen der Kompetenzentwicklung:
Das Modell des Fertigkeitserwerbs nach Dreyfus/Dreyfus (Neuweg 2004)
Wenn wir uns nun die Beziehung zwischen Künstlicher Intelligenz und dem (nutzenden) Menschen ansehen, so kann diese Beziehung oftmals wie eine Meister-Lehrling-Beziehung beschrieben werden.
Dabei ist die „allwissende“ Künstliche Intelligenz (z.B. in Form von ChatGPT etc.) der antwortende Meister, der die Fragen (Prompts) des Lehrlings (Mensch) beantwortet. Gleichzeitig wird vom Lehrling (Mensch) die Autorität des Meisters (ChatGPT) anerkannt. Dieser Aspekt kann dann allerdings auch für Manipulationen durch die Künstliche Intelligenz genutzt werden.
Ein weiterer von Polanyi angesprochene Punkt ist das erforderliche Vertrauen auf der Seite des Lernenden in den Meister. Kann ein Mensch als Nutzer von Künstlicher Intelligenz Vertrauen in die KI-Systeme haben? Siehe dazu Künstliche Intelligenz – It All Starts with Trust.
Gerade wenn es um komplexe Probleme geht hat das Lernen von einer Person, gegenüber dem Lernen von einer Künstlichen Intelligenz, Vorteile. Die Begrenztheit von KI-Agenten wird beispielhaft auf der Plattform Rent a Human deutlich, wo: KI-Agenten Arbeit für Menschen anbieten, denn
„KI kann kein Gras anfassen“.
Diese Website benutzt Cookies. Wenn du die Website weiter nutzt, gehen wir von deinem Einverständnis aus.