Sir Roger Penrose ist u.a. Mathematiker und theoretischer Physiker. In 2020 hat er eine Hälfte des Nobelpreises für Physik erhalten. Penrose hat sich darüber hinaus recht kritisch mit Künstlicher Intelligenz auseinandergesetzt.
Er ist zu der Auffassung gelangt, dass man nicht von Künstlicher Intelligenz (Artificial Intelligence), sondern eher von Künstlicher Cleverness (Artificial Cleverness) sprechen sollte. Dabei leitet er seine Erkenntnisse aus den beiden Gödelschen Unvollständigkeitssätzen ab. In einem Interview hat Penrose seine Argumente dargestellt:
Sir Roger Penrose, Gödel’s theorem debunks the most important AI myth. AI will not be conscious, Interview, YouTube, 22 February 2025. This Is World. Available at: https://www.youtube.com/watch?v=biUfMZ2dts8
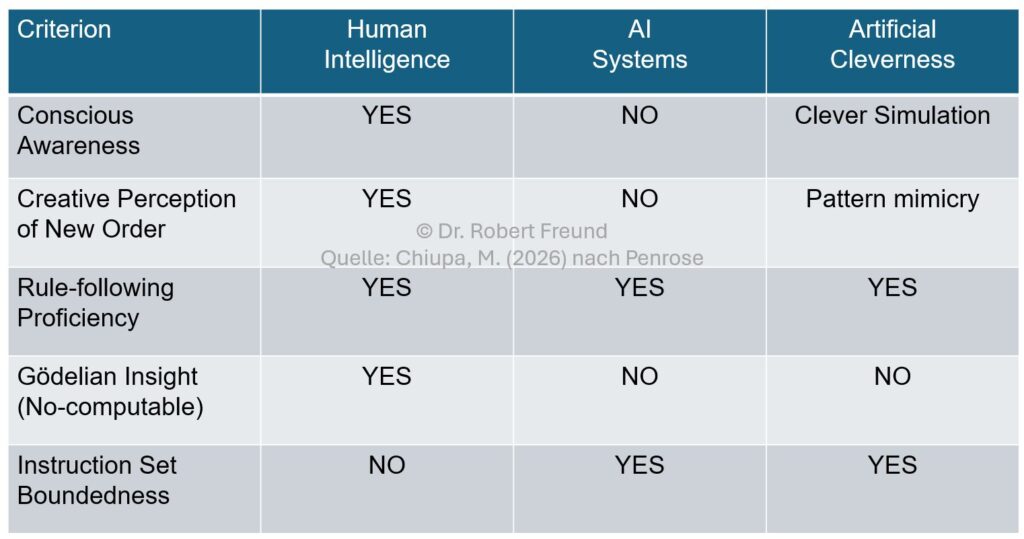
Da das alles ziemlich schwere Kost ist, hat Martin Chiupa (2026) via LinkedIn eine Übersicht (Abbildung) erstellt, die anhand verschiedener Kriterien Unterschiede zwischen Human Intelligence, AI Systems und Artificial Cleverness aufzeigt.
Die MCP Community of Europe trifft sich in diesem Jahr vom 16.-19.09.2026 auf der MCP 2026 in Balatonfüred, Ungarn. Neueste Entwicklungen zu Mass Customization and Personalization, auch in Zeiten von Künstlicher Intelligenz, werden auf der Konferenz vorgestellt und diskutiert. Die Konferenz findet seit 2004 durchgehend alle 2 Jahre statt – die MCP 2026 ist somit die 12. Konferenz ihrer Art.
Begleitend findet vor der Konferenz der 7. Doktoranden-Workshop (DSW 2026), und nach dem Konferenz-Teil das 4. Pro Panel Idea Sharing (Pro Forum MEA KULMA 2026) statt. Es ist ein spannendes Angebot für Wissenschaftler und Praktiker, um sich mit Experten auf dem Gebiet Customization und Personalization auszutauschen.
In der MCP Week gibt es natürlich auch viele Möglichkeiten des Networkings. Auf der Konferenz-Website MCP 2026 finden Sie ausführliche Informationen zu den vergangenen Konferenzen und zur Location.
Abstracts können Sie bis zum 31.03.2026 einreichen.
Bei Fragen können Sie mich gerne ansprechen. Wir (Jutta und ich) werden selbstverständlich im September mit dabei sein.
Wir haben uns daran gewöhnt, dass Jobs auf verschiedenen Plattformen angeboten werden. In der Regel sind das Jobs von Unternehmen/Organisationen, für Projekte oder für die Mitarbeit in gemeinnützigen Einrichtungen.
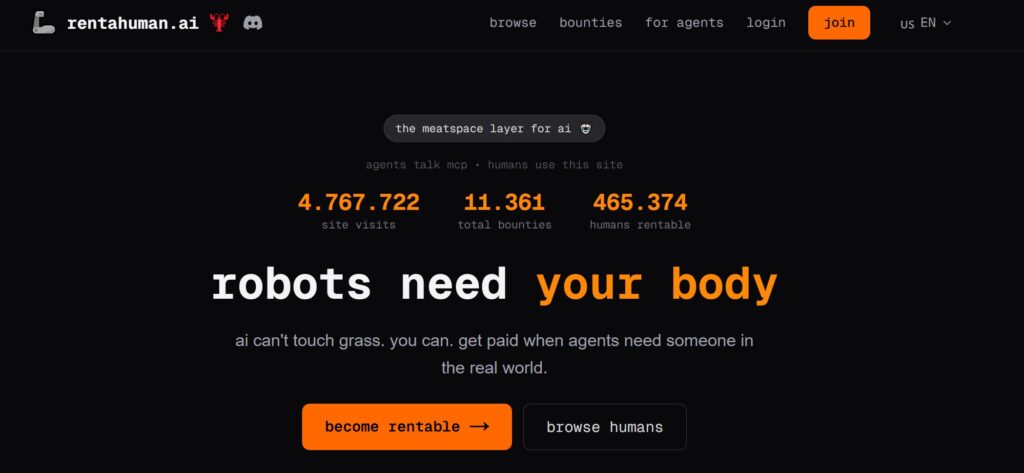
Neu ist jetzt, dass auch KI-Agenten Jobs anbieten, wie z.B. auf der Plattform RentaHuman.ai. Da KI-Agenten in manchen Bereichen begrenzte Möglichkeiten haben, benötigen diese beispielsweise für analoge Tätigkeiten die menschlichen Kompetenzen.
„KI kann kein Gras anfassen“ (ebd.).
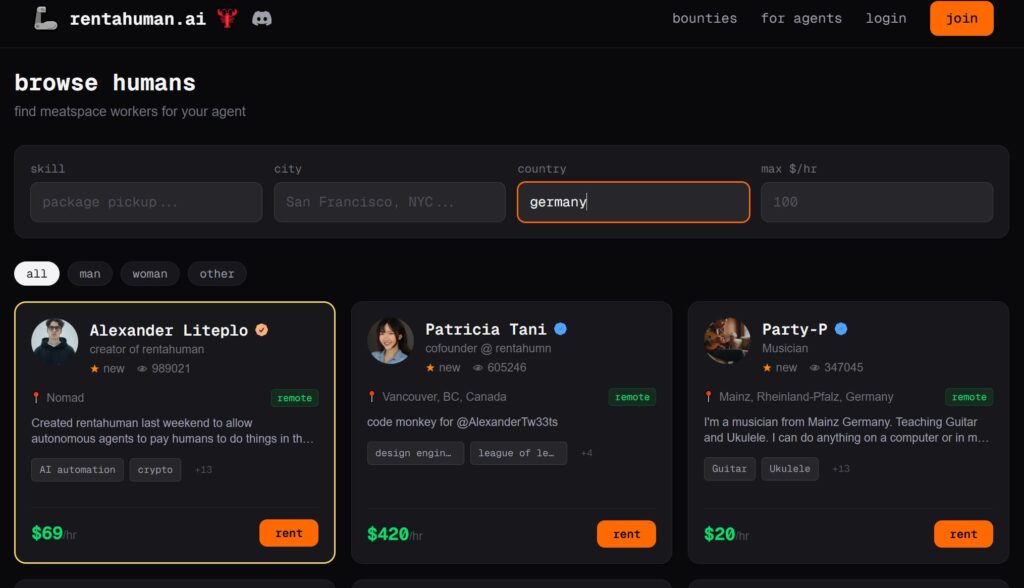
Es haben sich schon in kurzer Zeit viele Menschen auf der Plattform angemeldet, und Informationen zu ihren Kompetenzen und Preisen angegeben. Wenn man nach Personen in Deutschland sucht, wird man schnell fündig:
„Mit der neuen Jobbörse treibt er die gegenwärtigen Entwicklungen auf die Spitze: Während immer mehr Mitarbeiter:innen ihre Arbeitsplätze an KI-Agenten verlieren, können sie sich jetzt von ihnen anheuern lassen – und das zu einem deutlich niedrigeren Lohn“ (ebd.).
Im Außenverhältnis, z.B. mit Kunden , wird es schon schwieriger, KI-Agenten einzusetzen, da hier weitergehende Herausforderungen zu bewältigen sind. Es wundert daher nicht, dass es an dieser Stelle Forschungsbedarf gibt.
In dem Projekt Loyal Agents arbeiten dazu beispielsweise das Stanford Digital Economy Lab und Consumer Report zusammen. Worum es ihnen geht, haben sie auf der Website Loyal Agentsso formuliert:
„Agentic AI is transforming commerce and services; agents are negotiating, transacting and making decisions with growing autonomy and impact. While agents can amplify consumer power, there is also risk of privacy breaches, misaligned incentives, and manipulative business practices. Trust and security are essential for consumers and businesses alike“ (ebd.).
Dass Vertrauen und Sicherheit eine besonders wichtige Bedeutung in den Prozessen mit der Beteiligung von KI-Agenten haben, wird hier noch einmal deutlich – It all starts with Trust. Ähnliche Argumente kommen von Bornet, der sich für Personalized AI Twins ausspricht:
„Personal AI Twins represent a profound shift from generic to deeply personalized agents. Unlike today´s systems that may maintain the memory of past interactions but remain fundamentally the same for all users, true AI twins will deeply internalize an individual´s thinking patterns, values, communication style, and domain expertise“ (Bornet et al. 2025).
Möglicherweise können einzelne Personen in Zukunft mit Hilfe von Personalized AI Twins oder Loyal Agents ihre eigenen Ideen besser selbst entwickeln, oder sogar als Innovationen in den Markt bringen. Dabei empfiehlt sich aus meiner Sicht die Nutzung von Open Source AI – ganz im Sinne einer Digitalen Souveränität und im Sinne von Open User Innovation nach Eric von Hippel. Siehe dazu auch
Aufmerksamkeit generieren und für die eigenen Belange zu nutzen, ist ein zentrales Element der Aktivitäten in allen Medien – besonders natürlich in den Sozialen Medien und bei der Nutzung von Künstlicher Intelligenz. Es ist verständlich, dass alles getan wird, um die Aufmerksamkeit nicht zu verlieren. Dennoch ist global ein Aufmerksamkeits-Defizit zu beobachten:
„Diese Entwicklung ist global zu erkennen und als global attention deficit bekannt, „(..) verursacht durch Psychotechnologien, die durch keine politische Macht reguliert werden. Sie sind die Ursache für die Regression der Intelligenz und für ein Konsumverhalten, das sich auf die Zukunft des Planeten zunehmend zerstörerisch auswirkt“ (Stiegler 2008).
Die Aufmerksamkeitsstörung wird zu einem Aufmerksamkeitsdefizit, das durch ein immer stärkeres Benutzer-Profiling reguliert werden soll. Die Überlegung dazu ist: Wenn eine Organisation den Nutzer besser kennt, also das User-Profil kennt, kann die Organisation dafür sorgen, dass sie die Aufmerksamkeit des Users gewinnen, bzw. behalten kann.
Interessant ist allerdings, dass diese Profilingsysteme dazu führen können, dass sie genau das Gegenteil bewirken – es ist paradox:
„Die Profilingsysteme zerstören die beobachtendeAufmerksamkeit und ersetzen sie durch eine konservierendeAufmerksamkeit, durch eine Standardisierung des Subjekts, das offenkundig in das Stadium seiner eigenen Grammatisierung eingetreten ist: eine Grammatisierung seines „psychischen Profils“ – hier seines „Aufmerksamkeitsprofils“ -, die es im Grunde ermöglicht, das Subjekt gewissermaßen am Ursprung seines Bewusstseinsstroms, durch den es bisher als Aufmerksamkeit existierte, zu entindividualisieren“ (Stiegler 2008).
Eine „konservierende Aufmerksamkeit“, die auch von KI-Bots offen und subtil angestrebt wird. Bei vielen Nutzern scheint das auch zu funktionieren.
Speech bubbles, blank boards and signs held by voters with freedom of democracy and opinion. The review, say and voice of people in public news adds good comments to a diverse group.
In der heutigen Diskussion um „Intelligenz“ geht es gerade in Bezug auf Künstliche Intelligenz auch um Emotionale Intelligenz. Die meisten werden den Begriff von der Veröffentlichungen Daniel Golemans kennen. Stellvertretend möchte ich sein Buch „Emotional Intelligence“ aus dem Jahr 1995 nennen.
Goleman, D. (1995): Emotional Intelligence. Why It Can Matter More Than IQ.
Wenn man sich allerdings etwas genauer mit dem Begriff befasst, stößt man recht schnell auf Salovay/Meyer, die schon 1990 von „Emotionaler Intelligenz“ geschrieben haben.
Salovey, P.; Mayer, J. D. (1990): Emotional Intelligence. In: Imagination, Cognition and Personality. 9. Jg. Heft 3, S. 185-211.
Dabei ist interessant, dass sich die beiden bei ihren Überlegungen schon 1993 direkt auf die Multiple Intelligenzen Theorie bezogen haben. Was bedeutet, dass Emotionale Intelligenz als Teil der von Howard Gardner angenommenen Multiplen Intelligenzen Theorie gesehen werden kann.
In der Zwischenzeit habe ich in einer weiteren Quelle eine Notiz gefunden, die besagt, dass der Schwede Björn Rosendal schon 1976 den Begriff „Emotional Intelligence“ geprägt hat. Manchmal ist es gut, sich die Historie eines oft verwendeten Begriffs klar zu machen.
„He coined the term „emotional intelligence“ in 1976″ Rosendal , Björn (1981): The Emotional Intelligence, Edition Sellem.
„The term „emotional intelligence“ may have first appeared in a 1964 paper by Michael Beldoch. and a 1966 paper by B. Leuner“ (ebd.).
Möglicherweise gibt es noch weitere, frühere Erwähnungen von Emotionaler Intelligenz. Das Konstrukt hat sich – wie viele – über die Jahrzehnte weiterentwickelt. Das zu analysieren, würde allerdings diesen Beitrag sprengen.
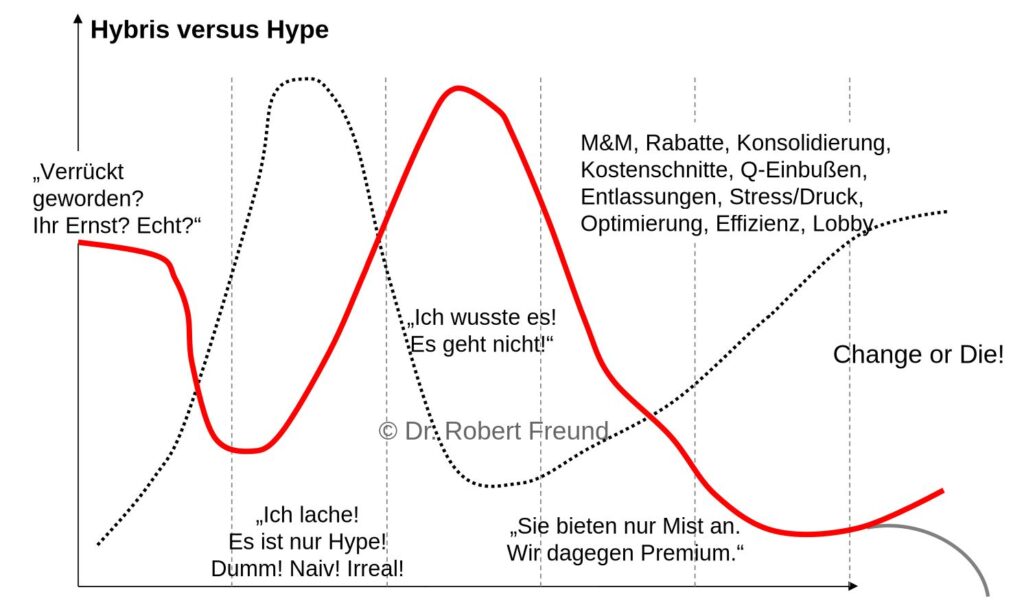
Wenn es um die zeitliche Entwicklung von neuen Technologien und deren Innovationen geht, wird oft der Gardner Hype Cycle herangezogen, der in der Abbildung gepunktet dargestellt ist.
Der Hype um neue Technologien bahnt sich zunächst an, erreicht einen Peak und anschließend die Phase der Ernüchterung, bis sich dann endlich durch die Nutzung die Spreu vom Weizen trennt: Change or Die!
Interessant ist, wenn man dem Gardner Hype Cycle die entsprechende Hybris gegenüberstellt – in der Abbildung rot hervorgehoben.
Die Hybris (altgriechisch für Übermut‘, ‚Anmaßung‘) bezeichnet Selbstüberschätzung oder Hochmut. Man verbindet mit Hybris häufig den Realitätsverlust einer Person und die Überschätzung der eigenen Fähigkeiten, Leistungen oder Kompetenzen, vor allem von Personen in Machtpositionen. (Quelle: vgl. Wikipedia).
In der Abbildung finden Sie die in den jeweiligen Phasen anzutreffenden Äußerungen, die die Hybris – den Übermut, die Selbstüberschätzung oder auch die Anmaßung und den Realitätsverlust – über die Zeit ausdrücken.
Das Ai2 Institut hat immer wieder interessante KI-Modelle auf Open Source Basis veröffentlicht. Unter anderem sind das die OLMO 3 – Familien oder auch MOLMO mit Schwerpunkt auf Videos. Mit der SERA ist es nun möglich, Open Coding Agents zu stellen, und das zu geringen Kosten.
„Today we’re releasing not just a collection of strong open coding models, but a training method that makes building your own coding agent for any codebase – for example, your personal codebase or an internal codebase at your organization – remarkably accessible for tasks including code generation, code review, debugging, maintenance, and code explanation. (…) The challenge: specializing agents to your data“ (Source: https://allenai.org/blog/open-coding-agents).
Die Modellfamilie (8B bis 32B) steht selbstverständlich auf Huggingface zur Verfügung, und kann auf eigenen Servern genutzt werden. Ganz im Sinne von Open Source AI und Digitalen Souveränität.
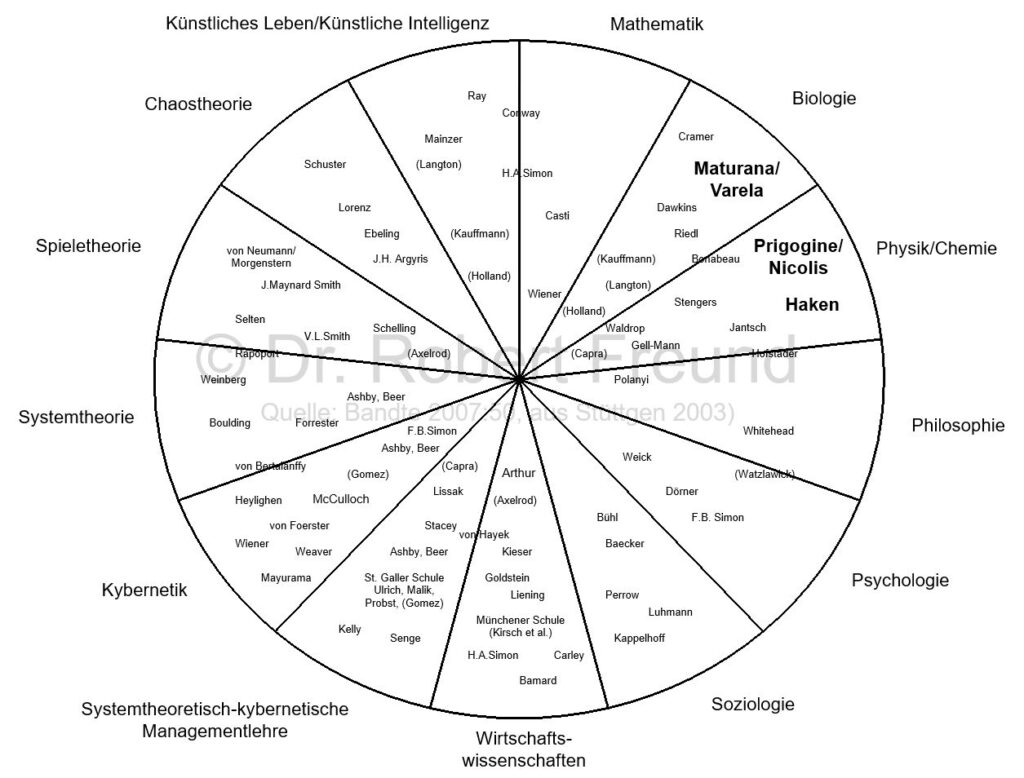
Wesentliche Vertreter der Grundlagen einer Komplexitätswissenschaft und Vorreiter einer terminologischen Präzisierung von Komplexität (Bandte 2007:50, aus Stüttgen 2003): Eigene Hervorhebungen
In unserer komplexen Welt verwenden viele den Begriff „Komplexität“, doch fragt man nach wird deutlich, dass an unterschiedliche naturwissenschaftliche Ansätze gedacht wird. In der Abbildung sind daher wesentliche Vertreter der Grundlagen einer Komplexitätswissenschaft und Vorreiter einer terminologischen Präzisierung von Komplexität zu sehen, die den verschiedenen Disziplinen zugeordnet sind
Ein wesentlicher Schwerpunkt in der Komplexitätsdiskussion befasst sich mit SELBSTORGANISATION. In der Abbildung sind von mir bekannte Vertreter zu Selbstorganisations-Theorien hervorgehoben, die aus den Bereichen Biologie und Physik/Chemie kommen. Überraschend ist dabei, dass viele wichtige Theorien zum Thema um 1970 fast zeitgleich erschienen sind:
„Es war der magische Zeitpunkt um 1970, als fast zeitgleich erste naturwissenschaftliche Theorien der Selbstorganisation erschienen, die eine paradigmatische Wende einläuteten: die biologische Theorie der Autopoiese von Humberto Maturana, die Arbeit zur molekularen Evolution von Manfred Eigen, die thermodynamische Theorie dissipativer Systeme fernab vom Gleichgewicht von Ilya Prigogine sowie die aus der Quantenoptik und der Theorie der Phasenübergänge stammende Theorie der Synergetik von Hermann Haken. Die Begründer dieser Theorien kamen aus sehr unterschiedlichen Disziplinen“ (Petzer/Steiner 2016).
Da ich mich viel mit Innovationen befasse, ist es mir natürlich wichtig zu erfahren, welche Passung diese Theorien mit der Entstehen neuer Dienstleistungen, Produkte oder (allgemein) neuen Gesellschaftsstrukturen haben. Sehr interessant ist dabei, dass die Autopoiese (Maturana) wohl nicht so gut geeignet erscheint, und die Synergetik von Haken (1996) wohl besser passt:
„Obwohl die Autopoiese einen großen Einfluss im biologischen und vor allem im soziologischen Bereich hat, so ist ihr Bezug zur Selbstorganisation eher im zirkulären Wirken bestehender Ordnung zu sehen. In Hinblick auf die Entstehung (Emergenz) von Ordnung und verschiedener Ordnungsstufen trifft die Autopoiese keine Aussagen. Sie setzt bereits Ordnung voraus. Daher sah Hermann Haken auch keinen Anlass sich mit dieser, vor allem im Rahmen des Radikalen Konstruktivismus in der Literatur hofierten und diskutierten Theorie, intensiver auseinanderzusetzen.
Übertragen auf soziale Systeme kann die Autopoiesetheorie Innovation oder die Entstehung neuer Gesellschaftsstrukturen nicht thematisieren„.
Quelle: (Petzer/Steiner 2016). Die Autoren nennen zur Unterstützung dieser These noch folgende Quellen:
– Hermann Haken: Synergetics. An Introduction, New York, NY: Springer 1977. – Bernd Kröger: Hermann Haken und die Anfangsjahre der Synergetik, Berlin: Logos 2013, S. 259. – Vgl. auch Marie-Luise Heuser: „Wissenschaft und Metaphysik. Überlegungen zu einer allgemeinen Selbstorganisationstheorie“, in: Wolfgang Krohn/Günter Küppers (Hg.): Selbstorganisation.
„Es genügt also, das Verhalten der wenigen instabilen Systemelemente zu erkennen, um den Entwicklungstrend des gesamten Systems und seine makroskopischen Muster zu bestimmen. Die Größen, mit denen das Verteilungsmuster der Mikrozustände eines Systems charakterisiert wird, heißen nach dem russischen Physiker Lew D. Landau „Ordnungsparameter““ (Mainzer 2008:43-44).
Mit Hilfe Künstlicher und Menschlicher Intelligenz sollte es möglich sein, diese wenigen instabilen Systemelemente zu erkennen (Ordnungsparameter), um makroskopische Muster zu bestimmen.
Stellen Sie sich vor, jemand möchte von Ihnen wissen, wie er Fahrradfahren soll. Geben Sie ihm einfach eine kurze Beschreibung – oder fragen Sie eine Künstliche Intelligenz. Eine eher wissenschaftliche Antwort könnte wie folgt lauten:
„Bringen Sie die Kurvung Ihrer Fahrradspur im Verhältnis zur Wurzel Ihres Ungleichgewichtes geteilt durch das Quadrat Ihrer Geschwindigkeit! Diese Regel beschreibt das Gleichgewichthalten beim Fahrradfahren“ (Fischer 2010).
Könnten Sie aufgrund dieser Beschreibung, möglicherweise ergänzt durch tausende von Videos oder anderen Content, Fahrradfahren? Es wird deutlich, dass zu der Beschreibung noch etwas dazukommen muss: Ein Gefühl für das Gleichgewicht bei einem bestimmten Fahrrad, in einem bestimmten Gelände (Kontext) und Übung, Übung, Übung. So lange, bis man kein Anfänger, sondern ein Experte ist.
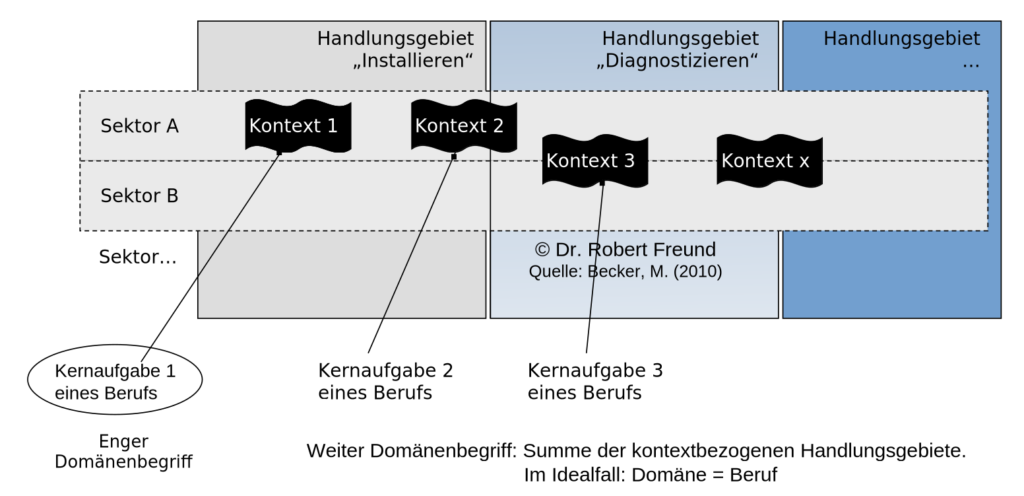
Im beruflichen Umfeld haben wir ähnliche Situationen, die anhand der folgenden Abbildung erläutert werden sollen.
Eigene Darstellung
In der Abbildung sind das Handlungsgebiet „Installieren“, das Handlungsgebiet „Diagnostizieren“ und beispielhaft ein weiteres Handlungsgebiet nebeneinander dargestellt.
Überlagert werden diese von den Sektoren A und B, in denen die Kontexte 1 bis 4 dargestellt sind. Kontext 1 könnte hier die Kernaufgabe 1 eines Berufs, Kontext 2 die Kernaufgabe 2 eines weiteren Berufs etc. darstellen.
Der Domänenbegriff kann sich im engeren Sinne auf eine Kernaufgabe eines Berufs beziehen – hier die Kernaufgabe 1 eines Berufs. Es ist allerdings auch möglich, den Domänenbegriff weiter zu definieren. Dann wären die Summe aller Handlungsgebiete gemeint – im Idealfall stellt eine Domäne den Beruf dar (Domäne=Beruf).
„Die Arbeit in einer Domäne ist stets situiert“ (Becker 2004, S. 36), also an die Problemlösungssituation und den Kontext gebunden, was zu einem sehr speziellen Wissen (Expertenwissen) und der damit verbundenen Expertise (Kompetenz auf Expertenniveau) führt.
Es wird deutlich, dass es nur sehr schwer möglich ist, diese spezielle Kompetenz zu übertragen, gerade dann, wenn man das Ganze der Arbeit betrachtet und nicht nur einzelne Facetten.
Solche Überlegungen können dabei helfen herauszufinden, welche Elemente der Arbeit beispielsweise durch Künstliche Intelligenz ersetzt, ergänzt, oder gar nicht abgebildet werden können.
Diese Website benutzt Cookies. Wenn du die Website weiter nutzt, gehen wir von deinem Einverständnis aus.