Wenn wir uns die Entwicklungen der Künstlichen Intelligenz in der letzten Zeit ansehen, so fällt auf, dass es mehrere Trends gibt.
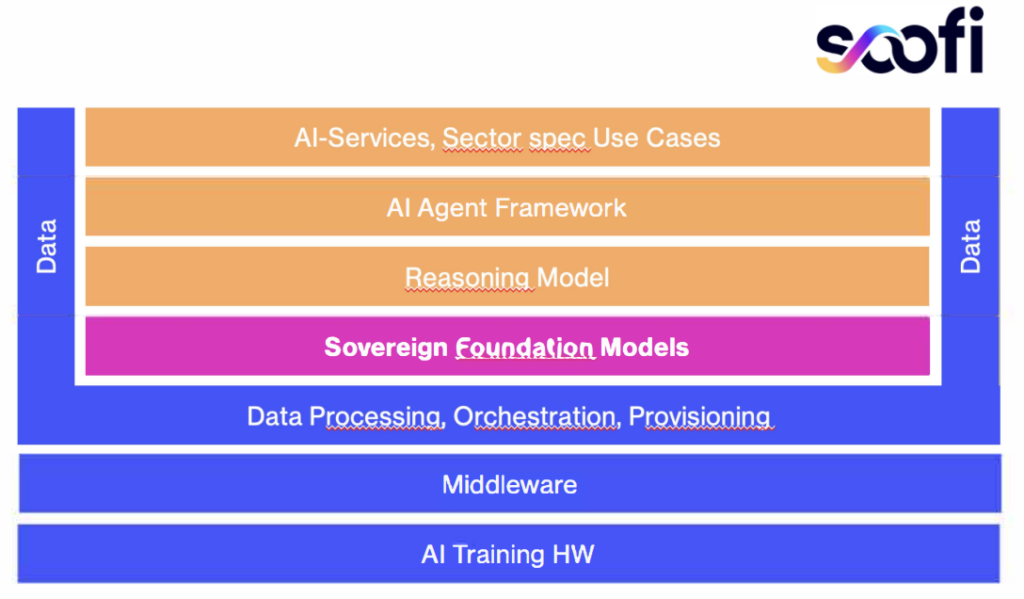
Neben den dominierenden wenigen großen Large Language Models (LLMs) der Tech-Konzerne gibt es immer mehr kleine Modelle (Small Language Models), die je nach Anwendungsfall ausgewählt werden können. Solche SLM sind flexibler, kostengünstiger und in bestimmten Bereichen sogar besser. Siehe dazu auch KI-Modelle: Von „One Size Fits All“ über Variantenvielfalt in die Komplexitätsfalle?
Weiterhin wird für solche Problemlösungen auch viel weniger Energie benötigt, was die weltweiten, aber auch die unternehmensspezifischen Ressourcen/Kosten schont, Siehe dazu auch Künstliche Intelligenz: Das menschliche Gehirn benötigt maximal 30 Watt für komplexe Problemlösungen.
Darüber hinaus gibt es auch immer mehr leistungsfähige Open Source KI-Modelle, die jedem zur Verfügung stehen, und beispielsweise eher europäischen Werten entsprechen. Siehe dazu auch Das Kontinuum zwischen Closed Source AI und Open Source AI
Wenn also in Zukunft mehr als 1 Milliarde Menschen Künstliche Intelligenz nutzen, stellt sich gleich die Frage, wie Unternehmen damit umgehen. Immerhin war es üblich, dass so eine Art der intelligenten komplexen Problemlösung bisher nur spärlich – und dazu auch noch teuer – zur Verfügung stand.
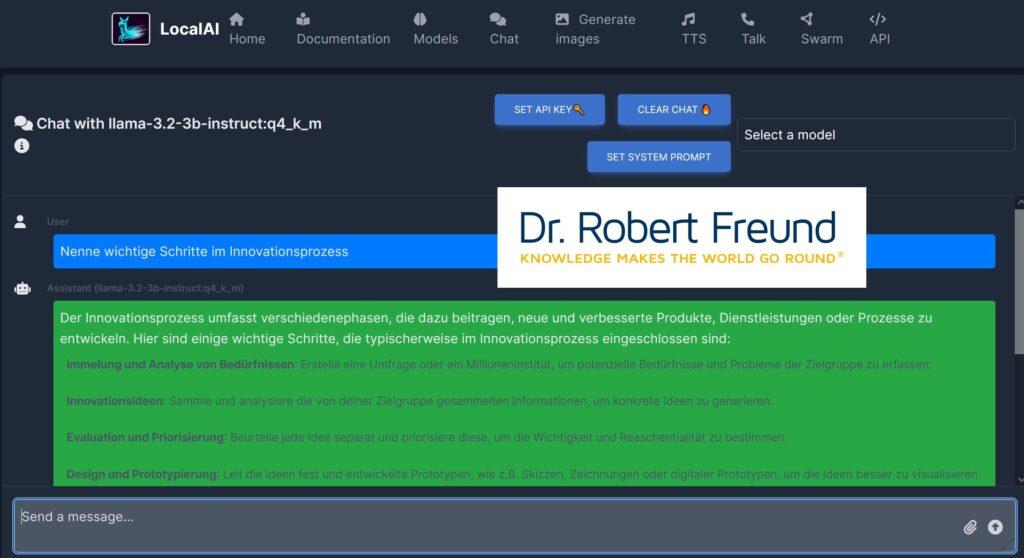
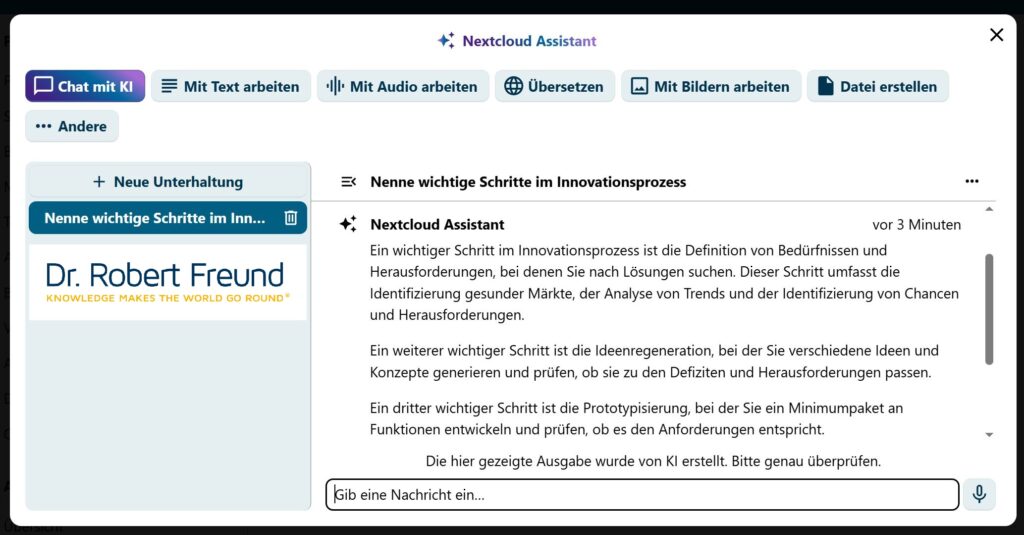
Nun werden Milliarden von einzelnen Personen die Möglichkeit haben, mit geringen Mitteln komplexe Problemlösungen selbst durchzuführen. Prof. Ethan Mollick nennt dieses Phänomen in einem Blogbeitrag Mass Intelligence.
„The AI companies (whether you believe their commitments to safety or not) seem to be as unable to absorb all of this as the rest of us are. When a billion people have access to advanced AI, we’ve entered what we might call the era of Mass Intelligence. Every institution we have — schools, hospitals, courts, companies, governments — was built for a world where intelligence was scarce and expensive. Now every profession, every institution, every community has to figure out how to thrive with Mass Intelligence“ (Mollick, E. (2025): Mass Intelligence, 25.08.2025).
Ich bin sehr gespannt, ob sich die meisten Menschen an den proprietären großen KI-Modellen der Tech-Konzerne orientieren werden, oder ob es auch einen größeren Trend gibt, sich mit KI-Modellen weniger abhängig zu machen – ganz im Sinne einer Digitalen Souveränität.