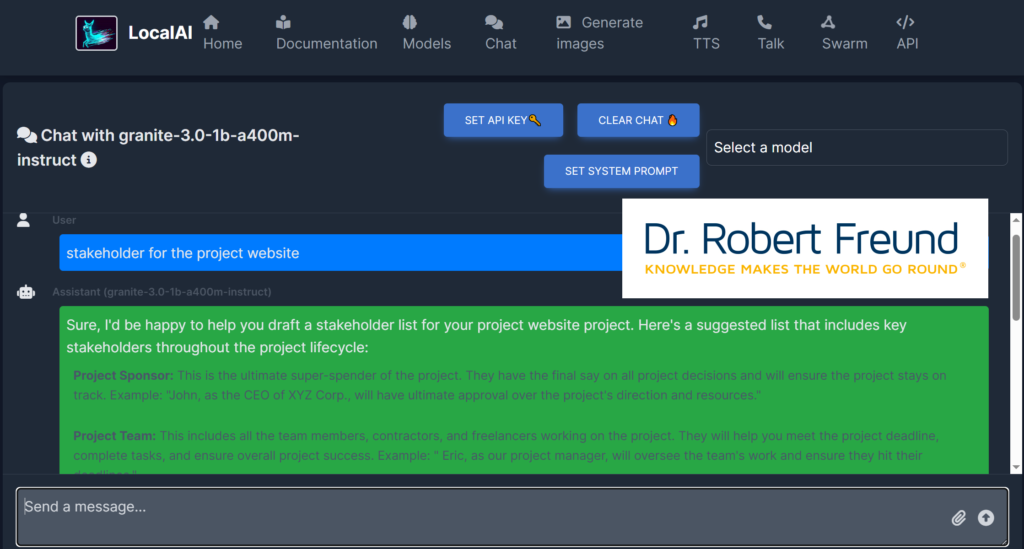
Auf unseren Servern haben wir LocalAI installiert, das wir über den Nextcloud Assistenten in allen Nextcloud-Anwendungen nutzen können. Dabei bleiben alle Daten auf unserem Server.
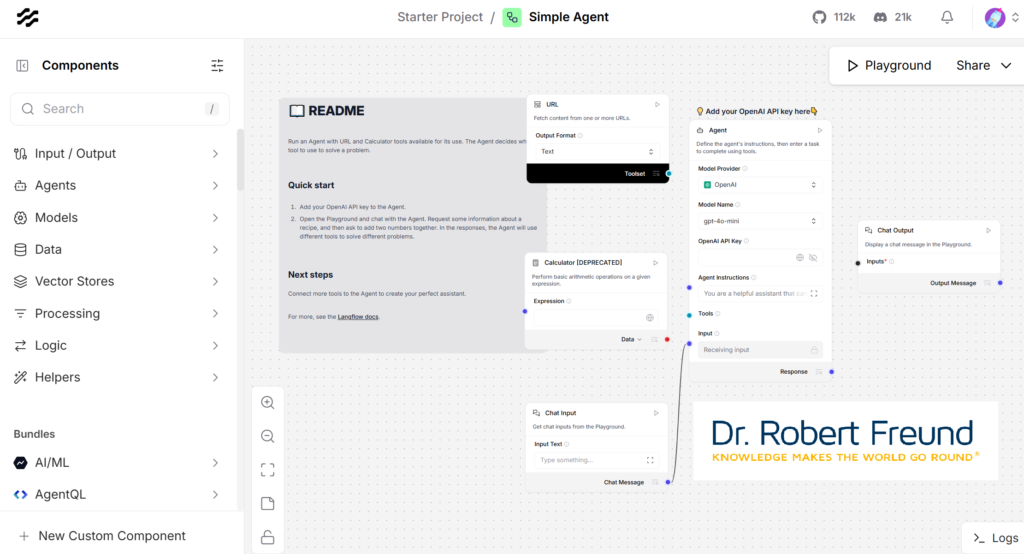
Weiterhin arbeiten wir an KI-Agenten, die wir in Langflow entwickeln. Dazu greifen wir auf Modelle zurück, die wir in Ollama installiert haben. Auch Langflow und Ollama sind auf unserem Servern installiert, sodass auch hier alle Daten bei uns bleiben.
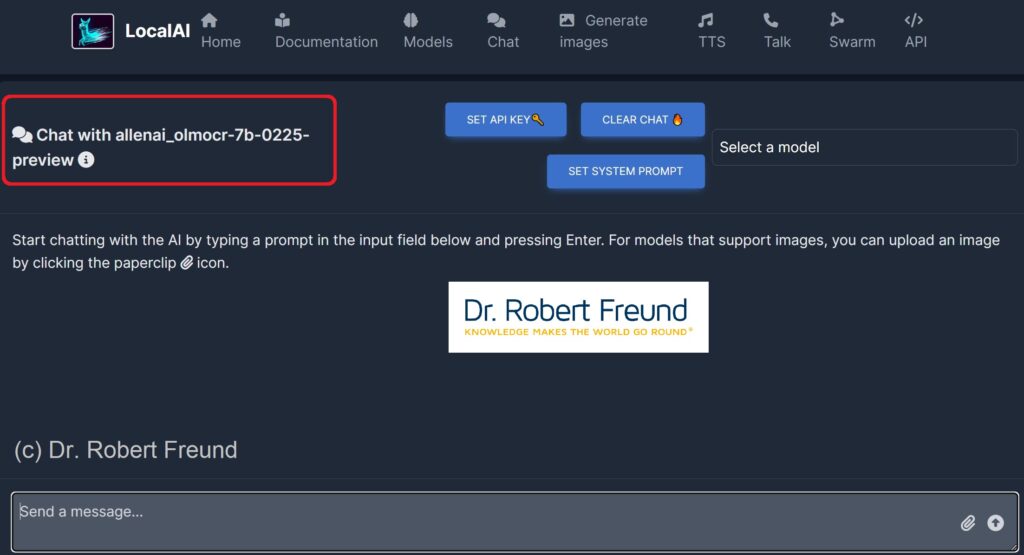
In Ollama haben wir nun ein weiteres Modell installiert, das aus einer ganzen OLMo2-Familie stammt. In der Abbildung ist zu erkennen, dass wir OLMo2:latest installiert haben. Wir können nun auch das Modell in Ollama testen und dann später – wie schon angesprochen – in Langflow in KI-Agenten einbinden.
Alle Modelle, die wir auf unseren Servern installieren, sollen den Anforderungen einer Open Source AI entsprechen. Manchmal nutzen wir auch Open Weights Models, um zu Testzwecken die Leistungsfähigkeit verschiedener Modelle zu vergleichen. Siehe dazu Das Kontinuum zwischen Closed Source AI und Open Source AI.
Das Modell OLMo2:latest ist ein Modell, aus einer Modell-Familie, dass im wissenschaftlichen Umfeld / Forschung eingesetzt werden kann.
„OLMo is Ai2’s first Open Language Model framework, intentionally designed to advance AI through open research and to empower academics and researchers to study the science of language models collectively“ (Ai2-Website).
An diesem Beispiel zeigt sich, dass es einen Trend gibt: Weg von einem Modell, das alles kann – one size fits all. In Zukunft werden immer mehr Modelle gefragt und genutzt werden. die sich auf eine bestimmte berufliche Domäne (Forschung, Wissenschaft etc.) fokussieren und dadurch bessere Ergebnisse erzielen und weniger Ressourcen benötigen.
Siehe dazu auch KI-Modelle: Von “One Size Fits All” über Variantenvielfalt in die Komplexitätsfalle?