Die Nutzung den bekannten KI-Modelle (GenAI) wie ChatGPT, Gemini, Grok, Anthropic, Claude etc ist weit verbreitet. Es ist auch möglich, diese Modelle mit eigenen Daten zu trainieren, doch ist der Großteil dann immer noch zu wenig unternehmensspezifisch. Siehe dazu auch Digitale Souveränität: Europa, USA und China im Vergleich.
Mistral AI ist hier in den letzten Jahren einen eigenen Weg gegangen, indem es als europäische Modell Familie DSGVO-konform ist, und auch als Open Source AI zur Verfügung steht.
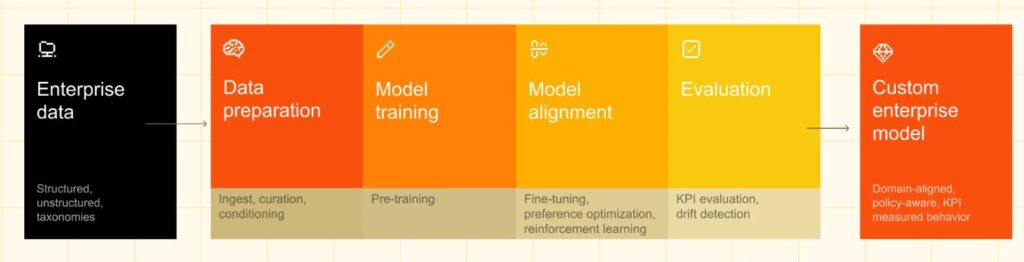
Mit dem nun veröffentlichten Mistral Forge können Unternehmen auf Basis der eigenen Daten und Expertise ihr eigenes KI-Modell entwickeln.
From your data to your model
Vorgehensweise bei Mistral Forge: https://mistral.ai/products/forge
Die einzelnen Schritte werden auf der genannten Webseite ausführlich dargestellt. Es wir spannend zu sehen, welche Organisationen diesen Weg gehen werden. Aktuell sind das immerhin so bekannte Namen wie ASML, Ericsson, ESA und DSO National Laboratories aus Singapur. Siehe dazu auch
Die vielfältigen Abhängigkeiten Europas, u.a. bei Energie und Digitalisierung sind in der Zwischenzeit allen leidvoll bewusst geworden. In den letzten Jahren wird daher immer mehr versucht, auf unabhängige Lösungen zu setzen.
Das bedeutet bei der Energie natürlich, erneuerbare Energie auszubauen. Bei der Digitalisierung geht es um eine weitgehende Digitale Souveränität. In vielen europäischen Verwaltungen werden auch schon erste erfolgreiche Schritte sichtbar.
Vielen Verwaltungen wird langsam aber sicher auch klar, wie viel Geld sie an Rahmenverträgen, Lizenzen und Software an Big-Tech gezahlt zahlen müssen. Es sind in Deutschland 13,6 Milliarden Euro pro Jahr (Quelle: Golem 04.07.2025).
In der Zwischenzeit gibt es viele Open Source Anwendungen die als Alternativen zur Verfügung stehen. Das dänische Digitalministerium ersetzt beispielsweise Microsoft Office durch Libre Office, Schleswig-Holstein setzt in der Verwaltung auf Nextcloud usw. usw.
Einen Schritt weiter geht die Österreichische Verwaltung, die in Zukunft verstärkt Künstliche Intelligenz einsetzen will. Dabei hat man sich im Sinne der genannten Überlegungen für ein europäisches (französisches) KI-Modell entschieden: DSGVO-konform und Open Source.
„Gerade beim Einsatz von KI im Staat ist digitale Souveränität entscheidend. Deshalb arbeiten wir an einer gemeinsamen Infrastruktur, die unsere Daten schützt und gleichzeitig Innovation ermöglicht.“ Deshalb laufen auf den GPUs im Bundesrechenzentrum auch bevorzugt europäische Modelle – also etwa Mistral AI aus Frankreich. Dies soll volle Souveränität über die Daten garantieren“ (Zellinger, P. (2026): Es wird ernst: Künstliche Intelligenz zieht in die österreichische Verwaltung ein, in Der Standard vom 10.03.2026.
In dem Beitrag wird auch erwähnt, dass für nicht so sicherheitsrelevante Bereiche auch andere KI-Modelle genutzt werden können. Doch was ist in Öffentlichen Verwaltungen nicht sicherheitsrelevant?
Langflow ist Open Source basiert und bietet die Möglichkeit, einfache Flows oder auch komplexere KI-Agenten per Drag & Drop zu erstellen.
„Langflow is a powerful tool to build and deploy AI agents and MCP servers. It comes with batteries included and supports all major LLMs, vector databases and a growing library of AI tools“ (Langflow-Website).
Wir haben Langflow auf einem Server installiert, und einige Tests dazu durchgeführt – inkl. der Nutzung von Ollama. Unser Ziel ist es mit einfachen Tools, die Open Source basiert sind und kleine, frei verfügbare Trainingsmodelle (Small Language Models) zu nutzen. Siehe dazu unsere Blogbeiträge zu Langflow.
In diese Richtung geht nun auch die Möglichkeit, Langflow auf dem eigenen Desktop zu nutzen. Dazu kann man sich auf dieser Website die App herunterladen und installieren.
Der Vorteil liegt auf der Hand: Es ist kein Server erforderlich, auf dem Langflow installiert werden muss. Der Nachteil ist allerdings auch klar: Je nach Hardware-Ausstattung des eigenen Desktops sind die Möglichkeiten zur Nutzung größerer Modelle (Large Language Models) noch begrenzt. Wir werden es auf jeden Fall einmal ausprobieren.
Die dort oftmals hinterlegten Daten, die natürlich zum überwiegenden Teil in Englisch (oder Chinesisch) vorliegen, spiegeln nicht die vielfältige europäische Kultur mit ihren vielen Nuancen wieder. Kulturelle Bereiche, definieren sich oftmals über die jeweilige Sprache.
Es ist daher nicht verwunderlich, dass es in den jeweiligen europäischen Ländern einen Trend gibt, KI-Modelle zu entwickeln, die die jeweilige sprachlichen Besonderheiten beachten – wie z.B. Minerva AI LLM:
Minerva AI LLM is the first family of Large Language Modelspretrained from scratch in Italian developed by Sapienza NLP in collaboration with Future Artificial Intelligence Research (FAIR) and CIN AIECA. The Minerva models are truly-open (data and model) Italian-English LLMs, with approximately half of the pretraining data composed of Italian text. You can chat with Minerva for free directly through the app — it’s easy, fast, and open to everyone.
Es handelt sich also um eine Modell-Familie, die offen für jeden nutzbar ist. Es zeigt sich auch hier wieder, dass Künstliche Intelligenz auf Vertrauen basieren muss, damit sie den gesellschaftlichen und wirtschaftlichen Anforderungen gerecht werden kann. Siehe dazu auch beispielhaft
OpenProject ist schon lange eine Alternative zu den proprietären Projektmanagement-Tools wie MS Project oder Jira etc. Die Integration von OpenProject in Nextcloud führt zu einer Kollaborationsplattform, bei der alle Daten auf dem eigenen Server bleiben und alle Anwendungen Open Source basiert sind. Siehe dazu unsere verschiedenen Blogbeiträge zu OpenProject.
Mit der Integration von OpenProject mit Nextcloud (Alternative zu Microsoft Sharepoint), inkl. TALK als Videokonferenzsystem (Alternative zu Microsoft Teams) etc. wurde schon ein wesentlicher Schritt in Richtung Digitale Souveränität am Arbeitsplatz gemacht.
Bei der Version OpenProject 17.2 gibt es eine Weiterentwicklung die es ermöglicht, Künstliche Intelligenz (Large Language Models oder Small Language Models) über einen sicheren MCP Server in die eigenen Projekte einzubinden.
MCP (Model Context Protocol) ist ein offener Standard von Anthropic über den LLM und externe Tools via APIs oder eigene Datenquellen eingebunden werden können.
Wie Sie wissen, schlagen wir in unseren Blogbeiträgen immer vor, Open Source AI und Open Source Software zu verwenden – möglichst auf dem eigenen Server. Dann bleiben alle Daten bei Ihnen und werden nicht von anderen genutzt – ganz im Sinne der Digitalen Souveränität.
Auf die neue Mistral 3 KI-Modell-Familie hatte ich schon im Dezember 2025 in einem Blogbeitrag hingewiesen. Das französische Start-Up wurde 2023 gegründet: „(…) the company’s mission of democratizing artificial intelligence through open-source, efficient, and innovative AI models, products, and solutions“ (Quelle: Website).
Dieses Demokratisieren von Künstlicher Intelligenz durch Open Source, als europäischer und DSGVO-konformer Ansatz, ist genau der Weg, den ich schon in verschiedenen Beiträgen vertreten habe. Es ist daher interessant, auch den in 2024 veröffentlichten Bot Le Chat im Vergleich beispielsweise zu ChatGPT zu testen.
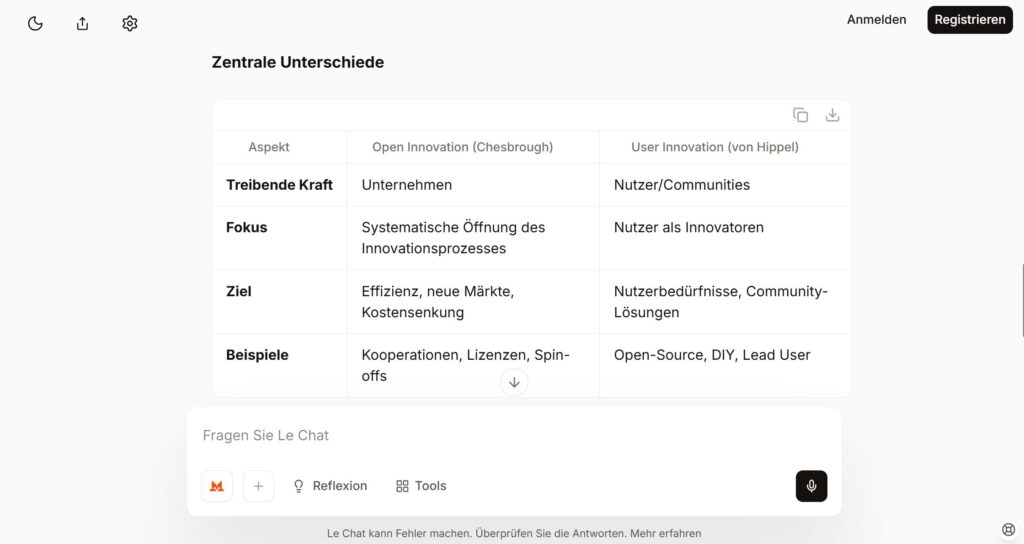
Die Abbildung weiter oben zeigt die Landingpage für Le Chat mit einem einfachen Feld für die Eingabe eines Prompts. Man kann die Leistungsfähigkeit des Bots testen, ohne sich anmelden zu müssen. Ich habe mich also zunächst nicht angemeldet und einfach einmal eine Frage eingegeben, die mich aktuell beschäftigt: Es geht um die Unterschiede zwischen den Auffassungen von Henry Chesbrough und Eric von Hippel zu Open Innovation.
Ausschnitt aus der Antwort zum eingegebenen Prompt
Die Abbildung zeigt einen Ausschnitt aus der umfangreichen Antwort auf meine Frage, inkl. der generierten Gegenüberstellung der beiden Ansichten auf Open Innovation. Die Antwort kam sehr schnell und war qualitativ gut – auch im Vergleich zu ChatGPT.
Mistral Le Chat ist ein europäisches Produkt, das auch der DSGVO unterliegt und darüber hinaus neben französisch- und englischsprachigen, auch mit deutschsprachigen Daten trainiert wurde. Es ist spannend, sich mit den Mistral-KI-Modellen und mit Le Chat intensiver zu befassen.
Wir haben den kostenpflichtigen ChatGPT-Account in der Zwischenzeit gekündigt, und werden mehr auf Modell-Familien wie Mistral 3 und MistralLe Chat setzen. Wir sind gespannt, wie sich die Open Source Alternativen in Zukunft weiterentwickeln – ganz im Sinne einer Digitalen Souveränität. Siehe dazu auch
Vor fast 20 Jahren haben wir den Blog mit WordPress (Open Source) gestartet – ohne Webebanner oder versteckter Werbung. Das ist auch heute noch so.
Von Anfang an haben wir Wert auf Qualität der Beiträge gelegt, indem wir beispielsweise Originaltexte mit Quellen angegeben, und dadurch von unserer Meinung abgegrenzt haben.
In der Zwischenzeit werden wir alle von KI generierten Inhalten überschwemmt. Da ist es aus unserer Sicht gut, mehr auf Qualität, als auf Quantität zu setzen. Ganz im Sinne von unserer Marke:
Wir haben uns alle mehr oder weniger daran gewöhnt, die verschiedenen Apps von Google zu nutzen. Ob es der Browser Chrome ist, Google Drive, etc. oder auch Google Maps . Wie ich schon in mehreren Beiträgen geschrieben habe, kommt es bei den scheinbar kostenlosen Apps (wir zahlen mit unseren Daten) von Google, Microsoft und Co. nach einer Phase der Gewöhnung zu einem Lock-in. Diese Pfadabhängigkeit wird dann genutzt, um die bisherigen Gewohnheiten einzuschränken oder kostenpflichtig zu stellen.
Google Maps sieht die Zeit gekommen, bisher verfügbare Informationen auf den gewohnten Karten zu reduzieren, wenn man sich nicht mit dem Google Konto angemeldet hat. Der Hintergrund wird in dem Artikel Google Maps ohne Anmeldung nur noch eingeschränkt nutzbar (Pakolski 2026, auf Golem.de) ausführlicher dargestellt.
„Google schränkt den vollen Funktionsumfang von Google Maps weiter ein, wenn Anwender sich nicht mit einem Google-Konto anmelden. Wird Google Maps etwa im Browser ohne Anmeldung genutzt, fehlen alle Rezensionen und Bilder zu Restaurants, Geschäften oder Touristenattraktionen“ (ebd.).
Was kann man machen? Sich ärgern, und sich in Zukunft immer mit dem Google Konto anmelden? Das ist der bequeme Weg, den man mit seinen Daten „bezahlt“. Alles andere bedeutet einen Aufwand (Switching Costs), ja. Genau das ist das Kalkül von Google (und anderen).
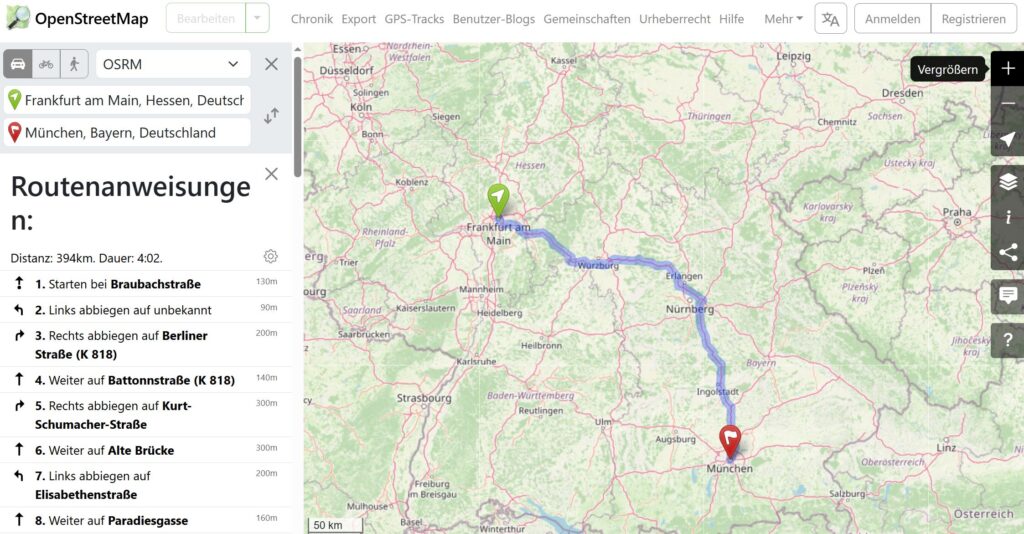
Es gibt allerdings auch die Möglichkeit, sich von solchen Anwendungen nach und nach zu emanzipieren, und digital souveräner zu werden. Bei dem Beispiel Google Maps gibt es die Open Source Alternative OpenStreetMap (OSM). Folgende Informationen sind bei OSM-About zu finden:
OpenStreetMap stellt Kartendaten für tausende von Webseiten, Apps und andere Geräte zur Verfügung.
OpenStreetMap legt Wert auf lokales Wissen. Autoren benutzen Luftbilder, GPS-Geräte und Feldkarten zur Verifizierung, sodass OSM korrekt und aktuell ist.
Ja, OpenStreetMap ist gewöhnungsbedürftig, doch sollte jeder abwägen, ob er aus Bequemlichkeit kurzfristig eine digitale Abhängigkeit, oder eher mittelfristig eine Digitale Souveränität möchte.
Weiterhin wurde Open EuroLLM veröffentlicht, ein „Large language Modelmade in Europebuilt to support allofficial 24 EU languages„. Die generierten Modelle sind Multimodal, Open Source, High Performance und eben Multilingual.
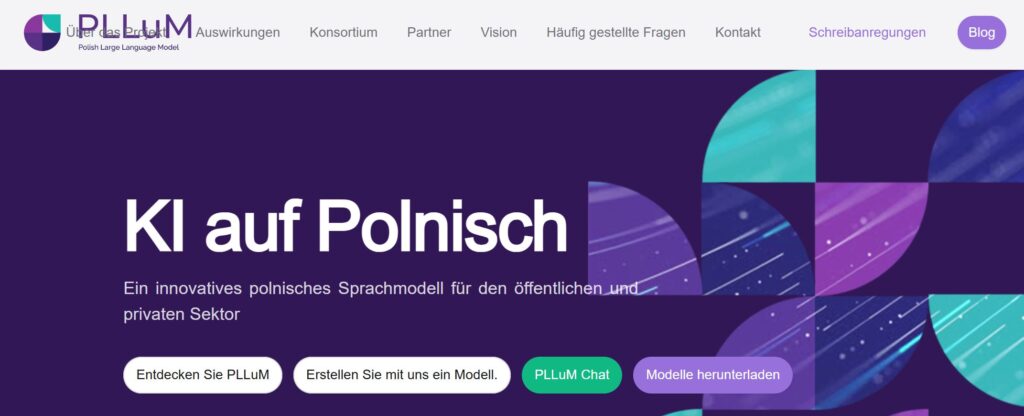
Zusätzlich zur europäischen Ebene gibt es allerdings auch immer mehr spezielle, länderspezifische Large Language Models (LLMs), wie das in 2025 veröffentlichte PLLuM ((Polish Large Language Model). Ich möchte an dieser Stelle drei wichtige Statements wiedergeben, die auf der Website zu finden sind:
Polnische Sprachunterstützung Ein wichtiges Element dieses Projekts ist die Entwicklung eines umfassenden und vielfältigen Datensatzes, der die Komplexität der polnischen Sprache widerspiegelt.
Die polnische Sprachunterstützung geht darauf ein, dass die üblichen proprietären LLM überwiegend in englischer (chinesischer) Sprache trainiert wurden, und dann entsprechende Übersetzungen liefern. Diese sind für den Alltagsgebrauch durchaus nützlich, doch wenn es um die kulturellen, kontextspezifischen Nuancen einer Sprache geht, reichen diese großen KI-Modelle der Tech-Konzerne nicht aus.
Das PLLuM-Modell setzt auf Offenheit, Transparenz und einfache Bedienung. Es versteht sich daher von selbst, dass die Modelle bei Huggingface zur Verfügung stehen und genutzt werden können. Probieren Sie den Chat einfach einmal aus:
Sicherheit und Ethik Wir stellen sicher, dass unser Modell sicher und frei von schädlichen und falschen Inhalten ist, was für seinen Einsatz in der öffentlichen Verwaltung von entscheidender Bedeutung ist.
Nicht zuletzt sind Sicherheit und Ethik wichtige Eckpunkte für das polnische Modell. Es unterscheidet sich dadurch von den bekannten großen KI-Modellen der Tech-Konzerne. Siehe dazu auch Künstliche Intelligenz: Würden Sie aus diesem Glas trinken?
Interessant ist auch, dass auf der PLLuM-Website darauf hingewiesen wird, dass man durch diese KI-Modelle auch Innovationen fördern möchte. Wieder ein direkter Bezug zwischen Open Source AI und Innovationen.
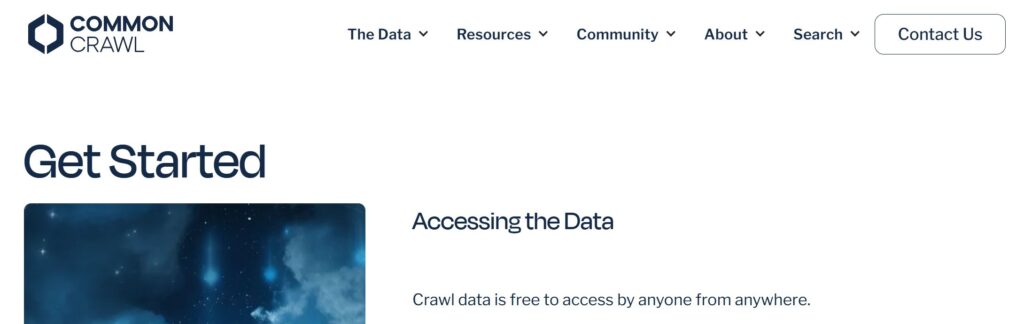
Large Language Models (LLMs) benötigen eine Unmenge an Daten. Bei den Closed Source KI-Modellen von OpenAI, Meta, etc. ist manchmal nicht so klar (Black Box), woher diese ihre Trainingsdaten nehmen. Eine Quelle scheint Common Crawl zu sein.
„Common Crawl maintains a free, open repository of web crawl data that can be used by anyone. The Common Crawl corpus contains petabytes of data, regularly collected since 2008“ (ebd.)
Die Daten werden von Amazon gehostet, können allerdings auch ohne Amazon-Konto genutzt werden. Eine Datensammlung, die für jeden frei nutzbar und transparent ist, und sogar rechtlichen und Datenschutz-Anforderungen genügt, wäre schon toll.
Es ist also Vorsicht geboten, wenn man Common Crawl nutzen möchte. Dennoch kann diese Entwicklung interessant für diejenigen sein, die ihr eigenes, auf den Werten von Open Source AI basierendes KI-Modell nutzen wollen. Siehe dazu auch